JVM堆溢出抽丝剥茧定位 记一次公司JVM堆溢出抽丝剥茧定位的过程解析
菠菜东 人气:0背景
公司线上有个tomcat服务,里面合并部署了大概8个微服务,之所以没有像其他微服务那样单独部署,其目的是为了节约服务器资源,况且这8个服务是属于边缘服务,并发不高,就算宕机也不会影响核心业务。
因为并发不高,所以线上一共部署了2个tomcat进行负载均衡。
这个tomcat刚上生产线,运行挺平稳。大概过了大概1天后,运维同事反映2个tomcat节点均挂了。无法接受新的请求了。CPU飙升到100%。
排查过程一
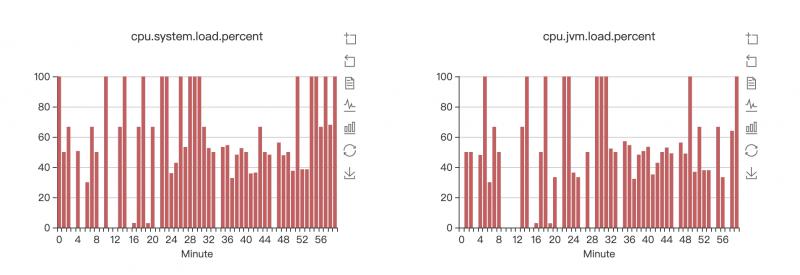
接手这个问题后。首先大致看了下当时的JVM监控。
CPU的确居高不下
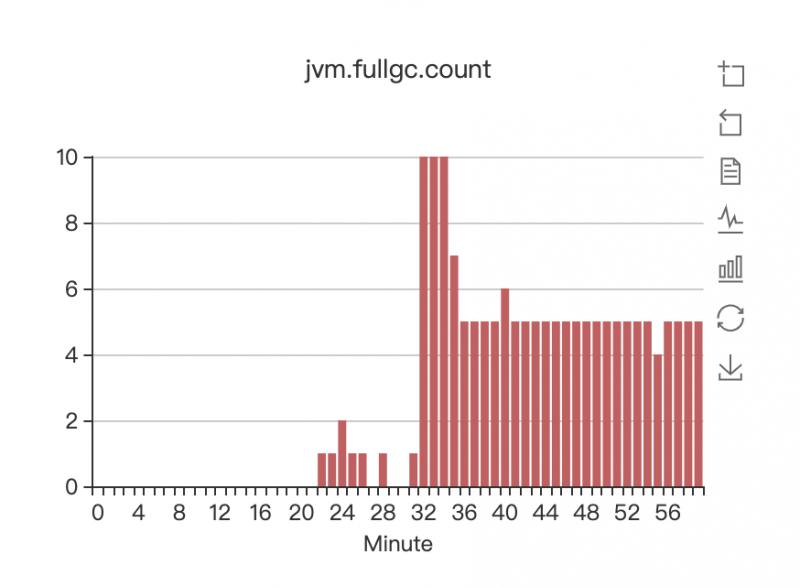
FULL GC从大概这个小时的22分开始,就开始频繁的进行FULL GC,一分钟最高能进行10次FULL GC
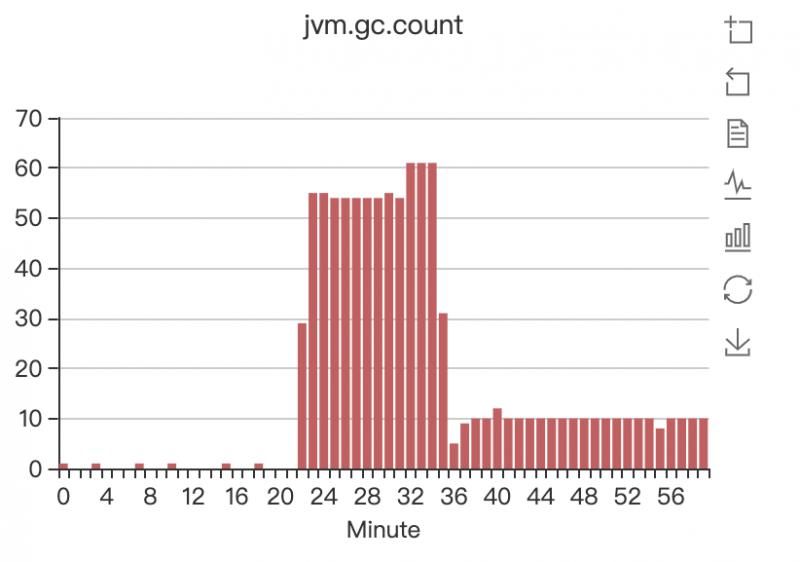
minor GC每分钟竟然接近60次,相当于每秒钟都有minor GC
