浅谈Selenium+Webdriver 常用的元素定位方式
戈壁楼兰 人气:0这篇文章主要介绍了浅谈Selenium+Webdriver 常用的元素定位方式,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
假设页面源代码如下:
<input type="text"name="wd" id="kw1" class="input_wd" maxlength="100"style="width:474px;"autocomplete="off">
通过id定位元素:find_element_by_id(“id_vaule”):
browser=webdriver.Firefox()
browser.find_element_by_id("kw1")
通过name定位元素:find_element_by_name(“name_vaule”)
browser.find_element_by_name("wd")
通过tag_name定位元素:find_element_by_tag_name(“tag_name_vaule”)
browser.find_element_by_tag_name("input")#tag_name指标签名称
通过class_name定位元素:find_element_by_class_name(“class_name”)
browser.find_element_by_class_name("input_wd")
通过css定位元素:find_element_by_css_selector();用css定位是比较灵活的
browser.find_element_by_css_selector("input[id=\"kw1\"]")
browser.find_element_by_css_selector("input.input_wd)
browser.find_element_by_css_selector("#kw1)
通过xpath定位元素:find_element_by_xpath(“xpath”)
XPath(XML Path Language)是一种在XML文档中定位元素的语言,由于HTML文档本身就是一个标准的XML页面,所以我们可以使用XPath的语法来定位页面元素。
假设页面源代码如下:
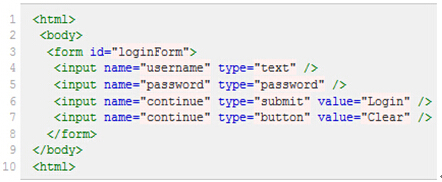
注:元素的xpath绝对路径可通过firebug直接查询,绝对路径以单/开头,从文档的根节点开始解析(如:/html/body/table/tbody/tr[2]/td[2]/div/div[1]/div/div[2]/div[4]/div[3]/div[1]/a[1]),相对路径则以//开头,从文档的任意节点开始解析。
相对路径的引用写法:
| 表达式 | 描述 |
|---|---|
| //input | 选取所有input元素 |
| //form[1]/input | 选取第一个form元素内的所有直接子input元素 |
| //form[1]//input | 选取第一个form元素内的所有子input元素,不论嵌套了多少层 |
| //form[1]/input[last()] | 选取第一个form元素内的所有直接子input元素中的最后一个 |
| //form[@id='loginForm'] | 选取id属性值为loginForm的form元素 |
| //input[@name='continue'][@type='button'] | 选取name属性值为continue且type属性值为button的input元素 |
| //form[@id^='loginForm']/input[4] | 选取id以loginForm开头的form元素下第4个input元素 |
| browser.find_element_by_xpath(“//td[contains(text(),'下单编号')]”) | 选取text文本为下单编号的td |
通过link定位:find_element_by_link_text(“text_vaule”)或者find_element_by_partial_link_text()
适用于页面中出现的文字链接
browser.find_element_by_link_text("登录").click() #点击登录链接
browser.find_element_by_partial_link_text("登").click()#只用了链接中的部分文字
参考资料:
加载全部内容