Mysql InnoDB锁 Mysql技术内幕之InnoDB锁的深入讲解
晴转阵雨 人气:0前言
自7月份换工作以来,期间一直在学习MySQL的相关知识,听了一些视频课,但是一直好奇那些讲师的知识是从哪里学习的。于是想着从书籍中找答案。毕竟一直
看视频也不是办法,不能形成自己的知识。于是想着看书汲取知识,看了几本MySQL的相关书籍,包括《深入浅出Mysql》《高性能Mysql》《Mysql技术内幕》,发现那些讲
师讲的内容确实都在书上有出现过,于是确信看书才是正确的汲取知识方式。本片主要记录了Mysql的锁机制的学习。
1.什么是锁
锁是计算机协调多个进程或线程并发访问某一资源的机制。在数据库中,除传统的计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供许多用户共享的资源。
如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。
相对其他数据库而言,MySQL 的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制。比如,MyISAM和MEMORY存储引擎采用的是表级锁(table-level
locking);BDB存储引擎采用的是页面锁(page-levellocking),但也支持表级锁;InnoDB存储引擎既支持行级锁(row-levellocking),也支持表级锁,但默认情况下是采用行级锁。
MySQL这3种锁的特性可大致归纳如下。
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
3种锁的使用角度:
- 表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web应用;
- 行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统。
- BDB的页面锁已经被InnoDB取代,不做讨论。
2.InnoDB存储引擎中的锁
2.1锁的类型
InnoDB存储引擎实现了如下两种标准的行级锁:
- 共享锁(S Lock),允许事务读一行数据。
- 排他锁(X Lock),允许事务删除或更新一行数据。
如果一个事务T1已经获得了行r的共享锁,那么另外的事务T2可以立即获得行r的共享锁,因为读取没有改变行r的数据,称这种情况
为锁兼容(Lock Compatible)。但若有其他的事务T3想获得行r的排他锁,则其必须等待事务T1、T2释放行r的共享锁——这种情况称为锁不兼容。
| X | S | |
|---|---|---|
| X | 不兼容 | 不兼容 |
| S | 不兼容 | 兼容 |
此外,InnoDB存储引擎支持多粒度锁定,这种锁定允许事务在行级上锁和表锁上的锁同时存在。为了支持在不同粒度上进行加锁操作,InnoDB存
储引擎支持一种额外的锁方式,称之为意向锁。意向锁是将锁定的对象分为多个层次,意向锁意味着事务希望在更细粒度上进行加锁。 InnoDB存
储引擎支持意向锁设计比较简练,其意向锁即为表级别的锁。设计目的主要是为了在一个事务中揭示下一行将被请求的锁类型。其支持两种意向锁:
- 意向共享锁(IS Lock),事务想要获得一张表中某几行的共享锁
- 意向排他锁(IX Lock),事务想要获得一张表中某几行的排他锁
2.2 一致性非锁定读
一致性的非锁定读(consistant nonlocking read)是指InnoDB存储引擎通过多版本控制(multi versioning)的方法来读取当前执行时间数据库中行的
数据。如果读取的行正在执行Delete或Update操作,这时读取操作不会因此去等待行上锁的释放。相反地,InnoDB存储引擎会去读取行的一个快照
版本。如下如所示。
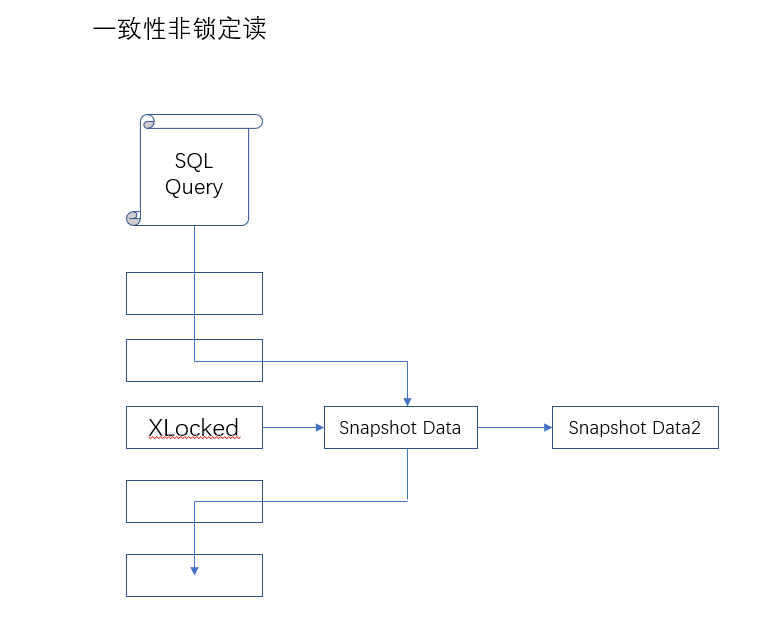
上图直观地展现了InnoDB存储引擎一致性的非锁定读。之所以称为非锁定读,因为不需要等待访问的行上X锁的释放。快照数据是指该行的之前版本
的数据,该实现是通过undo段来完成。而undo用来在事务中回滚数据,因此快照数据本身是没有额外的开销。此外,读取快照数据是不需要上锁的,
因为没有事务需要对历史的数据进行修改操作。
通过上图可以知道,快照数据其实就是当前行数据之前的历史版本,每行记录可能有多个版本,一般称这种技术为行多版本技术。由此带来的并发控制,