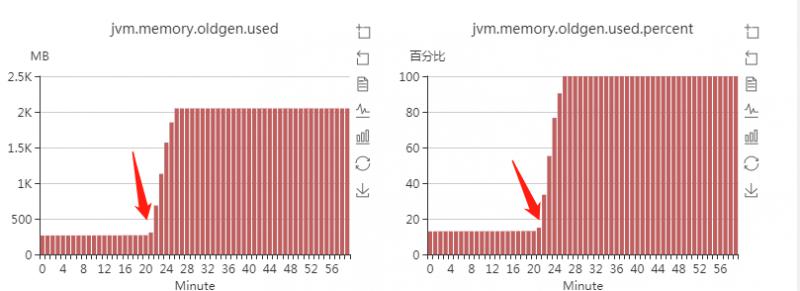
从老年代的使用情况也反应了这一点
随机对线上应用分析了线程的cpu占用情况,用top -H -p pid命令
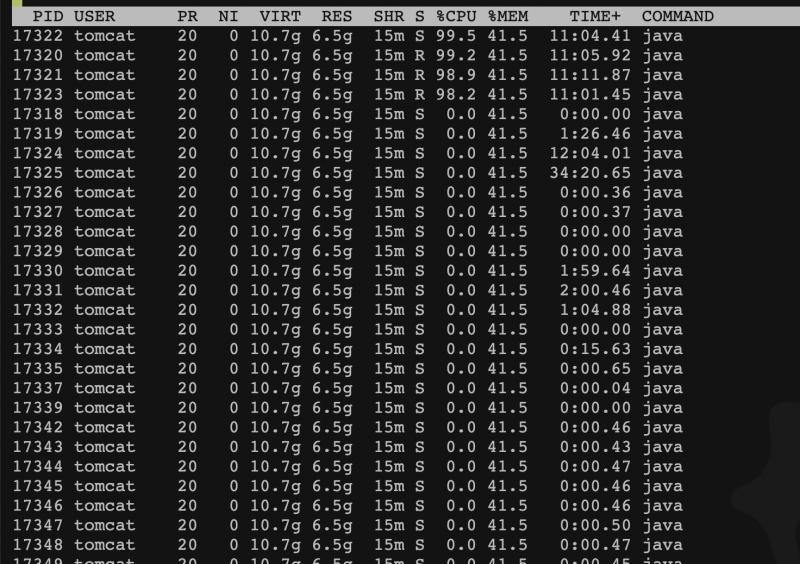
可以看到前面4条线程,都占用了大量的CPU资源。随即进行了jstack,把线程栈信息拉下来,用前面4条线程的ID转换16进制后进行搜索。发现并没有找到相应的线程。所以判断为不是应用线程导致的。
第一个结论
通过对当时JVM的的监控情况,可以发现。这个小时的22分之前,系统 一直保持着一个比较稳定的运行状态,堆的使用率不高,但是22分之后,年轻代大量的minor gc后,老年代在几分钟之内被快速的填满。导致了FULL GC。同时FULL GC不停的发生,导致了大量的STW,CPU被FULL GC线程占据,出现CPU飙高,应用线程由于STW再加上CPU过高,大量线程被阻塞。同时新的请求又不停的进来,最终tomcat的线程池被占满,再也无法响应新的请求了。这个雪球终于还是滚大了。
分析完了案发现场。要解决的问题变成了:
是什么原因导致老年代被快速的填满?
