CNN可视化技术总结(一)--特征图可视化
仿佛若有光157 人气:0导言:
在CV很多方向所谓改进模型,改进网络,都是在按照人的主观思想在改进,常常在说CNN的本质是提取特征,但并不知道它提取了什么特征,哪些区域对于识别真正起作用,也不知道网络是根据什么得出了分类结果。
如在上次解读的一篇论文《Feature Pyramid Transformer》(简称FPT)中,作者提出背景信息对于识别目标有重要作用,因为电脑肯定是在桌上,而不是水里,大街上,背景中的键盘鼠标的存在也能辅助区分电脑与电视机,因此作者提出要使用特征金字塔融合背景信息。从人的主观判断来看,这点非常合理。但对于神经网络来说,FPT真的有融合背景信息,而普通CNN网络没有融合背景信息?又或者说,一般而言,除了提出的新模型,还会加上主观设计的各种tricks,确定最后是因为融合了背景信息而精度提高了,还是说背景确实融合了,但实际上对精度没有影响,而是各种tricks起了作用?这一切并不确定,因为并不确定CNN到底学到了什么。
解决这个问题的办法有很多,一个是想办法看看CNN内部学到了什么,一个是控制变量法。提到这个控制变量法,在某一篇论文中(我对不起我的读者,论文累积量太大,忘记是哪一篇,只记得该论文的一些新颖之处),在设计了一个新的模型后,通过改变卷积层的某些通道,来看最后模型的精度的变化,从而确定哪些通道对这个模型是真正起作用的,而哪些是冗余的。按照这个思路,我们或许可以在数据预处理时,故意裁剪掉人主观认为有用的背景信息,例如裁剪辅助识别电脑的桌子,键盘鼠标,重新训练FPT,从而看最终精度有没有影响。很明显,这种方法理论上是可行的,但实际上工作量巨大,不现实。而CNN可视化是值得考虑的方法。
除了上面提到的一点,CNN的作用还有哪些?
在少数提出新模型或新methods的论文中,往往会给出这个模型的一些可视化图来证明这个模型或这个新methods对于任务的作用,这一点不仅能增加新模型或新methods可信度,也能起到增加工作量,增加论文字数的作用,如研究者想到一个method,一两页就介绍加推理加证明完了,效果明显,但作为一篇论文却字数太少,工作量不够多,就可以考虑可视化使用了这个methods的网络与没有使用这个methods的网络,进行对比,分析分析,就可以变成一篇完整的论文了。此外,CNN可视化还有一个作用,根据可视化某个网络的结果分析其不足之处,从而提出新的改进方法。例如:ZFNet正是对AlexNet进行可视化后改进而来,获得了ILSVRC2014的冠军。
CNN可视化方法
一、特征图可视化。特征图可视化有两类方法,一类是直接将某一层的feature map映射到0-255的范围,变成图像,但这样。另一类是使用一个反卷积网络(反卷积、反池化)将feature map变成图像,从而达到可视化feature map的目的。
二、卷积核可视化。
三、类激活可视化。这个主要用于确定图像哪些区域对识别某个类起主要作用。如常见的热力图(Heat Map),在识别猫时,热力图可直观看出图像中每个区域对识别猫的作用大小。这个目前主要用的方法有CAM系列(CAM、Grad-CAM、Grad-CAM++)。
四、一些技术工具。通过一些研究人员开源出来的工具可视化CNN模型某一层。
CNN技术总结将按照这四个方法,分成四个部分总结CNN可视化技术。对于以后出现新的技术,或者补充,将更新在公众号CV技术指南的技术总结部分。在本文,主要介绍第一类方法,特征图可视化。
直接可视化
单通道特征图可视化,由于feature map并不是在0-255范围,因此需要将其进行归一化。以pytorch为例,使用torchvision.utils.make_grid()函数实现归一化
def make_grid(tensor, nrow=8, padding=2,
normalize=True, range=None,
scale_each=False,pad_value=0):
多通道特征图的显示,即对某一层所有通道上的特征图融合显示,在使用make_grid函数后,pytorch环境下可使用tensorboardX下的SummerWriterh中的add_image函数。
本部分内容参考链接:https://zhuanlan.zhihu.com/p/607539
反卷积网络deconvnet
feature map可视化的另一种方式是通过反卷积网络从feature map变成图像。反卷积网络在论文《Visualizing and Understanding Convolutional Networks》中提出,论文中提出图像像素经过神经网络映射到特征空间,而反卷积网络可以将feature map映射回像素空间。
如下图所示,反卷积网络的用途是对一个训练好的神经网络中任意一层feature map经过反卷积网络后重构出像素空间,主要操作是反池化unpooling、修正rectify、滤波filter,换句话说就是反池化,反激活,反卷积。
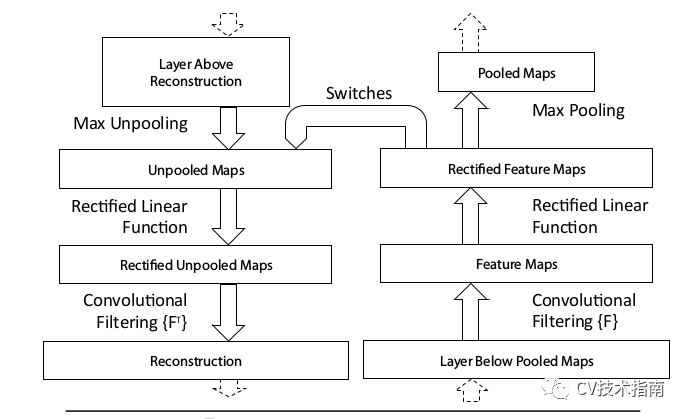

