数据库必知必会
码农小林 人气:0传播行为分为两种:分为支持事物的传播和不支持事物的传播
1、PROPAGATION_REQUIRED:(支持事物)如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。
2、PROPAGATION_SUPPORTS:(支持事物)支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。‘
3、PROPAGATION_MANDATORY:(支持事物)支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
4、PROPAGATION_REQUIRES_NEW:(支持事物)创建新事务,无论当前存不存在事务,都创建新事务。
5、PROPAGATION_NOT_SUPPORTED:(不支持事物)以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
6、PROPAGATION_NEVER:(不支持事物)以非事务方式执行,如果当前存在事务,则抛出异常。
7、PROPAGATION_NESTED:(不支持事物)如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。
PROPAGATION_NESTED和PROPAGATION_REQUIRED区别
spring的事务是什么?与数据库的事务是否一样?
本质上其实是同一个概念,spring的事务是对数据库的事务的封装,最后本质的实现还是在数据库,假如数据库不支持事务的话,spring的事务是没有作用的.数据库的事务说简单就只有开启,回滚和关闭,spring对数据库事务的包装,原理就是拿一个数据连接,根据spring的事务配置,操作这个数据连接对数据库进行事务开启,回滚或关闭操作。
如何设计一个关系型数据库?

为什么要使用索引?
数据量大的情况下,尽量避免全表扫描,使用索引,可以大幅提高扫描速度。
什么样的信息能成为索引?
索引的数据结构?
二叉树,B树,B+树,Hash,BitMap
B树
- 根节点至少包括两个孩子;
- 树中每个节点最多含有m个孩子(m>=2);
- 除根节点和叶节点外,其他每个节点至少有ceil(m/2)个孩子
- 所有叶子节点都位于同一层;
-
假设每个非终端节点中包含有n个关键字信息,其中
a) ki(i=1...n)为关键字,且关键字按顺序升序排序k(i-1)<=kib) 关键字的个数n必须满足:[ceil(m/2)-1]<=n<=m-1c) 非叶子节点的指针:P[1],P[2],...P[m];其中P[1]指向关键字小于k[1]的子树;P[m]指向关键字大于k[m]的子树;其他P[i]指向关键字属于(k(i-1),ki)的子树。
相对于二叉树,B树让每个索引库存储更多东西,减少io次数。
B+树
定义
- 非叶子结点的子树指针与关键字个数相同;
- 非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树;
- 非叶子节点仅用来索引,数据都保存在叶子节点中;
- 所有叶子节点均有一个链指针指向下一个叶子节点,有利于做范围统计
B+树更适合来做索引
- 磁盘读写代价更低:B+树非叶子节点只放索引信息,不存放数据,因此内部节点相对B树更小,可以一次性读取更多数据,减少IO读写
- 查询效率更加稳定:任何信息查找,都必须走一条从根节点到叶子结点的路,所有关键字查找长度相同
- 更有利于对数据库的扫描:只需遍历叶子节点链表即可
Hash索引
- 只能等值查询,不能范围查询,无法排序(存放的hash值大小顺序,并不能保证和运算前的一样)
- 不能避免表扫描(哈希函数计算后的哈希值和行指针信息放到bukket中,不同索引值存在相同哈希值,还需要访问bukket的实际数据作比较)
- 不能利用部分索引键查询,因为计算函数值是根据整个组合键
- 如果存在大量相同hash值,性能可能很低,不稳定
BitMap索引(位图)
- 存放的值是固定几个的话,可以用来做高效统计
- 锁的力度很大,修改的时候,在同一位图的东西都会被锁住
- 不适合高并发
密集索引
稀疏索引
密集索引和稀疏索引的区别
- 若有定义主键,则主键作为密集索引
- 若没有定义主键,该表的第一个唯一非空索引作为密集索引
- 上面两种情况都没有,内部会生成一个隐藏主键
如何定位并优化慢查询SQL?
-
根据慢日志定位慢查询SQL
-
重点关注type和extra
| type 重要的项,显示连接使用的类型,按最 优到最差的类型排序 | 说明 |
| system | 表仅有一行(=系统表)。这是 const 连接类型的一个特例。 |
| const | const 用于用常数值比较 PRIMARY KEY 时。当 查询的表仅有一行时,使用 System。 |
| eq_ref | const 用于用常数值比较 PRIMARY KEY 时。当 查询的表仅有一行时,使用 System。 |
| ref | 连接不能基于关键字选择单个行,可能查找 到多个符合条件的行。 叫做 ref 是因为索引要 跟某个参考值相比较。这个参考值或者是一 个常数,或者是来自一个表里的多表查询的 结果值。 |
| ref_or_null | 如同 ref, 但是 MySQL 必须在初次查找的结果 里找出 null 条目,然后进行二次查找。 |
| index_merge | 说明索引合并优化被使用了。 |
| unique_subquery | 在某些 IN 查询中使用此种类型,而不是常规的 ref:value IN (SELECT primary_key FROM single_table WHERE some_expr) |
| index_subquery | 在 某 些 IN 查 询 中 使 用 此 种 类 型 , 与 unique_subquery 类似,但是查询的是非唯一 性索引: value IN (SELECT key_column FROM single_table WHERE some_expr) |