拉了下当时的JVM参数
-Djava.awt.headless=true -Dfile.encoding=UTF-8 -server -Xms2048m -Xmx4096m -Xmn2048m -Xss512k -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+DisableExx
plicitGC -XX:MaxTenuringThreshold=5 -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSInitiatingOccupancyOnly -XX:+UseCMSCompactAtFullCollection
-XX:+PrintGCDetails -Xloggc:/data/logs/gc.log
总共4个G的堆,年轻代单独给了2个G,按照比率算,JVM内存各个区的分配情况如下:
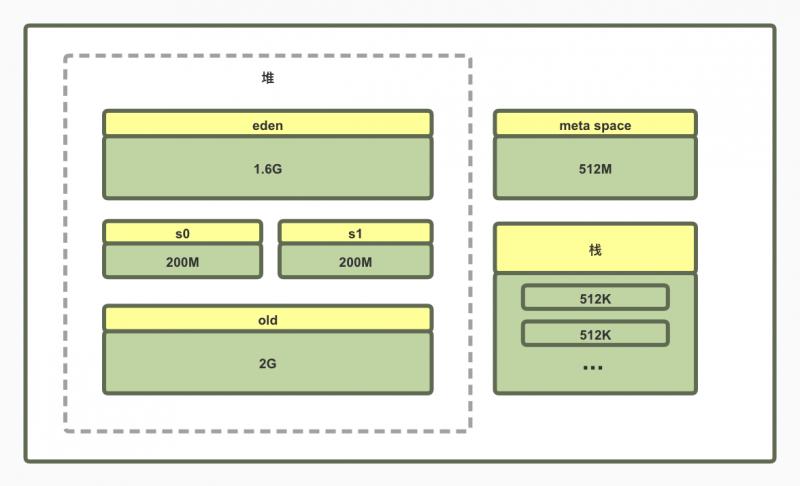
所以开始怀疑是JVM参数设置的有问题导致的老年代被快速的占满。
但是其实这参数已经是之前优化后的结果了,eden区设置的挺大,大部分我们的方法产生的对象都是朝生夕死的对象,应该大部分都在年轻代会清理了。存活的对象才会进入survivor区。到达年龄或者触发了进入老年代的条件后才会进入老年代。基本上老年代里的对象大部分应该是一直存活的对象。比如static修饰的对象啊,一直被引用的 缓存啊,spring容器中的bean等等。
我看了下垃圾回收进入老年代的触发条件后(关注公众号后回复“JVM”获取JVM内存分配和回收机制的资料),发现这个场景应该是属于大对象直接进老年代的这种,也就是说年轻代进行minor GC后,存活的对象足够大,不足以在survivor区域放下了,就直接进入老年代了。
但是一次minor GC应该超过90%的对象都是无引用对象,只有少部分的对象才是存活的。而且这些个服务的并发一直不高,为什么一次minor GC后有那么大量的数据会存活呢。
随即看了下当时的jmap -histo 命令产生的文件
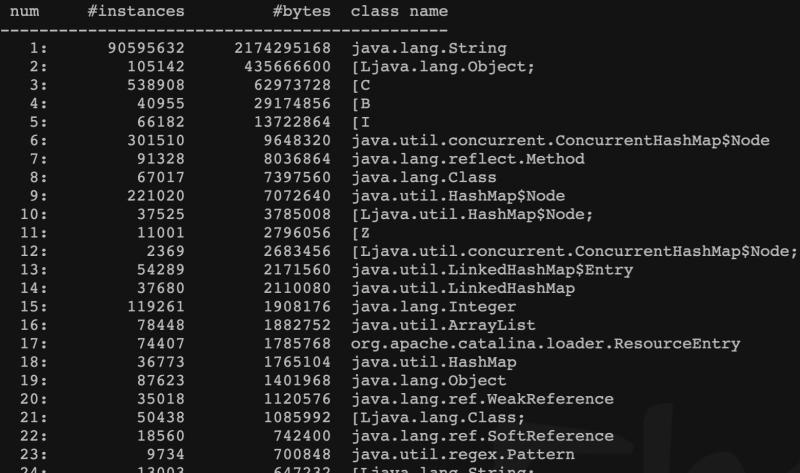
