学习下ElasticSearch
palapala 人气:1ElasticSearch基础概念
Elasticsearch的Head插件安装
Elasticsearch在Centos 7上的安装常见的问题
使用场景:比如分库的情况下,你想统计所有数据的报表,就把所有数据都放在ElasticSearch上
| 关系型数据库 | ElasticSearch |
| 数据库Database | 索引index,支持全文检索 |
| 表Table | 类型Type |
| 数据行Row | 文档Document |
| 数据列Column | 字段Field |
| 模式Schema | 映射Mapping |
用关系型数据库就会想到建立一张User表,再建字段等,
而在Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式
在ES6.0之后,已经不允许在一个index下建不同的Type了,一个index下只有一个Type(以后版本中Type概念会去掉,可以直接把index类比成Table)
节点Node:
一个ElasticSearch运行的实列,集群构成的单元
集群Cluster:
由一个或多个节点组成,对外提供服务
Elasticsearch实现原理-倒排索引
ElasticSearch是基于倒排索引实现的
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。
通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
倒排索引—单词词典
单词词典(Term Dictionary)是倒排索引的重要组成部分。
——记录所有文档的单词,一般都比较大
——记录单词到倒排列表的关联信息(这个单词关联了哪些文档)
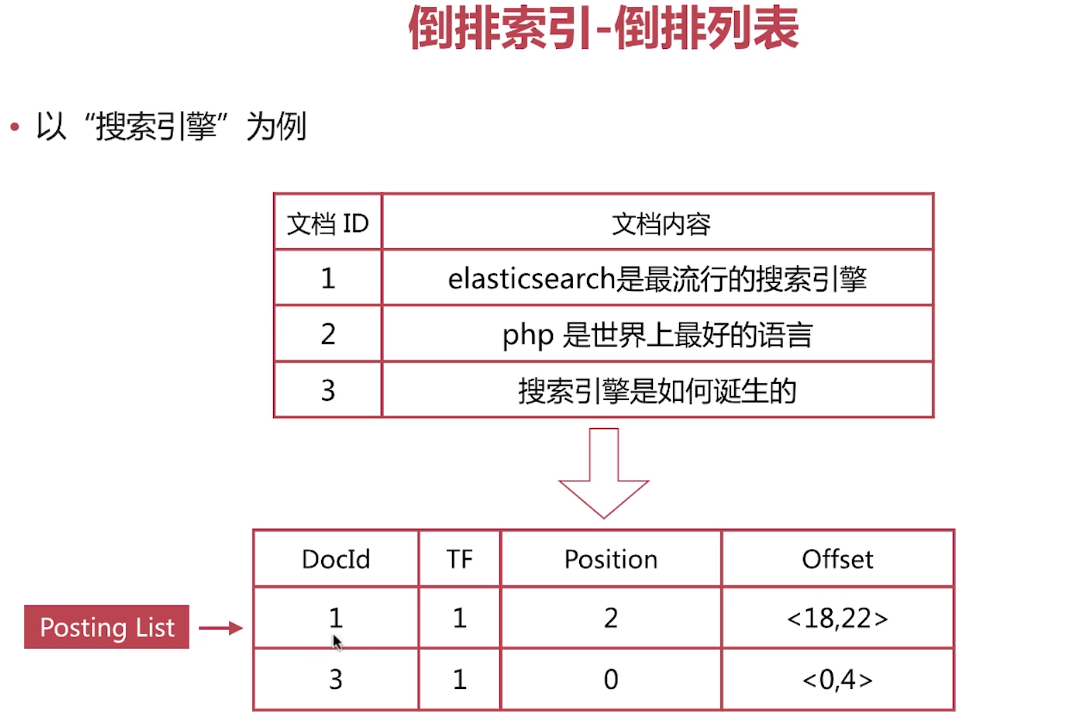
倒排索引—排序列表
倒排列表(Posting List)记录了单词对应文档的集合,由倒排索引项(Posting)组成
倒排索引项(Posting)主要包含如下信息
—文档Id,用于获取原始信息
—单词频率(TF,Term Frequency),记录该单词在文档中出现的次数,用于后序相关算分
—位置(Position),记录单词在文档中的分词位置,用于做词语搜索(Phrase Query)
—偏移(Offset),记录单词在文档的开始和结束位置,用于高亮显示
Elasticsearch分词
搜索引擎的核心是倒排索引,而倒排索引的基础就是分词。所谓分词可以简单理解为将一个完整的句子切割为一个个单词的过程。也可以叫文本分析,在es称为Analysis。
如文本:elasticSearch是最流行的搜索引擎
分词结果:elasticSearch 流行 搜索引擎
分词器是es中专门处理分词的组件,英文为Analyzer,它的组成如下
Character Filters:针对原始文本特殊处理,比如除html特殊符
Tokenizer:将原始文本按照一定规则切分为单词
TokenFilters:针对tokenizer处理的单词就行在加工,比如转小写,删除或新增处理(比如中文中的 这 呢 无实意的词)
Analyze API
es提供了一个测试分词的API接口,方便验证分词效果,endpoint是_analyze
—可以直接指定analyze测试
—可以直接指定索引中的字段进行测试
—可以自定义分词器进行测试
Elasticsearch文档映射Mapping
Mapping类似数据库中的表结构定义,主要作用如下:
—定义Index下的字段名(Field Name)
—定义字段的类型,比如数值型、字符串型、布尔型等
—定义倒排索引相关的配置,比如是否索引、记录position等
Dynamic Mapping
es可以自动识别文档字段类型,从而降低用户使用成本
SearchAPI介绍和相关性算分
es中存储的数据进行查询分析,endpoint为_search
查询主要有两种形式
1)URI Search
