Redis基础篇(六)数据同步:主从复制
大杂草 人气:0Redis具有高可靠性,体现在两方面:
- 一是数据尽量少丢失,通过前面介绍的持久化方式AOF和RDB,在宕机时可以恢复数据。
- 二是服务尽量少中断,通过副本冗余来实现。
今天我们学习的就是通过主从复制实现副本冗余,从而实现Redis的高可靠性。
什么是主从复制
Redis提供主从库模式,保证数据副本的一致,主从库之间采用的是读写分离的方式。
为什么要读写分离?
如果允许所有节点能够处理读写请求,就需要解决加锁、实例间协商、数据同步等操作,会带来巨额的开销。
因此采用主从库模式时,要配置主库只写,从库只读。
主从库如何进行第一次同步?
当设置了主从库模式,此时从库是空的,如何进行主从库的第一次同步呢?
Redis采用全量复制来进行第一次同步,具体有三个步骤,如下图所示:

第一步,主从库建立连接,协商同步。
- 从库发送psync命令,表示进行数据同步。其中runID表示主库ID,第一次不知道主库的runID,就设置为"?"
- 主库收到psync命令后,用FULLRESYNC响应,返回runID(主库ID)和offset(主库目前的复制进度)。
- 从库收到响应后,记录这两个参数
第二步:主库同步数据给从库。
从库收到数据后,在本地完成数据加载。这过程依赖于RDB快照。
