JVM 中的StringTable 详解JVM 中的StringTable
萌新J 人气:0是什么
字符串常量池是 JVM中的一个重要结构,用于存储JVM运行时产生的字符串。在JDK7之前在方法区中,存储的是字符串常量。而字符串常量池在 JDK7开始移入堆中,随之而来的是除了存储字符串常量外,还可以存储字符串引用(因为在堆中,引用堆中的字符串常量很方便,所以可以存储引用)。这使得很多字符串的操作在 JDK7中和在之前的版本中执行是不同的结果。这也是为什么字符串相关的问题是如此具有迷惑性的原因之一。
底层
String:在 JDK9之前,String底层是使用 char数组来存储字符串数据的,而在 JDK9开始,使用 byte数组+编码来代替 char数组,这是为了节省空间,因为不同编码的数据占空间不一样,很多单位数据只需要一个 byte(8字节) 就可以存储,而使用 char(16字节)就会浪费多余的空间。
字符串常量池:底层使用 HashTable来存储字符串,在 JDK6 HashTable的数组长度是1006,JDK7开始变成了 60013,这是为了避免存储字符串过多导致链表长度过长从而查询效率降低。可以使用参数 -XX:StringTableSize=来设置 StringTable数组的长度。
常见问题字符串相加
1、对于字符串常量相加,编译器会优化成直接相加。
如 String ss = "a" + "b",在编译器的优化下,实际上只会创建一个 "ab" 字符串。
而 final String s1 = "a"; String s2 = s1+"b",除了创建字符串 "a"外,只会创建 "ab"。
操作相关字符串如下:

可以看到只对字符串 "a"、"ab"进行了入池操作(ldc)
2、对于包含字符串变量的相加,不会在字符串常量池中创建对应的字符串。
如 String s1 = "a"; String s2 = s1 + "b",执行完后字符串常量池中只会包含 "a"、"b" 字符串。
对于 s1 + "b",下面是其字节码操作
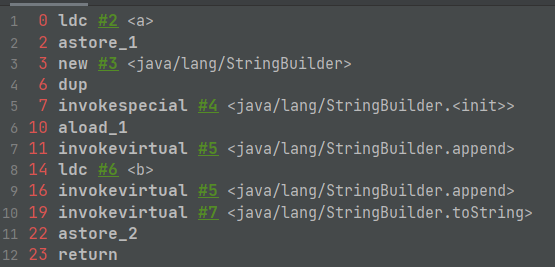
可以看到,相加操作实际上是调用 StringBuilder的append方法进行字符串拼接,然后调用它的 toString方法获取返回值保存输出,期间并没有入池操作(ldc)。
由此得出的优化建议:因为每次执行一次包含非常量的字符串相加时,都进行了一次 StringBuilder对象的创建,所以如果需要多次连接,可以直接创建 StringBuilder对象,使用一个 StringBuilder对象进行字符串拼接,避免创建多个对象降低效率。
对象创建数量
对象,包括 new的对象以及字符串对象。
1、对于String ss = new String ("ab"),这个过程首先会在会在字符串常量池中创建一个 "ab"字符串常量,然后再在堆上创建一个 new String()的对象,在这个对象中会保存常量池中 "ab"的地址信息,最后在栈上创建一个局部变量 ss ,保存堆中创建的对象地址。所以全程创建了堆中的一个对象和字符串常量池中的一个对象。
2、new String("a") + new String("b")。严格来看,创建了六个对象。
首先new String("a")和 new String("b") ,分为创建了两个对象。两者相加时,会创建一个 StringBuilder对象,而在 StringBuilder.toString()方法中,也会创建一个 String对象

3、String s1 = "a", String s2 = "b", String s3 = "a" + "b" + s1 + "c" + s2;对应的字节码如下:

字符串常量池中会有四个字符串对象,分别是 "a"、"b"、"ab"、"c"。在开始因为 s1、s2的赋值,会将 "a"、"b"分别加入字符串常量池,然后执行第三步,运行顺序是从左到右,首先执行 "a" + "b" ,因为两个都是常量,所以会因为编译器的优化直接返回 "ab",并且因为计算的两个参数都是常量,所以直接加入字符串常量池,随后因为与变量 s1相加,所以调用 StringBuilder的append方法,得到的结果保存到局部变量表中,所以引入常量 "c",因为是常量,所以还是会引入字符串常量池,然后与前面拼接得到的结果再次拼接,最后再与变量 s2相加,因为不是常量所以还是不会将结果加入字符串常量池。
除此之外,还需要注意,上面三种情况是在初始情况下,也就是字符串常量池中没有要加入的字符串时的场景,如果字符串常量池中预先就包含要加入的字符串,那么就会直接将常量池中的对应的字符串地址返回给调用方。比如 String s1 = "a",在常量池中没有 "a"时,创建的对象是 1个,而如果常量池中已经存在,那么就会将其地址直接返回赋给 s1。那么创建的对象就是 0个了。
intern()与字符串相等判断
intern()方法是 String类的一个native方法,作用是尝试将调用这个方法的字符串对象加入字符串常量池中,然后返回常量池中存储的值。在开头说过,在 JDK7开始字符串常量池可以存储字符串引用,导致字符串操作的过程可能会之前不一样,从而得到不同的结果。
intern()方法的执行:
1.6及之前:尝试将当前字符串常量加入常量池,如果常量池存在就返回地址值;如果不存在就先加入常量池,然后再返回加入位置的地址值。
1.7开始:尝试将当前字符串常量加入常量池,如果存在就将返回地址值;如果不存在就存入当前 String 字符串的地址值。
下面以一个例子来解释一下,在JDK7和JDK7之前下面代码执行分别是什么结果。
@Test
public void test1(){
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
先说结论:
JDK7之前: false、false。
JDK7及之后:false、true。
原因:
1、首先先看上面 3------6行的,首先,第三行会在字符串常量池中添加 "1" ,然后在堆中创建一个对象,保存 "1"在常量池中的地址,再在局部变量表中添加一个 s保存堆中对象的地址。随后执行第四行,此时 s指向的字符串已经在常量池中了,所以这一步无效,第五行因为常量池已经存在 "1" ,所以 JDK7或之前执行的逻辑是一样的,直接将 "1"在常量池中的地址返回给 s2。然后判断,s指向的是堆中的对象,而 s2指向的是常量池中的字符串常量,所以无论是 JDK7还是之前的都是 false。
2、然后再看下面 9-----12行。因为前面已经在常量池中添加 "1",所以第9行会直接返回地址,然后执行添加操作,创建字符串 "11",此时并没有添加到常量池,然后执行第10行,因为常量池不存在 "11",所以 JDK7之前直接加入常量池,JDK7及以后则直接将 "11"的地址存入常量池,而 s3则不变,还是保存的是常量池外的那个 "11"的地址值。然后执行 11行,因为常量池已存在 "11",所以 s4就是返回 "11"的地址值,不同的是在 JDK7之前因为常量池保存的是 "11"常量,所以返回的是常量池中的地址值;而 JDK7 及以后常量池保存的是常量池外的 "11"的地址值,所以返回的是池外的地址值。所以最后判断在 JDK7之前是 false,而在 JDK7开始是 true。
加载全部内容