发现String这个这个对象的示例竟然有9000多w个,占用堆超过2G。这肯定有问题。但是tomcat里有8个应用 ,不可能通过分析代码来定位到。还是要从JVM入手来反推。
第二次结论
程序并发不高,但是在几分钟之内,在eden区产生了大量的对象,并且这些对象无法被minor GC回收 ,由于太大,触发了大对象直接进老年代机制,老年代会迅速填满,导致FULL GC,和后面CPU的飙升,从而导致tomcat的宕机。
基本判断是,JVM参数应该没有问题,很可能问题出在应用本身不断产生无法被回收的对象上面。但是我暂时定位不到具体的代码位置。
排查过程二
第二天,又看了下当时的JVM监控,发现有这么一个监控数据当时漏看了

这是FULL GC之后,老年代的使用率。可以看到。FULL GC后,老年代依然占据80%多的空间。full gc就根本清理不掉老年代的对象。这说明,老年代里的这些对象都是被程序引用着的。所以清理不掉。但是平稳的时候,老年代一直维持着大概300M的堆。从这个小时的22分开始,之后就狂飙到接近2G。这肯定不正常。更加印证了我前面一个观点。这是因为应用程序产生的无法回收的对象导致的。
但是当时我并没有dump下来jvm的堆。所以只能等再次重现问题。
终于,在晚上9点多,这个问题又重现了,熟悉的配方,熟悉的味道。
直接jmap -dump,经过漫长的等待,产生了4.2G的一个堆快照文件dump.hprof,经过压缩,得到一个466M的tar.gz文件
然后download到本地,解压。
运行堆分析工具JProfile,装载这个dump.hprof文件。
然后查看堆当时的所有类占比大小的信息

发现导致堆溢出,就是这个String对象,和之前Jmap得出的结果一样,超过了2个G,并且无法被回收
随即看大对象视图,发现这些个String对象都是被java.util.ArrayList引用着的,也就是有一个ArrayList里,引用了超过2G的对象
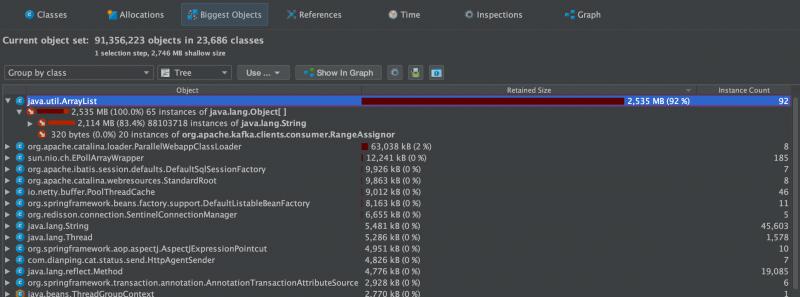
然后查看引用的关系图,往上溯源,源头终于显形:
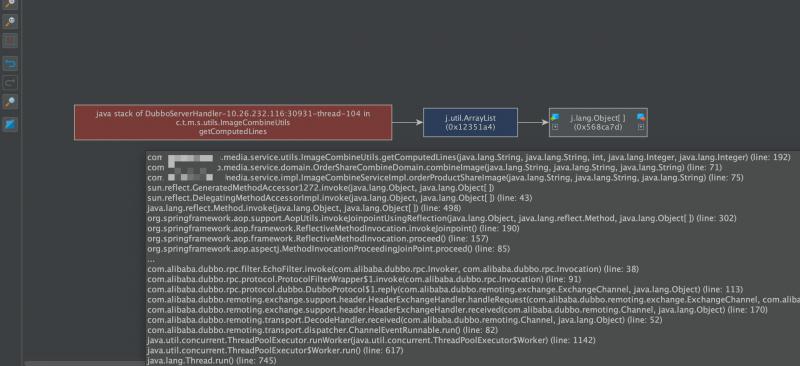
这个ArrayList是被一个线程栈引用着,而这个线程栈信息里面,可以直接定位到相应的服务,相应的类。具体服务是Media这个微服务。
看来已经要逼近真相了!