称之为多版本并发控制(Multi Version Concurrency Control, MVCC)。
在事务隔离级别READ COMMITTED和REPEATABLE READ下,InnoDB存储引擎使用非锁定的一致性读。然而,对于快照数据的定义却不相同。在READ
COMMITTED事务隔离级别下,对于快照数据,非一致性读总是读取被锁定行的最新一份快照数据。而在REPEATABLE READ事务隔离级别下,对于快照
数据,非一致性读总是读取事务开始时的行数据版本。如下表所示示例:
| 时间 | 会话A | 会话B |
|---|---|---|
| 1 | begin | |
| 2 | select * from t_user where id = 1; | |
| 3 | begin | |
| 4 | update t_user set id = 10 where id = 1; | |
| 5 | select * from t_user where id = 1; | |
| 6 | commit; | |
| 7 | select * from t_user where id = 1; | |
| 8 | commit; |
假设原本id = 1的记录是存在的,大家可以按上表时间顺序执行对应的会话,比较及验证2者的不同。
2.3 一致性锁定读
在默认配置下,在事务的隔离级别为REPEATABLE READ模式下,InnoDB存储引擎的select操作使用一致性非锁定读。但是在某些情况下,用户需要显示地
对数据库读取操作进行加锁以保证数据逻辑的一致性。而这要求数据库支持加锁语句,即使时对于select的只读操作。InnoDB存储引擎对于select语句支持两
种一致性的锁定读(locking read)操作:
- select ··· for update
- select ··· lock in share mode
select ··· for update对读取的行记录加一个X锁,其他事务不能对已锁定的行加上任何锁。select ··· lock in share mode对读取的行记录加一个S锁,其他事务可
以向被锁定的行加S锁,但是如果加X锁,则会被阻塞。
对于一致性非锁定读,即使读取的行已被执行了select ··· for update,也是可以进行读取的。此外,select ··· for update或者select ··· lock in share mode必须在
一个事务中,当事务提交了,锁也就释放了。因此在使用上述两种select锁定语句时,务必加上begin,start transaction或者set autocommit=0。
3 锁的算法
3.1行锁的3中算法
InnoDB存储引擎有3种行锁的算法,其分别是:
- Record Lock:单个行记录上的锁
- Gap Lock:间隙锁,锁定一个范围,但不包含记录本身
- Next-Key Lock:Gap Lock + Record Lock,锁定一个范围,并且锁定记录本身
Record Lock总是会去锁住主键索引记录,如果InnoDB存储引擎表在建立的时候没有设置任何一个主键或唯一非空索引,那么这时InnoDB存储引擎会使用隐式的
主键来进行锁定。
Next-Key Lock是结合了Gap Lock+Record Lock的一种锁定算法,在Next-Key Lock算法下,InnoDB对于行的查询都是采用这种锁定算法。假如一个索引有10,11
,13和20这4个值,那么该索引可能被Next-Key Locking的区间为:
(-无穷,10] ,(10,11], (11,13], (13,20], (20,+无穷)
采用Next-Key Lock的锁定技术称为Next-Key Locking。其设计的目的是为了解决幻读问题。而利用这种锁定技术,锁定的不是单个值,而是一个范围。 然而,
当查询的索引含有唯一属性时,InnoDB存储引擎会对Next-Key Lock进行优化将其降级为Record Lock,即仅锁住索引本身,而不是范围。下面演示一个例子。