- 主库执行bgsave命令,生成RDB文件,再把文件发强从库。
- 从库收到RDB文件后,先清空当前数据库,然后加载RDB文件。
第三步,主库发送新写命令给从库
主库在数据同步过程中,会记录所有写操作,避免丢失同步过程接收的新的写命令。
- 主库使用replication buffer来新的写命令。
- 当从库加载RDB文件完成后,主库再把replication buffer的内容发送给从库,从库再执行这些操作实现同步。
关于replication buffer的更多内容,下面再介绍。
如果有多个从库,每个从库都要跟主库进行全量同步,这样主库的压力会很大。
主从级联模式
Redis提供“主-从-从”模式将主库生成RDB和传输RDB的压力,以级联的方式分散到从库上。
简单来说,构建父子从库结构,子从库的数据同步从父从库获取。如下图所示:
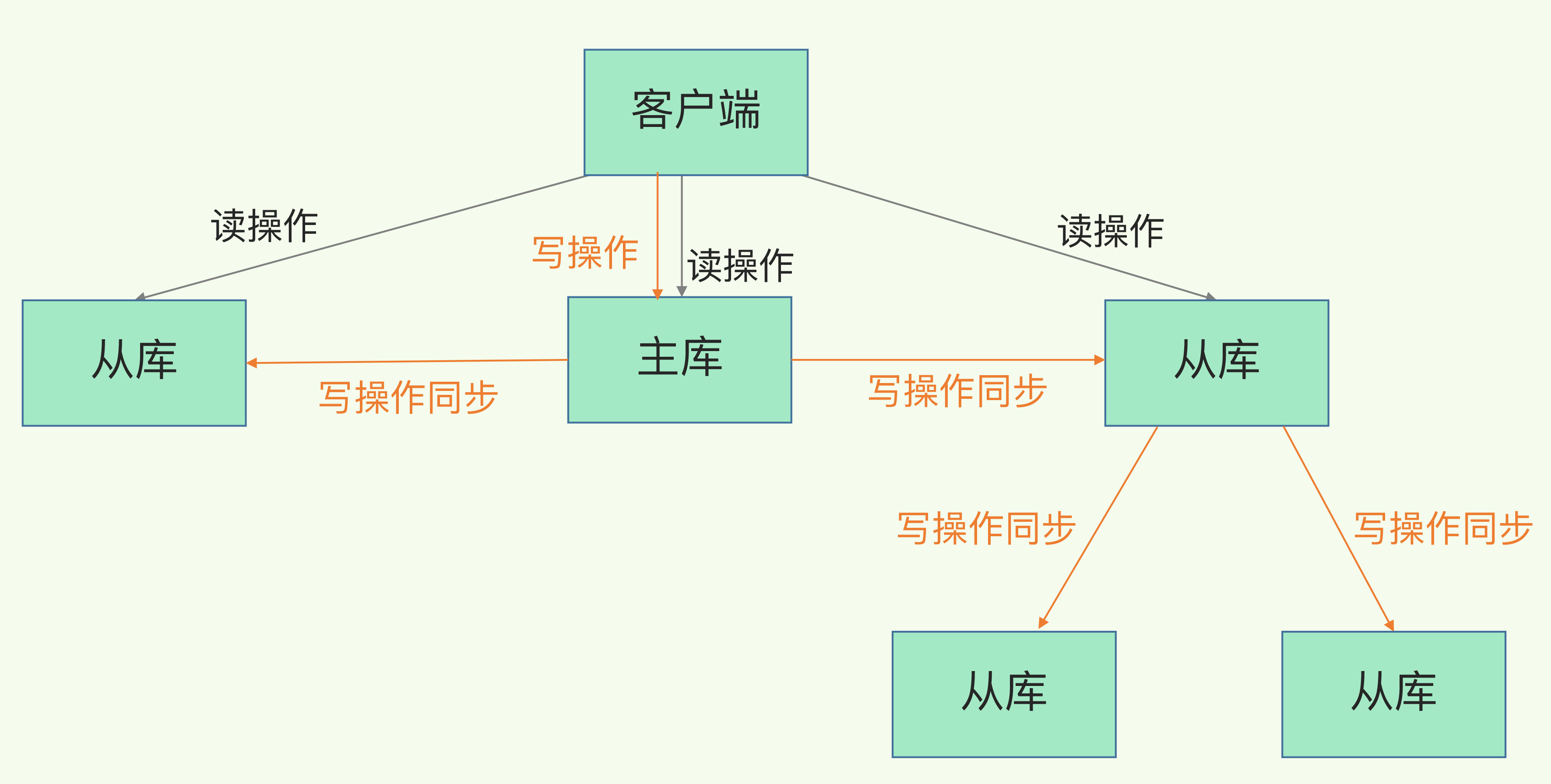
在从库上执行命令:replicaof 所选从库的IP 6379,就可以设置从库的父从库了。
至此,主从库完成了第一次同步,那后续如何保持同步呢?
如何保持同步?
当主从库完成同步后,会维护一个网络连接,主库会通过这个连接将后续的命令同步给从库。
但是这里有潜在的风险点:如果网络断连或者出现阻塞了,那怎么办呢?
主从库间网络断了怎么办?