| range | 只检索给定范围的行,使用一个索引来选择 行。key 列显示使用了哪个索引。当使用=、 <>、>、>=、<、<=、IS NULL、<=>、BETWEEN 或者 IN 操作符,用常量比较关键字列时,可 以使用 range。 |
| index | 全表扫描,只是扫描表的时候按照索引次序 进行而不是行。主要优点就是避免了排序, 但是开销仍然非常大。 |
| all | 最坏的情况,从头到尾全表扫描。 |
| extra 项 | 说明 |
| Using filesort | 表示 MySQL 会对结果使用一个外部索引排序,而不是从表里按索引次序读到相关内容。可能在内存或者磁盘上进行排序。MySQL 中无法利用索引完成的排序操作称为“文件排序” |
| Using temporary | 表示 MySQL 在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。 |
-
修改SQL并让其尽量走索引
联合索引的最左匹配原则
- 最左前缀匹配原则,非常重要的原则,MySQL 会一直向右匹配直到遇到范围查询(> , < ,between,like)就停止匹配。比如 a = 1 and b = 2 and c > 3 and d = 4,如果建立的是(a,b,c,d)这种顺序的索引,那么 d 是用不到索引的,但是如果建立的是 (a,b,d,c)这种顺序的索引的话,那么就没问题,而且 a,b,d 的顺序可以随意调换。
- = 和 in 可以乱序,比如 a = 1 and b = 2 and c = 3 建立 (a,b,c)索引可以任意顺序,MYSQL的查询优化器会帮忙优化
- mysql创建复合索引的规则是首先会对复合索引的最左边,也就是索引中的第一个字段进行排序,在第一个字段排序的基础上,在对索引上第二个字段进行排序,其实就像是实现类似order by 字段1,字段2这样的排序规则,那么第一个字段是绝对有序的,而第二个字段就是无序的了,因此一般情况下直接只用第二个字段判断是用不到索引的,这就是为什么mysql要强调联合索引最左匹配原则的原因。
- 数据量小的表不需要建立索引,建立会增加额外的索引开销
- 数据变更需要维护索引,意味着更多的索引意味着更多的维护成本
- 更多的索引也需要跟多的存储空间
-
MyISAM默认用的是表级锁,不支持行级锁
-
InnoDB默认用的是行级锁,也支持表级锁(innobdb没有使用索引使用的是表锁,使用索引用的是行锁)
-
InnoDB对查询优化,默认不加锁
MyISAM适合场景
- 频繁执行count语句
- 增删改不频繁,查询非常频繁
- 没有事务。
InnoDB适合场景
- 可靠性要求比较高,要求支持事务
- 数据增删改查都相当频繁
锁的划分
乐观锁实现
- 使用数据版本(Version)记录机制实现
- 使用时间戳字段
事务的四大特性(ACID)
- 原子性(Atomic)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
当前读与快照读
1.当前读
- select … lock in share mode,select … for update
- update,delete,insert
update语句,先select数据最新版本,再update,所以是当前读,delete和insert同理。
2.快照读:不加锁的非阻塞读,select
事务隔离级别以及各级下的并发访问问题
- 更新丢失(即一个事务的更新覆盖了另一个事务的更新)
- 脏读(读取了另一个更新事务,更新之前的数据)
- 不可重复读(其他事务的修改,当前事务对同一条数据,每次读取结果不一样)
- 幻读(指新插入的行,读到原本存在行的更新结果不算,只在当前读下,一个事务(同一个read view)在前后两次查询同一范围的时候,后一次查询看到了前一次查询没有看到
| 事务的隔离级别 | 更新丢失 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| 未提交读 | 避免 | 发生 | 发生 | 发生 |
| 已提交读 | 避免 | 避免 | 发生 | 发生 |
| 可重复读 | 避免 | 避免 | 避免 | 发生 |
| 串行化 | 避免 | 避免 | 避免 | 避免 |
RC,RR级别下的INNODB的非阻塞读如何实现
-
数据行里的DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID字段
-
undo日志(每操作一次数据,顺序增加一个日志)
-
read view(快照本照了)
1.数据行DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID字段
DB_TRX_ID(最后一次操作事务ID)
DB_ROLL_PTR(回滚指针)
DB_ROW_ID(InnoDB表中在没有默认主键的情况下会生成一个6字节空间的自动增长主键)
2.undo日志
第1次修改数据12为32
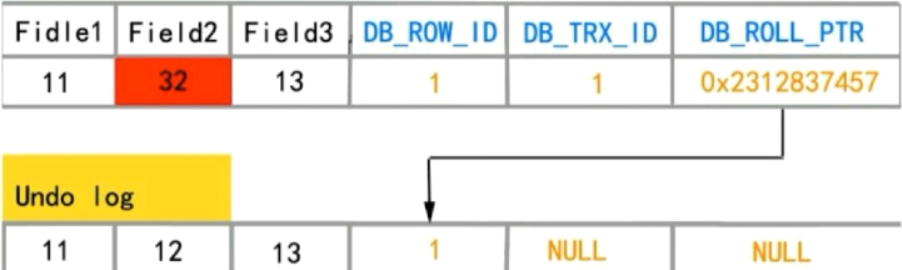
3.read view
RC下,快照读和当前读结果一样,原因是每次快照读会创建一个新的read view
RR下,快照读如果在修改后读,结果会和当前读一样,否则不一样,原因是第一条快照读会创建一个read view,后面再调用快照也是使用这个read view
InnoDB可重复读隔离级别下如何避免幻读
-
表象:快照读(非阻塞读)—伪MVCC
-
内在:next-key锁,(行锁+gap锁)
Gap锁:间隙锁,锁定一个范围,不包括记录本身,目的是为了防止同一事务的两次当前读出现幻读的情况,RR级别及以上才有。
对主键索引或者唯一索引会用Gap锁
- 如果where条件全部命中,则不会用Gap锁,只会加记录锁
- 如果where条件部分命中或者全不命中,则会加Gap锁
关键语法
加载全部内容