由数据迁移至MongoDB导致的数据不一致问题及解决方案
上海小胖 人气:2
故事背景
企业现状
2019年年初,我接到了一个神秘电话,电话那头竟然准确的说出了我的昵称:上海小胖。
我想这事情不简单,就回了句:您好,我是小胖,请问您是?
“我就是刚刚加了你微信的 xxx 啊”
哦……他只是把我的微信昵称报出来了……
随着深入沟通,了解到对方是某央企保密单位的大数据部门技术负责人,因为目前整个集团在进行数字化转型。在决策过程中,遇到了几个阻力。
首先,大部分部门和科室的数据基础还很薄弱,存在数据标准混乱、 数据质量层次不齐、各条块之间数据孤岛化严重等现象,阻碍了数据的共享应用。
其次,受限于数据规模和数据源种类的丰富程度,多数企业的数据应用刚刚起步,主要集中在精准营销,舆情感知和风险控制等有限场景,应用深度不够,应用空间亟待开拓。
再次,由于数据的价值很难评估,企业难以对数据的成本以及其对业务的贡献进行评估,从而难以像运营有形资产一样管理数据资产。
而这位技术负责人本着认真、负责、专研的精神,死磕大数据领域,试图在市面上找到一款能够满足他需求的产品,帮助他解决数据痛点。
经过沟通,了解到目前的企业数据现状是:
- 数据散落在各部门科室,8大部门共50+科室
- 数据量非常大,高峰期每小时可产生100GB数据,每天存量数据 1TB
- 数据类型丰富,包括:
- 关系型数据库:Oracle,MySQL,PostgreSQL,GBase,GauseDB等
- 非关系型数据库:MongoDB
- 结构化文件:XML,Excel,CSV,TXT
- 非结构化文件:音频,视频,pdf
- 每个月都会有 5 个新项目,而每次对接新项目都需要花费 1-3个月时间在数据对接上
- 项目周期长,而大多数时间都在数据冗余、清洗、过滤上
- 多副本数据带来的数据维护成本也在不断增加,影响了研发进度
考虑迁移
在坚定不移的执行数字化转型战略,打赢传统数据组织转向大数据生态的攻坚战中,技术负责人悟出了一个道理,要打赢这场硬仗,必须得做数据整合!
要做数据整合,那不就是传统数据仓库和数据湖吗?在技术负责人经过一番市场调研后发现,数据仓库和数据湖都无法满足他心中的未来大数据架构。
那是什么样的数据架构无法满足呢?面向应用开发的共享数据
简而言之就是,数据仓库和数据湖无法做即时交付,目前的应用场景还是如上文提到的:应用深度不够,应用空间亟待开拓。
经过几番调研后,技术负责人找到一款产品Tapdata,用他的原话说就是:“这款产品的理念很先进,可以说和我的想法不谋而合。”
扩展开来说就是:
- 通过数据同步完成数据汇聚、采集工作
- 通过数据发布对外提供数据服务
- 通过数据治理对数据资产进行有效管理
而最重要的是数据是可被重复使用,可实时交付的。
解决方案
架构
Tapdata 的数据同步工具,只需要简单的拖拉拽,就可以完成多源数据库的同步。同时依赖于灵活的 js 脚本能力,对复杂的 ETL 场景也可以非常轻松搞定。
那这里就上一个当时给技术负责人就他们企业现状做的架构图,因为本篇文章是在讨论数据迁移,所以我就给出数据同步的架构图。
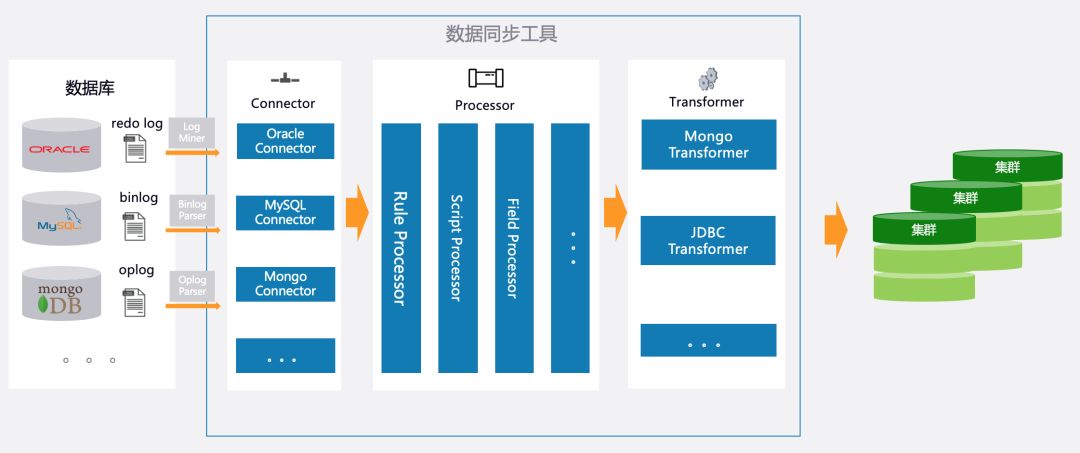
整个架构采取 mongodb 分片集群作为底层存储,使用数据同步工具将多源数据实时抽到 mongodb 中,在抽取过程中完成数据清洗、过滤。