在Redis 2.8之前,网络断了后要重新进行全量复制。但在Redis 2.8之后,Redis提供了增量复制的方式。
当建立了主从结构后,主库会把写命令写入repl_backlog_buffer缓冲区里,当网络断开并重新连接后,从库会发送同步命令,然后主库再把未同步的命令发送给从库,从库执行这些命令就恢复数据一致了。具体流程如下图所示:

repl_backlog_buffer是一个环形缓冲区,如下图所示:
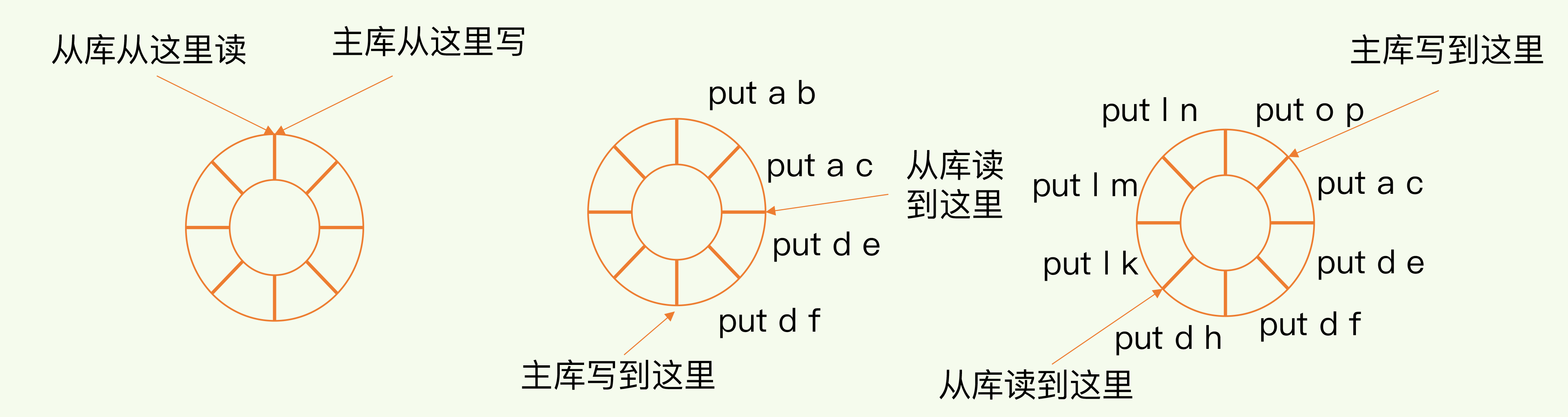
由于其环形结构,当因为网络问题影响从库读取命令的速度,会出现写满后继续写入命令时,会覆盖掉从库还没读的内容,从而造成数据不一致,需要重新全量复制。
因此要根据情况来设置repl_backlog_buffer的大小,通过配置repl_backlog_size来调整缓冲区大小。配置公式为:缓冲空间大小 = 主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小。而repl_backlog_size= 缓冲空间 * 2。
例如主库写操作2000/秒,每个操作大小2KB,网络传输1000个操作/秒,那缓冲空间大小=2000*2 - 1000*2=2MB,那repl_backlog_size就设置为4MB。
拓展
为什么主库间的数据复制同步不使用AOF?
有三方面原因:
- RDB文件是经过二进制压缩的,文件很小,这样主从库间传输就很快。
- 从库加载RDB文件速度很快,而AOF日志还要逐行命令执行,速度很慢。
- 假设使用AOF,那就必须打开AOF,Redis默认是不开启AOF的,可能会影响Redis性能。
关于replication buffer
每个与Redis通信的客户端(从库也算client),都会分配一个buffer,所有数据交互都是通过这个buffer进行的。
Redis先把数据写到这个buffer中,然后再把buffer中的数据发到client的socket中,通过网络发送出去,完成数据交互。
而主从同步的这个buffer,是用于保证主从数据一致的,所以才叫它replication buffer。
可以通过配置项client-output-buffer-limit来配置这个buffer的大小。当保存到buffer里的内容超过限制,主库会强制断开这个client的连接。这样会有潜在风险。
如果从库处理主库传输的命令非常慢,就会把这个buffer撑满,然后主库会断开连接。中断后,从库再次发起复制请求,可能会导致恶性循环,引发复制风暴。
小结
- 主从库模式是采用RDB快照的全量复制 + 基于长连接的网络通信实现主从复制的。
- 通过“主-从-从”模式,将主库生成RDB和传输RDB的压力,以级联的方式分散到从库上。
- 当网络中断,通过主库的repl_backlog_buffer,实现增量复制,无须重新全量复制。
- repl_backlog_buffer是环形缓冲区,要根据网络状况,合理配置其大小。
- 一个Redis实例的数据库不要太大,在几GB比较合适,这样可以减少RDB文件生成、传输和重新加载的开销。
参考资料
- 06 | 数据同步:主从库如何实现数据一致?
加载全部内容