【redis】-- 数据结构及底层编码篇
双木l之林 人气:0数据结构
- String
- bitmaps也是“字符串”
- 使用场景
- 缓存
- 计数
- 共享Session
- 限速(限流)
- Hash
- 使用场景
- 缓存用户信息(多属性)
- 使用场景
- List
- 使用场景
- 关注列表
- 粉丝列表
- 消息列表
- 场景使用口诀:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpsh+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
- 使用场景
- Set
- 使用场景
- 标签(关系的维护必须是原子性,lua)
- 标签添加用户
- 用户调加标签
- 标签(关系的维护必须是原子性,lua)
- set 是可以自动排重的
- 使用场景
- Sorted Set(ZSet)
- zset增加了一个权重参数score,使得集合中的元素能够按score进行有序排列
- 使用场景
- 排行榜
- 用在"延时队列",通过将对应的过期时间设置为对应的score实现
底层编码
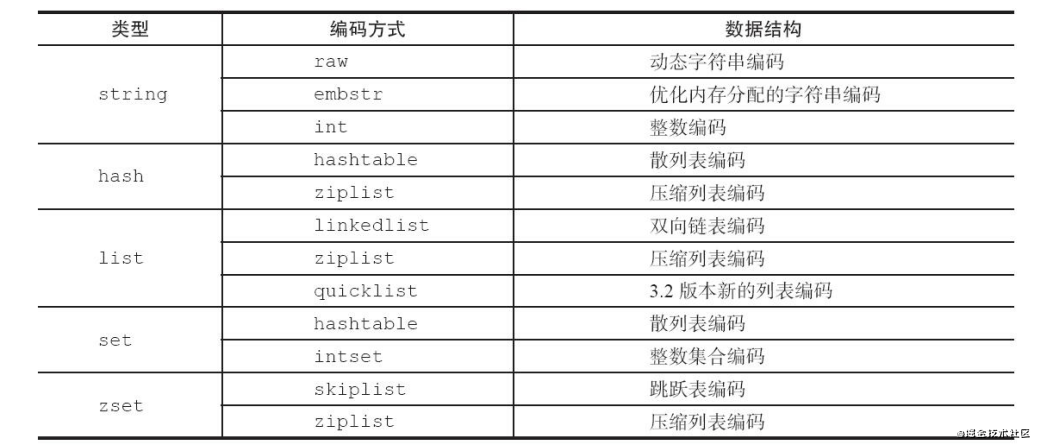
- 字符串 SDS(Simple Dynamic String):
- emb:
- 长度 <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT
- 它将RedisObject对象头和SDS对象连续存在一起,使用malloc方法一次分配,高并发写入场景中建议字符串小于该值,减少创建redisObject内存分配次数, 从而提高性能
- raw:
- 长度 > OBJ_ENCODING_EMBSTR_SIZE_LIMIT