技术实现
在使用数据同步工具做数据迁移的时候,需要和用户沟通具体场景,比如:
- 本次目标是一次性数据导入,还是需要之后保持增量同步
- 数据迁移中有没有复杂的ETL场景
- 对同步延时要求
- 同步的数据量预估,高峰预估
在明确目标和需求后,我们采取了多节点分布式采集的方式来满足应用高峰时产生的数据量,根据当时预估高峰每小时 100GB,一天存量 500GB 计算。
通过数据工具将不同的数据源,通过任务编排的方式进行组合,完成数据清理工作。
用户本次数据同步要求更多是在数据同步性能及数据量上,对数据的ETL没有过多的要求,都是一些简单的字段重命名,字段类型转换
所以通过数据同步工具只需要 1 分钟即可完成从源端数据库到目标端 mongodb 的同步工作。
创建数据源
编排任务
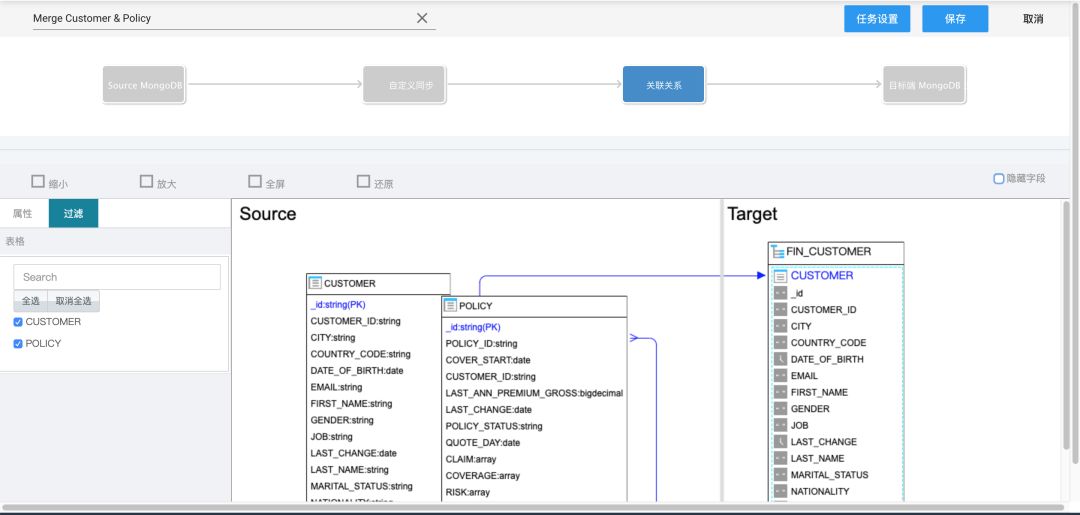
和实施前对比
目前上线的数据源有 Oracle、MongoDB、MySQL、PostgreSQL、GBase。数据库集群数量达到10+套,同时支撑3条完整业务线运作,并发高峰达到 18w/秒。
有效解决了当时阻碍技术负责人执行的最大障碍:大数据量的数据同步工作,及落地后的数据管理。
新增业务时,用户技术人员只需要做简单的拖动就可以完成。减少了技术人员的开发工作,帮助技术人员将更多的时间聚焦在核心业务上。极大缩短了项目上线周期。
孤儿文档
现象
在运行了一段时间后,在一次新应用接入后,发现接入的数据有重复,通过TD的数据比对工具发现源端 mongo 和目标端 mongodb 在相同表的数据量上确实存在差异。
这个事情对于数据同步工具来说是非常致命的,数据同步最核心的能力就是要保障数据的一致性,而数据同步工具的数据幂等性也是经过中国软件评测中心的测试认证的。
对于该现象的发生,我们团队非常重视,如果真是同步工具导致的数据不一致性,那就是致命bug。需要回归所有功能。
排查
随机便在第一时间联系上用户技术,并开展了一系列的排查工作。
确认数据库类型
排查第一步就是确认源端和目标端的数据库类型和操作系统配置。
本次出现数据重复的任务涉及到的数据库情况是:
- 源端数据库
- mongo 3.2
- 单实例副本集
- 64c 256GB SAS硬盘
- 万兆光纤内网
- 目标端数据库
- mongo 4.0
- 6分片集群
- 64c 256GB SAS硬盘
- 万兆光纤内网
找出重复数据
既然有重复数据,那我们就要先找出这些数据来。
源端数据库是 mongo,目标端也是 mongo,这就比较好办了,写一套 js 脚本即可。这里会有一个坑,后面会说到,就是分片集群需要去每个节点上查,而不要在 mongos 上查。
脚本很简单,因为数据同步工具在同步的时候是会根据业务主键同步的,所以我就可以在目标端集合中,遍历每条数据,然后拿着业务主键去源端数据库查询,比对所有值。
这个过程会很慢,但只能等。
当然要注意的是,由于源端数据库是单节点,所以理论上应该同步一份数据出来作比对会好些,但是由于该业务还没上线,所以影响不大。而目标端数据的话是可以通过查找从节点数据进行比对的。
比对结果就是二十几张表一共 1kw 的数据,有十几万重复。看起来这个重复的数据量还不少。
这里我定义的重复数据就是相同的业务主键应该是数据唯一的,但在目标端却查到不止一条。
检查数据同步工具日志