第三次结论
本次大量频繁的FULL GC是因为应用程序产生了大量无法被回收的数据,最终进入老年代,最终把老年代撑满了导致的。具体的定位通过JVM的dump文件已经分析出,指向了Media这个服务的ImageCombineUtils.getComputedLines这个方法,是什么会产生尚不知道,需要具体分析代码。
最后
得知了具体的代码位置, 直接进去看。经过小伙伴提醒,发现这个代码有一个问题。
这段代码为一个拆词方法,具体代码就不贴了,里面有一个循环,每一次循环会往一个ArrayList里加一个String对象,在循环的某一个阶段,会重置循环计数器i,在普通的参数下并没有问题。但是某些特定的条件下。就会不停的重置循环计数器i,导致一个死循环。
以下是模拟出来的结果,可以看到,才运行了一会,这个ArrayList就产生了322w个对象,且大部分Stirng对象都是空值。
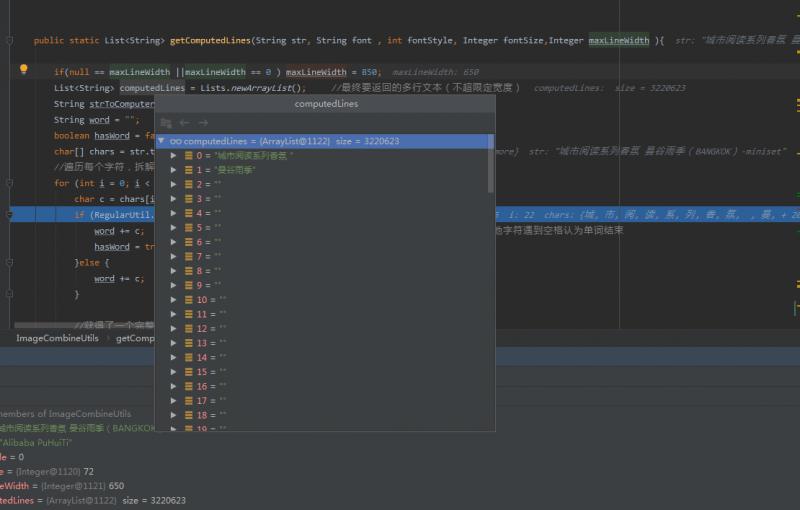
至此,水落石出。
最终结论
因为Media这个微服务的程序在某一些特殊场景下的一段程序导致了死循环,产生了一个超大的ArrayList。导致了年轻代的快速被填满,然后触发了大对象直接进老年代的机制,直接往老年代里面放。老年代被放满之后。触发FULL GC。但是这些ArrayList被GC ROOT根引用着,无法回收。导致回收不掉。老年代依旧满的,随机马上又触发FULL GC。同时因为老年代无法被回收,导致minor GC也没法清理,不停的进行minor GC。大量GC导致STW和CPU飙升,导致应用线程卡顿,阻塞,直至最后整个服务无法接受请求。
加载全部内容