- raw 存储形式不一样,它需要两次malloc,两个对象头在内存地址上一般是不连续的
- emb:
- 长度OBJ_ENCODING_EMBSTR_SIZE_LIMIT与redis版本有关
- 结构图
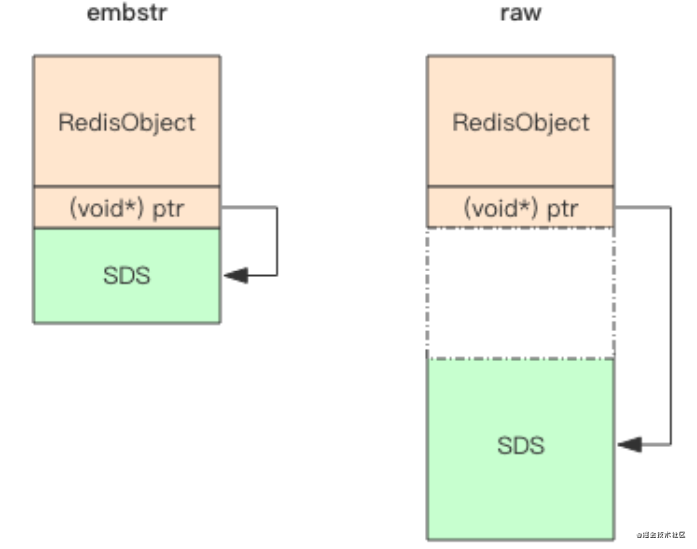
- 字典 dict
- dict 结构内部包含两个 hashtable,通常情况下只有一个 hashtable 是有值的。但是在dict扩容缩容时,需要分配新的hashtable,然后进行渐进式搬迁(),这时候两个hashtable存储的分别是旧的hashtable和新的hashtable。待搬迁结束后,旧的hashtable被删除,新的hashtable 取而代之
- 渐进式 rehash:渐进式 rehash 小步搬迁
- 被动搬迁:来自客户端指令(hset/hdel)
- 主动搬迁:定时任务databaseCron
- 扩容条件
- 正常情况下,当hash表中元素的个数等于第一维数组的长度时,就会开始扩容,扩容的新数组是原数组大小的2倍。不过如果Redis正在做bgsave,为了减少内存页的过多分离 (Copy On Write),Redis尽量不去扩容(dict_can_resize),但是如果hash表已经非常满了,元素的个数已经达到了第一维数组长度的5倍(dict_force_resize_ratio),说明hash表已经过于拥挤了,这个时候就会强制扩容
- 缩容条件
- 缩容的条件是元素个数低于数组长度的10%。缩容不会考虑 Redis 是否正在做 bgsave
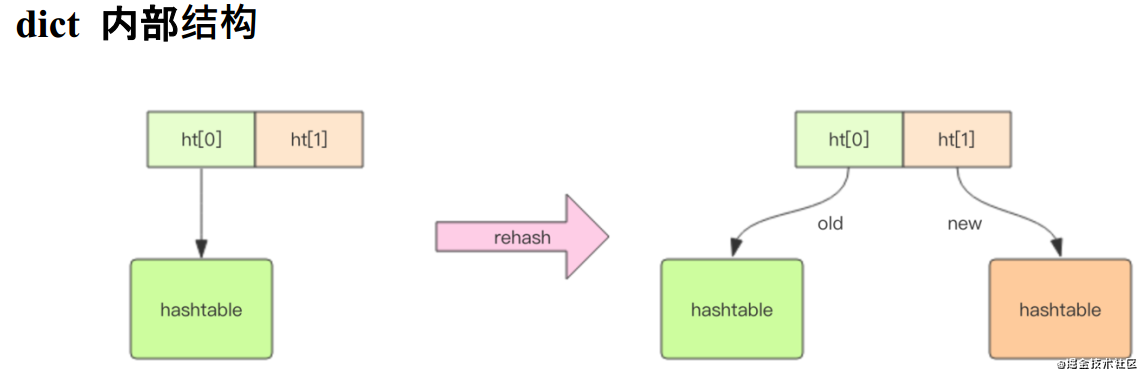
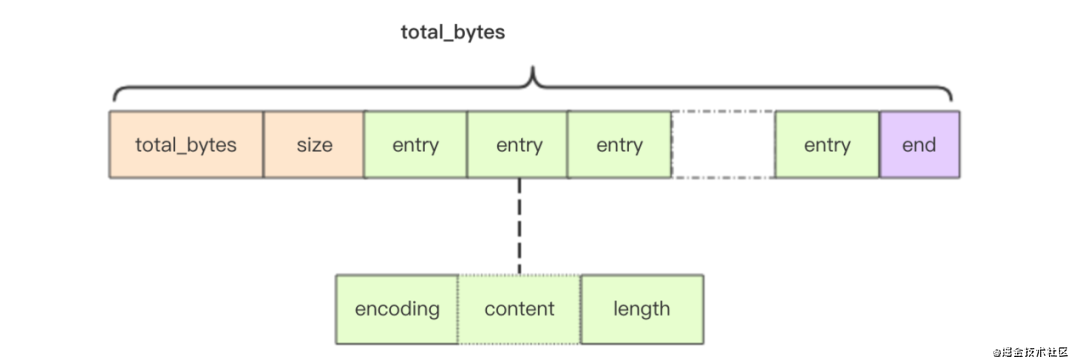
- 压缩列表 ziplist
- 支持双向遍历
- 级联更新 (O(n)~O(n2))