现在有了重复数据,就可以去数据同步工具日志里查询了。
在同步过程中是否有出现数据重复,或者 ERROR,如果发现有 duplicate key 字样,那就可以顺着这条记录往下排查。
但很遗憾,在日志中并没有发现类似字眼
检查 mongodb 日志
数据同步工具日志无果,转战 mongodb 日志,通过查看 mongodb 日志,发现有大量的recvChunk 和 moveChunk 日志

看到这个,我一下子就不困了呀。
我简单给大家说下这段日志在干嘛。因为目标端 mongodb 是分片集群,分片中有一个很重要的概念叫块移动。分片集群是以数据块(chunk)为最小单位进行存储的,默认一个块可以存储64MB大小数据。
那这和本次的数据不一致又有什么关系呢?抖精神的地方来了,mongodb 对于均衡分片的处理方式是:先将 shard 1 节点的 chunk 拷贝到 shard 2 节点去,当 chunk 完全拷贝完成后,在将 shard 1 节点的 chunk 删了。
那么在这个转移的过程中,大家就可以想到,有好几个环节都会发生意外,从而导致块迁移失败。
排查到这里,就有必要和用户确认当天的操作流程了。
果不其然,当天其实发生过服务器断网,而这个断网就是在业务刚刚接入的10分钟后。让我们来还原案发现场。
用户开启同步任务,数据开始按预期向目标端数据库按规则同步。
同步10分钟后,机房断网,此时数据同步任务处于重试阶段,mongodb 集群全部断开网络。
断开网络期间,mongodb 在进行的块迁移被迫终止。
一段时间后,网络恢复,数据同步自动重试机制保证用户无需人工干预,继续开始同步任务。
mongodb 继续开始块迁移。
发现没有,在第五步的时候,mongodb 的块迁移并没有去干预之前块迁移失败的结果,其实这么说不严谨,mongodb config server 上记录的元数据还是认为这个块在 shard1 上,而已经从 shard 1 节点 copy 到 shard 2 节点的数据并没有被删除。因此最终 count 出来的数据就会有大于原来数据总数的情况。
解决
那为了解决这个问题,其实官方是有预见的。给出了官方的解决方案。
这里我帮大家总结好了,执行下面这段脚本在各个分片节点上。
var nextKey = { };
vard result;
while ( nextKey != null ) {
result = db.adminCommand( { cleanupOrphaned: "<COLLECTION>", startingFromKey: nextKey } );
if (result.ok != 1)
print("Unable to complete at this time: failure or timeout.")
printjson(result);
nextKey = result.stoppedAtKey;
}这段脚本就在做一件事情:找出不属于 config 节点记录的数据标识范围,并将其删除。
总结
那通过这件事情,查看官方文档,我们总结了几点:
在使用数据同步工具迁移数据到 mongodb 分片集群的时候,需要作如下动作
- 停止平衡器:如何停止平衡器
- 使用cleanOrphan命令:如何清理孤儿文档
- 面对数据不一致性,排查思路可以从数据库、同步逻辑出发
- 专业的事交给专业的人做。
加载全部内容