知识图谱+推荐系统(一)
周若梣 人气:2知识图谱作为认知智能的重要一环,知识赋能的智能推荐将成为未来推荐的主流。智能推荐表现在多个方面,包括场景化推荐、任务型推荐、冷启动场景下推荐、跨领域推荐、知识型推荐[1]
1)场景化推荐
比如用户在淘宝上搜“沙滩裤”、“沙滩鞋”,可以推测这个用户很有可能要去沙滩度假。那么平台是否能推荐“泳衣”、“防晒霜”之类的沙滩度假常用物品呢?
2) 任务型推荐
比如用户购买了“羊肉卷”、“牛肉卷”、“菠菜”、“火锅底料”,那么用户很有可能是要做一顿火锅,这种情况下,系统推荐火锅调料、火锅电磁炉,用户很有可能买单
3) 冷启动下的推荐
冷启动阶段的推荐一直是传统基于统计行为的推荐方法难以有效解决的问题。利用外部知识,可以有效地解决传统推荐系统存在的稀疏性和冷启动问题
4) 跨领域的推荐
比如,如果一个微博用户经常晒九寨沟、黄山、泰山的照片,那么为这位用户推荐一些淘宝的登山装备准没错。这是典型的跨领域推荐,微博是一个媒体平台,淘宝是一个电商平台。他们的语言体系、用户行为完全不同,实现这种跨领域推荐显然商业价值巨大,但却需要跨越巨大的语义鸿沟。如果能有效利用知识图谱这类背景知识,不同平台之间的这种语义鸿沟是有可能被跨越的。比如百科知识图谱告诉我们九寨沟是个风景名胜,是个山区,山区旅游需要登山装备,登山装备包括登山杖、登山鞋等等,从而就可以实现跨领域推荐
5)知识型的内容推荐
在淘宝上搜索“三段奶粉”,能否推荐“婴儿水杯”,同时我们是否能推荐用户一些喝三段奶粉的婴儿每天的需水量是多少,如何饮用等知识。这些知识的推荐,将显著增强用户对于推荐内容的信任与接受程度。消费背后的内容与知识需求将成为推荐的重要考虑因素
如何将知识在不同场景下以合理的方式引入推荐系统是一个值得研究的问题。目前,将知识图谱特征学习应用到推荐系统中主要通过三种方式——依次学习、联合学习、以及交替学习[2]。
- 依次学习(one-by-one learning)[3]。首先使用知识图谱特征学习得到实体向量和关系向量,然后将这些低维向量引入推荐系统,学习得到用户向量和物品向量;

- 联合学习(joint learning)[4,5]。将知识图谱特征学习和推荐算法的目标函数结合,使用端到端(end-to-end)的方法进行联合学习;

- 交替学习(alternate learning)[6]。将知识图谱特征学习和推荐算法视为两个分离但又相关的任务,使用多任务学习(multi-task learning)的框架进行交替学习。