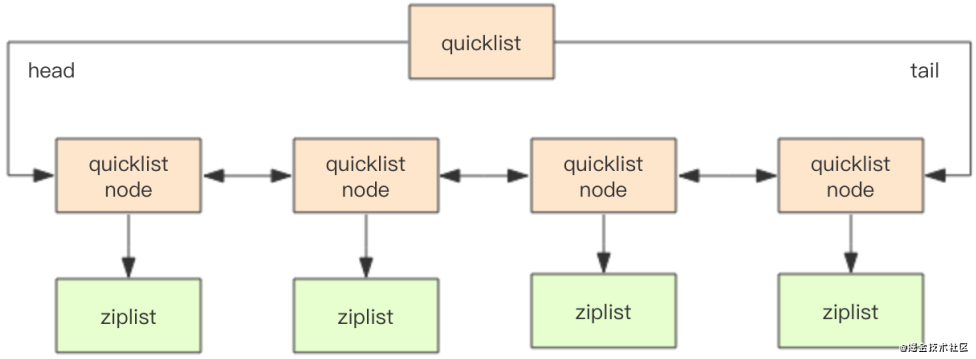
- 快速列表 quicklist (待补充)
- quicklist 是 ziplist和linkedlist的混合体,它将linkedlist按段切分,每一段使用 ziplist 来紧凑存储,多个 ziplist 之间使用双向指针串接起来
- 为了进一步节约空间,Redis还会对ziplist进行压缩存储,使用LZF算法压缩,可以选择压缩深度
- quicklist 内部默认单个ziplist长度为8k字节,超出了这个字节数,就会新起一个ziplist。 ziplist 的长度由配置参数 list-max-ziplist-size 决定
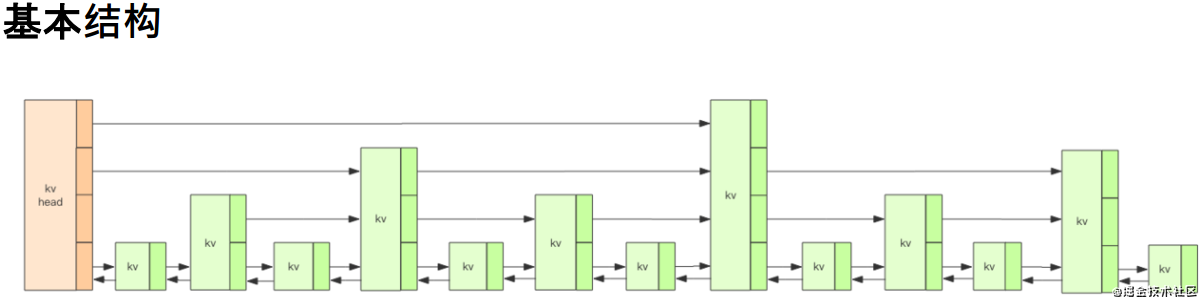
- 跳跃列表 skiplist
- 基础结构:Redis 的跳跃表共有64层,意味着最多可以容纳2^64次方个元素。每一个 kv 块对应的结构如下面的代码中的 zslnode 结构,kv header也是这个结构,只不过 value 字段是 null 值——无效的, score 是Double.MIN_VALUE,用来垫底的。 kv 之间使用指针串起来形成了双向链表结构,它们是有序 排列的,从小到大。不同的 kv 层高可能不一样,层数越高的kv越少。同一层的kv会使用指针串起来。每一个层元素的遍历都是从 kv header 出发
- 紧凑列表 listpack
- 对 ziplist 结构的改进,在存储空间上会更加节省,而且结构上也比 ziplist 要精简
- 元素之间独立,不存在级联更新
- 注意:编码类型转换在Redis写入数据时自动完成, 这个转换过程是不可逆的, 转换规则只能从小内存编码向大内存编码转换
- 附图
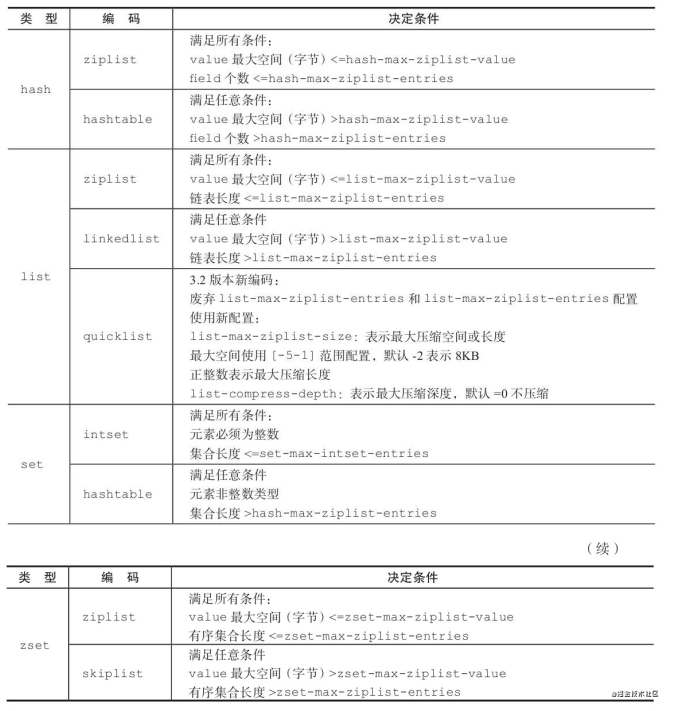
加载全部内容