mysql> create table t (a int primary key); Query OK, 0 rows affected (0.01 sec) mysql> insert into t select 1; Query OK, 1 row affected (0.00 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> insert into t select 2; Query OK, 1 row affected (0.00 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> insert into t select 5; Query OK, 1 row affected (0.01 sec) Records: 1 Duplicates: 0 Warnings: 0
接着按下表时间顺序执行操作。
| 时间 | 会话A | 会话B |
|---|---|---|
| 1 | begin; | |
| 2 | select * from t where a = 5 for update; | |
| 3 | begin; | |
| 4 | insert into t select 4; | |
| 5 | commit; #成功,不需要等待 | |
| 6 | commit; |
表t共有1,2,5三个值。在上面的例子中,在会话A中首先对a=5进行X锁定。而由于a是主键且唯一,因此锁定的仅是5这个值,而不是(2,5)这个范围,这样在会话
B中插入值4而不会阻塞,可以立即插入并返回。即锁定由Next-Key Lock算法降级为了Record Lock,从而提高应用的并发性。
如上,Next-Key Lock降级为Record Lock仅在查询的列是唯一索引的情况下。若是辅助索引,则情况会完全不同。同样,首先创建测试表z进行测试:
mysql> create table z (a int ,b int ,primary key(a), key(b)); mysql> insert into z select 1,1; mysql> insert into z select 3,1; mysql> insert into z select 5,3; mysql> insert into z select 7,6; mysql> insert into z select 10,8;
表z的列b是辅助索引,若在会话A中执行下面的SQL语句:
mysql> select * from z where b = 3 for update;
很明显,这时SQL语句通过索引列b进行查询,因此其使用传统的Next-Key Locking技术加锁,并且由于有两个索引,其需要分别进行锁定。对于聚集索引,其仅对列
a等于5的索引加上Record Lock。而对于辅助索引,其加上的是Next-Key Lock,锁定的范围是(1,3),特别需要注意的是,InnoDB存储引擎还会对辅助索引下一个
键值加上gap lock,即还有一个辅助索引范围为(3,6)的锁。因此,若在新会话B中运行下面的SQL语句,都会被阻塞:
mysql> select * from z where a = 5 lock in share mode; mysql> insert into z select 4,2; mysql> insert into z select 6,5;
第一个SQL语句不能执行,因为在会话A中执行的SQL语句已经对聚集索引中列a=5的值加上X锁,因此执行会被阻塞。第二个SQL语句,主键插入4,没有问题,但是插入
的辅助索引值2在锁定的范围(1,3)中,因此执行同样会被阻塞。第三个SQL语句,插入的主键6没有被锁定,5也不在范围(1,3)之间。但插入的值5在另一个锁定的
范围(3,6)中,故同样需要等待。而下面的SQL语句,不会被阻塞,可以立即执行:
mysql> insert into z select 8,6; mysql> insert into z select 2,0; mysql> insert into z select 6,7;
从上面的例子可以看到,Gap Lock的作用是为了阻止多个事务将记录插入到同一个范围内,而这会导致幻读问题的产生。假如在上面的例子中,会话A中用户已经锁定了
b=3的记录。若此时没有Gap Lock锁定(3,6),那么用户可以插入索引b列为3的记录,这会导致会话A中的用户再次执行同样查询时会返回不同的记录,即幻读。
这里主要探究的是InnoDB存储引擎锁表的机制,至少自己明白了Mysql的行锁机制,不知道读者是否有疑问,欢迎留言。下次会记录关于Mysql事务特性及其内部的实现机制,
包括mysql的内部架构,InnoDB buffer Pool,redo log, undo log等具体的详解,目前只是对知识过了一遍,但还未总结。
总结
加载全部内容