我们先来看下依次学习是怎么做的.《DKN: Deep Knowledge-Aware Network for News Recommendation》这篇文章是上交和MSRA在www'18发表的,文章以新闻推荐为例介绍了如何将知识图谱引入推荐系统。
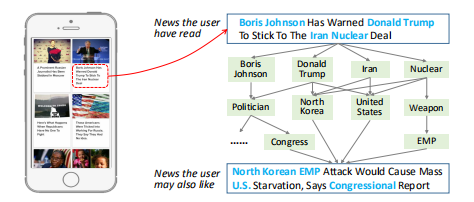
在新闻推荐领域存在三个主要挑战,第一,新闻具有时效性,传统的协同过滤方法不再有效;第二,用户在看新闻时会关注多个不同的主题,如何动态捕捉用户兴趣是一大难点;第三,新闻内容是高度精简的。如图所示,使用传统的word-level方法,两句话并没有关系,但是在knowledge-level层面,两句话的关联性就比较大。
DKN的框架如下图所示,DKN接受一组候选新闻和用户历史数据,KCNN部分负责将知识引入推荐过程,attention部分对新闻赋予不同的权重,捕捉用户兴趣,和DIN 一样。最后将得到的向量拼接,送入神经网络输出点击概率。下面重点看下KCNN部分,即知识如何引入的
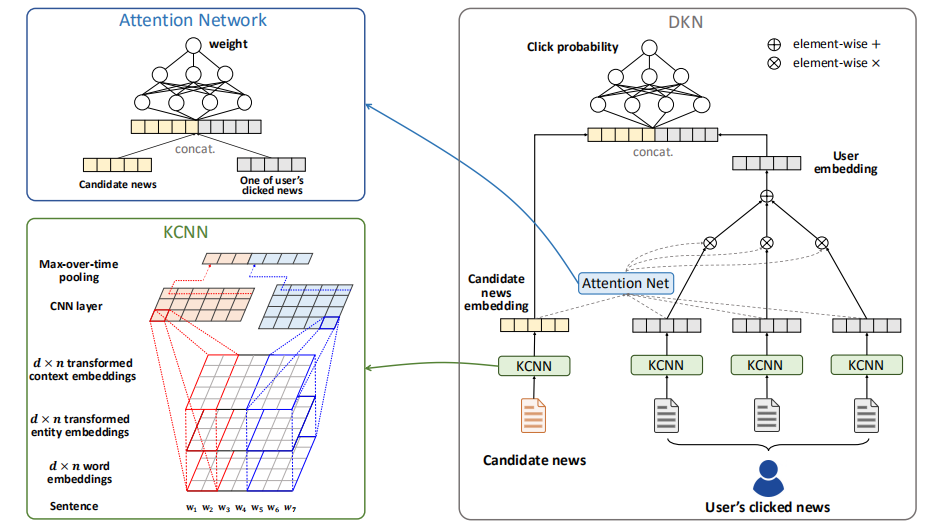
KCNN的输入特征包括三部分:新闻标题词向量\(\mathbf{w_i}\)、实体向量\(\mathbf{e}_{i}\)、上下文向量\(\overline{\mathbf{e}}_{i}\)。
1) \(\mathbf{w_i}\)
标题词向量根据语料库预训练得到
2) \(\mathbf{e}_{i}\)
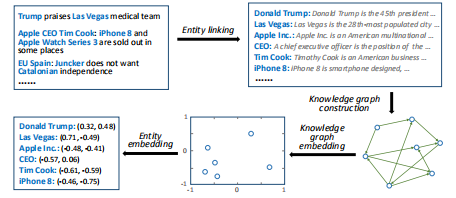
实体向量由知识图谱特征学习算法得到,具体过程如下:
1.使用实体链接技术将新闻文本中的实体和知识图谱中的实体相关联,消除歧义;
2.基于识别出的实体构造一个子图,并从原始知识图中提取它们之间的所有关系链接。 注意,所识别的实体之间的关系仅是稀疏的并且缺乏多样性。 因此,我们将知识子图扩展到已识别实体的一跳内的所有实体。
3.根据构造的子图,用TransE、TransH、TransR等方法得到embedding向量\(\mathbf{e}_{i}\)
3) \(\overline{\mathbf{e}}_{i}\)
为了更好的理解实体在知识图谱中的位置信息,作者提出了一个额外的语境向量。一个实体的语境 “context”定义为一跳邻居节点,语境的直观解释如下
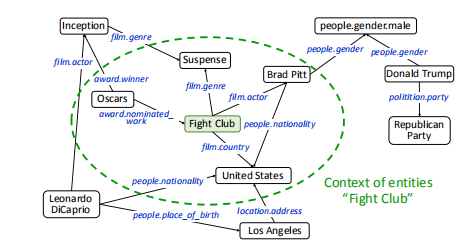
对应的语境向量为均值
\[
\begin{aligned}
&\text {context}(e)=\left\{e_{i} |\left(e, r, e_{i}\right) \in \mathcal{G} \text { or }\left(e_{i}, r, e\right) \in \mathcal{G}\right\}\\
&\overline{\mathrm{e}}=\frac{1}{| \text {context}(e) |} \sum_{e_{i} \in \text {context}(e)} \mathbf{e}_{i}
\end{aligned}
\]
每个输入向量作为一个通道,类似图像中的RGB通道,即多通道。注意,这里没有直接拼接原始向量和实体向量,因为1)拼接会破坏词和实体之间的关系;2)词向量和实体向量是用不同方法学习得到的,直接在单个通道进行操作显然不合理;3)拼接隐式的要求词向量和实体向量有相同的维度,实际上它们之间有差异。
总结一下依次学习过程:
构建知识图谱、学习实体特征向量、将实体特征向量和原始向量共同做为输入进行多通道卷积、利用attention机制捕捉兴趣、最终向量送入到网络输出点击概率。
从实验结果来看,DKN相比其他方法是有明显提升的

依次学习的优势:
1) 知识图谱特征学习模块和推荐系统模块相互独立。
2) 在知识图谱很大的情况下,可以先通过一次训练得到实体和关系向量,无需重新训练。
依次学习的缺点
1)因为两个模块相互独立,所以无法做到端到端的训练。知识图谱特征学习得到的向量会更适合于知识图谱内的任务,比如连接预测、实体分类等,并非完全适合特定的推荐任务。
2) 在缺乏推荐模块的监督信号的情况下,学习得到的实体向量是否真的对推荐任务有帮助,还需要通过进一步的实验来推断。
references:
[1]肖仰华:知识图谱与认知智能. https://zhuanlan.zhihu.com/p/35295166
[2]如何将知识图谱特征学习应用到推荐系统. https://www.msra.cn/zh-cn/news/features/embedding-knowledge-graph-in-recommendation-system-ii
[3] SJTU,MSRA. DKN: Deep Knowledge-Aware Network for News Recommendation.www'18
[4] Collaborative knowledge base embedding for recommender systems.
[5] Ripple Network: Propagating User Preferences on the Knowledge Graph for Recommender Systems.
[6] MKR: A Multi-Task Learning Approach for Knowledge Graph Enhanced Recommendation.
加载全部内容