JDK8并行流串行流 JDK8并行流及串行流区别原理详解
像风一样无影无起 人气:0由于处理器核心的增长及较低的硬件成本允许低成本的集群系统,致使如今并行编程无处不在,并行编程似乎是下一个大事件。
Java 8 针对这一事实提供了新的 stream API 及简化了创建并行集合和数组的代码。让我们看一下它是怎么工作的。
假设 myList 是 List<Integer> 类型的,其中包含 500,000 个Integer值。在Java 8 之前的时代中,对这些整数求和的方法是使用 for 循环完成的。
for( int i : myList){
result += i;
}
从 Java 8 开始,我们就可以使用stream完成同样的循环:
myList.stream().sum();
将此代码改为并行处理非常简单,仅需要使用 parallelStream() 代替 stream() 或 parallel()搭配stream使用:

mylist.stream().parallelStream().sum();
这样就可以成功的变为并行程序,所以将一个计算扩展到线程和CPU内核上并可用很容易就可以实现。但是我们都知道,多线程和并行处理的开销很大,所以重点是什么时候使用并行流,什么时候使用串行流才能获得更好的性能。
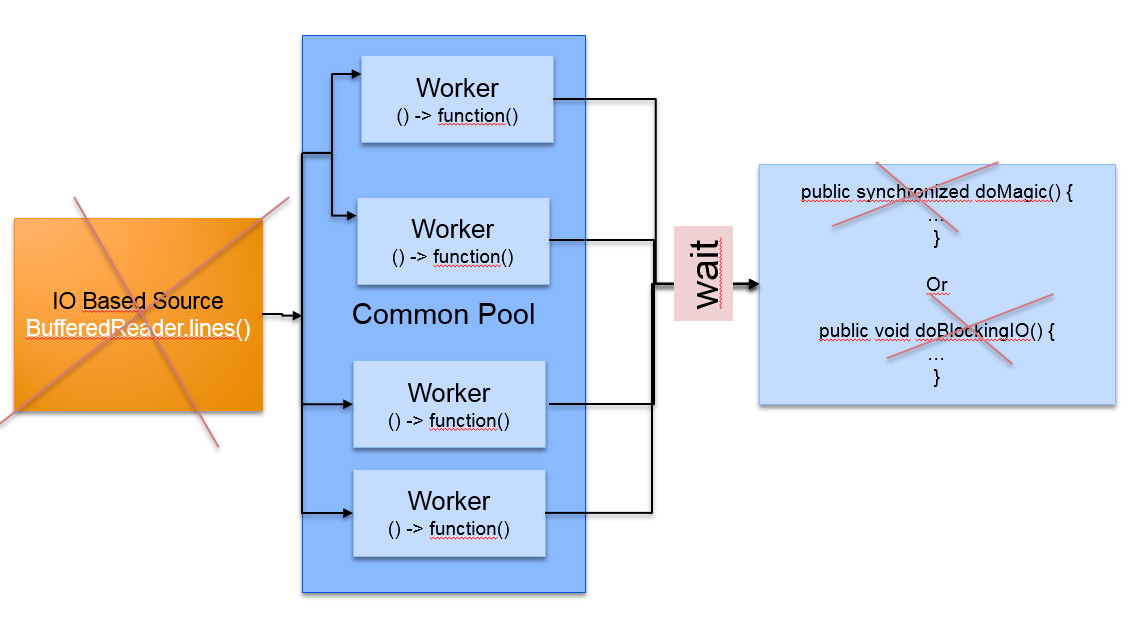
首先,让我们看看在幕后发生的事情。parallel stream 使用的是 Fork/Join 框架进行处理的,这意味着 stream 流的源会被拆分并移交给 fork/join 池中执行。
首先,我们找到了要考虑的第一点:并非所有的stream的源会像其它的stream的源一样可拆分。例如:ArrayList的内部实现是数组,由于可以通过计算出中间元素的索引来拆分,所以拆分这样的源会非常容易;假如使用LinkedList,则拆分数据会复杂的多:该实现必须遍历第一个条目中的所有元素,以便找到可以拆分的元素,所以LinkedList是并行流中性能差的例子。

这是我们可以保留的关于并行流性能的第一个事实:
S : 源集合必须可以有效拆分
拆分集合、管理 Fork/Join 任务、对象创建及 GC 也是算法上的开销,当且仅当在CPU核心上可简单完成或者集合足够大时,才值得这样做。
一个错误的例子:求5个整数的最大值。
Intstream.rangeClosed(1,5).reduce(Math::max).getAsInt();
系统为fork/join准备和处理数据的开销非常大,以至于串行流在此场景中要快得多。Math.max 方法在这里的CPU开销并不是很高,而且数据元素很少。
举个例子,在编写象棋游戏的时候,对每个棋子移动的评估。每一个评估都可以并行执行,并且我们有大量可能的下一步移动。这种情形非常适合并行处理。
这是我们可以保留的关于并行流性能的第二个事实:
N * Q: 因子”元素数量” * “ 每个元素的运行成本” 应该很大
但这同样意味着当每个元素的操作成本更高的时候,集合可以更小。或当每个元素的操作不那么占用大量CPU时,我们需要一个包含许多元素的非常大的集合,以便并行流的使用的到回报。
这直接取决于我们可以保留的第三个事实
C :CPU核心数量 - 越多越好 > 必须有1个
由于管理开销,在单核计算机上的并行流始终比串行流的性能差。
越多越好:实际上,这句话并不是在所有情况下都正确。例如:集合太小且CPU核心启动时处于节能模式进而导致CPU无事可做。
能否使用并行流,对每个元素的功能(function)也有要求,这涉及到并行流能否按照预期工作:
要求该功能(function):
- 独立:每个元素的计算都不依赖或影响任何其他元素的计算
- 无干扰:功能(function)执行的时候不会修改基础的数据源
- 无状态
例:并行流中使用有状态lamdba方法的实例,来源自 Java JDK API
Set seen = Collection.synchronizedSet(new HashSet());
stream.parallel().map( e -> {
if(seen.add(e))
return 0;
else
return e;
})...
于是,这是我们可以保留的第四个事实:
F :每个元素必须独立
总结:

还有其他情况不应该并行化流吗?有。
我们要始终考虑每一个元素的功能(function)在做什么及它是否适合运行在并行代码中。当方法是调用一些同步方法,并行流可能会在同步方法上等待,进而导致并行流的性能并没有想象中高。
同样的,在调用BI/O操作时,由于数据是按照顺序读取的,以I/O源作为流,也会发生同样的问题。
加载全部内容