Elasticsearch系列---并发控制及乐观锁实现原理
清茶豆奶 人气:4概要
本篇主要介绍一下Elasticsearch的并发控制和乐观锁的实现原理,列举常见的电商场景,关系型数据库的并发控制、ES的并发控制实践。
并发场景
不论是关系型数据库的应用,还是使用Elasticsearch做搜索加速的场景,只要有数据更新,并发控制是永恒的话题。
当我们使用ES更新document的时候,先读取原始文档,做修改,然后把document重新索引,如果有多人同时在做相同的操作,不做并发控制的话,就极有可能会发生修改丢失的。可能有些场景,丢失一两条数据不要紧(比如文章阅读数量统计,评论数量统计),但有些场景对数据严谨性要求极高,丢失一条可能会导致很严重的生产问题,比如电商系统中商品的库存数量,丢失一次更新,可能会导致超卖的现象。
我们还是以电商系统的下单环节举例,某商品库存100个,两个用户下单购买,都包含这件商品,常规下单扣库存的实现步骤
- 客户端完成订单数据校验,准备执行下单事务。
- 客户端从ES中获取商品的库存数量。
- 客户端提交订单事务,并将库存数量扣减。
- 客户端将更新后的库存数量写回到ES。
示例流程图如下:
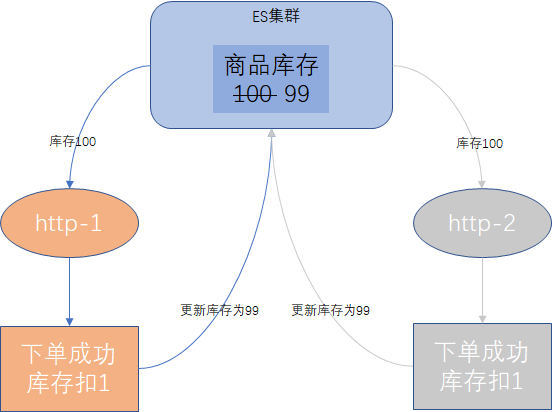
如果没有并发控制,这件商品的库存就会更新成99(实际正确的值是98),这样就会导致超卖现象。假定http-1比http-2先一步执行,出现这个问题的原因是http-2在获取库存数据时,http-1还未完成下单扣减库存后,更新到ES的环节,导致http-2获取的数据已经是过期数据,后续的更新肯定也是错的。
上述的场景,如果更新操作越是频繁,并发数越多,读取到更新这一段的耗时越长,数据出错的概率就越大。
常用的锁方案
并发控制尤为重要,有两种通用的方案可以确保数据在并发更新时的正确性。
悲观并发控制
悲观锁的含义:我认为每次更新都有冲突的可能,并发更新这种操作特别不靠谱,我只相信只有严格按我定义的粒度进行串行更新,才是最安全的,一个线程更新时,其他的线程等着,前一个线程更新完成后,下一个线程再上。
关系型数据库中广泛使用该方案,常见的表锁、行锁、读锁、写锁,依赖redis或memcache等实现的分布式锁,都属于悲观锁的范畴。明显的特征是后续的线程会被挂起等待,性能一般来说比较低,不过自行实现的分布式锁,粒度可以自行控制(按行记录、按客户、按业务类型等),在数据正确性与并发性能方面也能找到很好的折衷点。
乐观并发控制
乐观锁的含义:我认为冲突不经常发生,我想提高并发的性能,如果真有冲突,被冲突的线程重新再尝试几次就好了。
在使用关系型数据库的应用,也经常会自行实现乐观锁的方案,有性能优势,方案实现也不难,还是挺吸引人的。
Elasticsearch默认使用的是乐观锁方案,前面介绍的_version字段,记录的就是每次更新的版本号,只有拿到最新版本号的更新操作,才能更新成功,其他拿到过期数据的更新失败,由客户端程序决定失败后的处理方案,一般是重试。
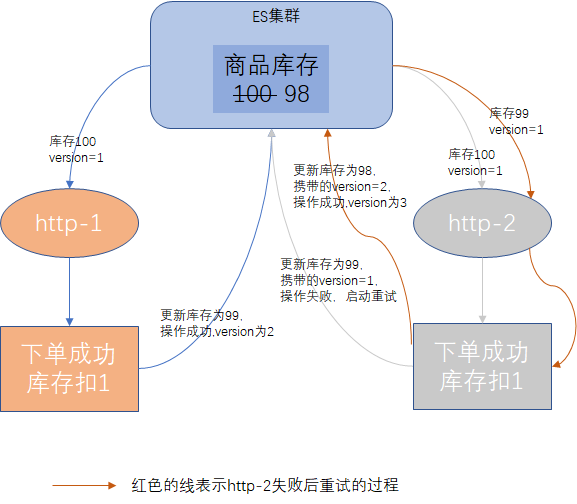
ES的乐观锁方案
我们还是以上面的案例为背景,若http-2向ES提交更新数据时,ES会判断提交过来的版本号与当前document版本号,document版本号单调递增,如果提交过来的版本号比document版本号小,则说明是过期数据,更新请求将提示错误,过程图如下:
使用内置_version实战乐观锁控制效果
我们在kibana平台上模拟两个线程修改同一条document数据,打开两个浏览器标签即可,我们使用原有的案例数据:
{
"_index": "music",
"_type": "children",
"_id": "2",
"_version": 2,
"found": true,
"_source": {
"name": "wake me, shark me",
"content": "don't let me sleep too late, gonna get up brightly early in the morning",
"language": "english",
"length": "55"
}
}当前的version是2,我们使用一个浏览器标签页,发出更新请求,把当前的version带上:
POST /music/children/2?version=2
{
"doc": {
"length": 56
}
}此时更新成功
{
"_index": "music",
"_type": "children",
"_id": "2",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 2