由于不可能获取标签数据,因此反卷积网络是一个无监督的,不具备学习能力的,就像一个训练好的网络的检测器,或者说是一个复杂的映射函数。
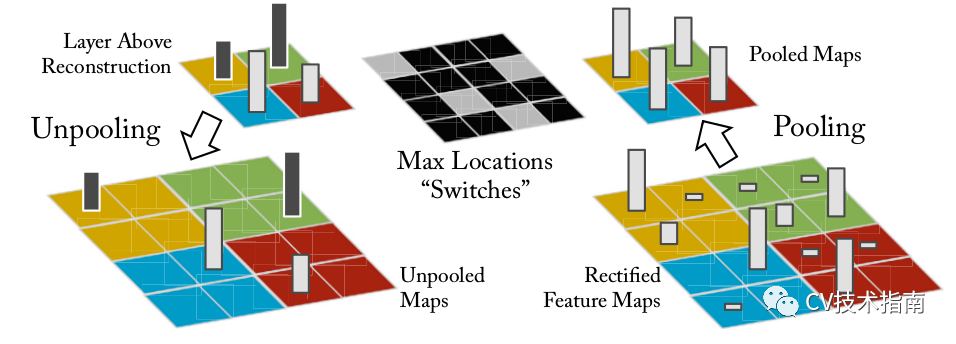
反池化Unpooling
在上一篇文章《池化技术总结》中提到最大池化会记录最大值的坐标,在上图中就是switches,而反池化就只需要将最大值放到原位置,而其他位置的值并不知道,直接置零。如下图所示。
修正Rectification
CNN使用ReLU确保feature map上的值都是正的,因此在反卷积中也使用ReLU。这里所谓Rectification其实就是让unpooling后的值都是正的,换句话说就是使用ReLU。
Filtering
Filtering指的是反卷积,具体操作就是使用原网络的卷积核的转置作为卷积核,对Rectification后的输出进行卷积。
注:在以上重构过程中没有使用对比归一化操作。
反卷积网络特征可视化结果

导向反向传播
在论文《Striving for Simplicity:The All Convolutional Net》中提出使用导向反向传播(Guided- backpropagation),导向反向传播与反卷积网络的区别在于对ReLU的处理方式。在反卷积网络中使用ReLU处理梯度,只回传梯度大于0的位置,而在普通反向传播中只回传feature map中大于0的位置,在导向反向传播中结合这两者,只回传输入和梯度都大于0的位置,这相当于在普通反向传播的基础上增加了来自更高层的额外的指导信号,这阻止了负梯度的反传流动,梯度小于0的神经元降低了正对应更高层单元中我们想要可视化的区域的激活值。

使用导向反向传播与反卷积网络的效果对比

明显使用导向反向传播比反卷积网络效果更好。
总结:分析反卷积网络的对各层feature map可视化的结果可知,CNN中会学到图像中的一些主要特征,如狗头,鼻子眼睛,纹理,轮廓等内容。但对特征图可视化有个明显的不足,即无法可视化图像中哪些区域对识别具体某个类别的作用,这个主要是使用CAM系列的方法,会在第三篇文章中介绍。下一篇将介绍可视化卷积核的方法。将放在公众号的技术总结部分。
参考论文:
《Visualizing and Understanding Convolutional Networks》
《Striving for Simplicity:The All Convolutional Net》
本文来源于公众号《CV技术指南》的技术总结部分,更多相关技术总结请扫描文末二维码关注公众号。

加载全部内容