操作简单,方便通过命令进行测试
但 仅包含部分查询语法
GET /indexname/_search?q=user:xx
2)Request Body Search
es提供的完备查询语法Query DSL(Domain Specific Language)
GET /indexname/_search
{
"query": {
"term": {
"user": "xx"
}
}
}
相关算分
相关算分是指文档与查询语句直接的相关度,英文为relevance
通过倒排索引可以获取与查询语句相匹配的文档列表,那么如何将最符合用户查询的文档放到前列呢
本质是一个排序问题,排序的依据是相关算分
ES目前主要有两个相关性算分模型
TF/IDF模型
BM25模型 5.x之后的默认模型
BM25相比TF/IDF的一大优化是降低了TF(Term Frequency单词频率)在过大时的权重
相关算分是shard与shard间是相互独立的,也就意味着一个Term的IDF等值在不同shard上是不同的。文档的相关算分和它所处的shard有关
在文档数量不多时 会导致相关算分严重不准的情况发生
解决办法
—设置分片数是一个,从根本排除问题,在文档数据量不多时可以考虑该方法,(百万到千万)
—二是使用DFS Query Then Ftech查询方式
Elasticsearch分布式特性
es支持集群模式,是一个分布式系统,好处是
—1)增加系统容量:内存、磁盘,使es集群可以支持PB级的数据
如何将数据分布在所有节点上
—引入分片 Shard解决问题
分片是ES支持PB级数据的基石
—分片存储了部分数据,可以分部在任意节点上
—分片数在索引创建时指定且后序不允许再更改(即使你后面新增了也用不到),默认5个
—分片有主分片和副本分片之分,以实现数据的高可用
es集群由多个es实列组成
—不同集群通过集群名字来区分,可通过cluster.name修改,默认为elasticSearch
—每个ES实列本质是一个JVM进程,且有自己的名字,通过node.name修改
Master Node:Master节点通过集群中所有的节点选举产生,可以被选举的节点称为master-eligible节点,
相关配置如下:node.master:true
Coordinating Node:处理请求的节点为Coordinating节点,该节点为所有节点默认角色,不能取消
作用是把请求路由到正确的节点处理,比如创建索引请求到master节点
Data Node:存储数据的节点即为data节点,默认节点都是data类型,相关配置如下:node.data.true
—2)提供系统可用性:即部分节点停止服务,整个集群依然可以正常服务
提高系统可用性
服务可用性
—两个节点情况下,允许其中一个节点停止服务
数据可用性
—引入副本(Replication)解决
—每个节点上都有完备的数据
复制分片的意义在于容错性,当一个节点挂了,另一个节点上的分片可以代替挂掉节点上的分片
故障转移
 一:
一:

二:

三:

文档到分片的映射算法
es通过如下公式计算文档到对应的分片 -shard=hash(routing)%number_of_primary_shards
hash算法保证可以将数据均匀的分散在分片中
routing是一个关键参数,默认是文档id,也可以自行指定
number_of_primary_shards是主片分数(该算法与主片分数相关,这也是分片数量一旦确定就不能修改的原因)
脑裂问题
在上述第一步的时候 node2和node3选举node2为master节点了时候,此时会更新cluster state
此时node1节点网络恢复了,node1自己组成集群后,也会更新cluster state
此时:同一个集群有两个master,而且维护不同的cluster state,网络恢复后 无法选择正确的master
解决方案:仅在可选举master-eligible节点数大于等于quorum时才可以进行master选举
即使node1节点恢复了 ,可选节点数未达到quorum,不选举
加载全部内容