count(*) 优化
萌新J 人气:0几种获取记录数的方法
count(*): MySQL 优化过,扫描的行数小于总记录数。执行效率高。
count(1): 遍历所有记录,不取值,对每行尝试添加一个 “1” 列,如果不为 null,就计入累加(引擎层)。
count(主键): 遍历所有记录,并把每个记录的 id 取出返回 Server 层判断,将不为 null 的计入累加。
count(字段): 遍历所有记录,并把每个记录的字段值取出返回 Server 层判断,将不为 null 的计入累加。
效率排序: count(*) ≈ count(1) > count(主键) > count(字段)
除此之外,还可以通过 " show table status like '表名' " 查看 'TABLE_ROW' 参数来获取系统内部通过采样估算的记录数,但误差会达到 40% -- 50%。
优化
使用缓存
通过上面的分析可以知道通过 count(*) 来获取计数已经是效率最高的一种方式了, 但是如果效率还是低呢?首先效率低肯定是执行计数操作的并发量太高所导致的。而应对查询操作最常见的优化方式就是使用缓存,但是使用缓存适用于查多写少的场景,不过因为计数不会因为修改操作而改变,只会被增删操作所改变,所以在增删操作少的场景也是可以使用的。但是还有另外一个问题,那就是获取计数的业务和计数自增自减的操作不能保证原子性。这样导致查出的结果可能并不准确。
比如:
有一个页面,要显示操作记录的总数,同时还要显示最近操作的 100 条记录。那么,这个页面的逻辑就需要先到 Redis 里面取出计数,再到数据表里面取数据记录。
一种是,查到的 100 行结果里面有最新插入记录,而 Redis 的计数里还没加 1;
另一种是,查到的 100 行结果里没有最新插入的记录,而 Redis 的计数里已经加了 1。
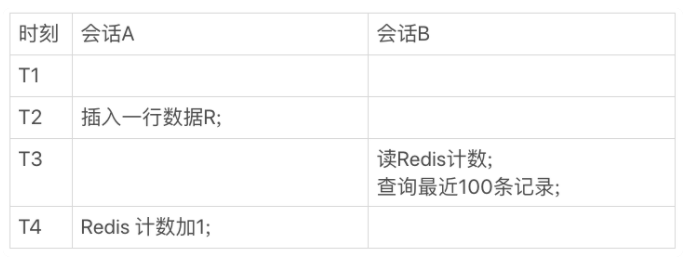
那么第一种情况就会导致查询的计数和记录对不上,得到的结果混乱。
数据库
如果将计数结果单独创建一张表来存储,搭配 MySQL 的可重复读隔离级别,就可以实现数据读取的 "原子性" ,并且效率也会很高。
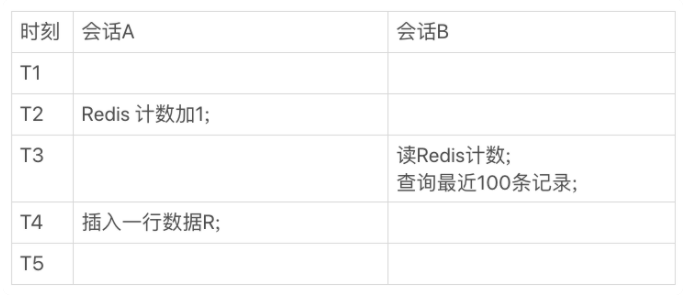
在会话B读取计数时就会因为会话A还未提交,所以不会读取到会话A执行过的操作。
加载全部内容