}同时我们在另一个标签页上,也使用version=2进行更新,得到的错误结果如下:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[children][2]: version conflict, current version [3] is different than the one provided [2]",
"index_uuid": "9759yb44TFuJSejo6boy4A",
"shard": "2",
"index": "music"
}
],
"type": "version_conflict_engine_exception",
"reason": "[children][2]: version conflict, current version [3] is different than the one provided [2]",
"index_uuid": "9759yb44TFuJSejo6boy4A",
"shard": "2",
"index": "music"
},
"status": 409
}关键错误信息:version_conflict_engine_exception,版本冲突,将version升到3,模拟失败后重试,此时更新成功。
真实的场景,重试的次数跟线程并发数有关,线程越多,更新越频繁,就可能需要重试多次才可能更新成功。
使用外部_version实战乐观锁控制效果
ES允许不使用内置的version进行版本控制,可以自定义使用外部的version,例如常见的使用Elasticsearch做数据查询加速的经典方案,关系型数据库作为主数据库,然后使用Elasticsearch做搜索数据,主数据会同步数据到Elasticsearch中,而主数据库并发控制,本身就是使用的乐观锁机制,有自己的一套version生成机制,数据同步到ES那里时,直接使用更方便。
请求语法上加上version_type参数即可:
POST /music/children/2?version=2&version_type=external
{
"doc": {
"length": 56
}
}唯一的区别
- 内置_version,只有当你提供的version与es中的_version完全一样的时候,才可以进行更新,否则报错;
- 外部_version,只有当你提供的version比es中的_version大的时候,才能完成修改。
Replica Shard数据同步并发控制
在Elasticsearch内部,每当primary shard收到新的数据时,都需要向replica shard进行数据同步,这种同步请求特别多,并且是异步的。如果同一个document进行了多次修改,Shard同步的请求是无序的,可能会出现"后发先至"的情况,如果没有任何的并发控制机制,那结果将无法相像。
Shard的数据同步也是基于内置的_version进行乐观锁并发控制的。
例如Java客户端向Elasticsearch某条document发起更新请求,共发出3次,Java端有严谨的并发请求控制,在ElasticSearch的primary shard中写入的结果是正确的,但Elasticsearch内部数据启动同步时,顺序不能保证都是先到先得,情况可能是这样,第三次更新请求比第二次更新请求先到,如下图:
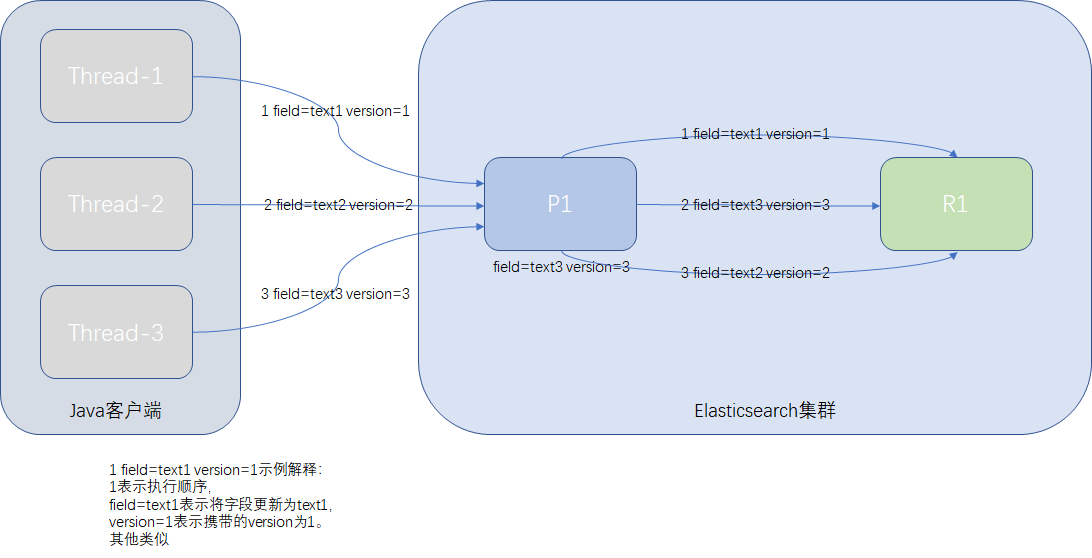
如果Elasticsearch内部没有并发的控制,这个document在replica的结果可能是text2,并且与primary shard的值不一致,这样肯定错了。
预期的更新顺序应该是text1-->text2-->text3,最终的正确结果是text3。那Elasticsearch内部是如何做的呢?
Elasticsearch内部在更新document时,会比较一下version,如果请求的version与document的version相等,就做更新,如果document的version已经大于请求的version,说明此数据已经被后到的线程更新过了,此时会丢弃当前的请求,最终的结果为text3。
此时的更新顺序为text1-->text3,最终结果也是对的。
小结
本篇主要介绍并发场景出现数据错乱的原因,Elasticsearch乐观锁的实原理,以及ES内部数据同步时的并发控制,有不正确之处或未详尽之处请知会修改,谢谢。
专注Java高并发、分布式架构,更多技术干货分享与心得,请关注公众号:Java架构社区

加载全部内容