SpringBoot 怎样整合 ES 实现 CRUD 操作
空夜 人气:0本文介绍 Spring Boot 项目中整合 ElasticSearch 并实现 CRUD 操作,包括分页、滚动等功能。
之前在公司使用 ES,一直用的是前辈封装好的包,最近希望能够从原生的 Spring Boot/ES 语法角度来学习 ES 的相关技术。希望对大家有所帮助。
本文为 spring-boot-examples 系列文章节选,示例代码已上传至 https://github.com/laolunsi/spring-boot-examples
安装 ES 与可视化工具
前往 ES 官方 https://www.elastic.co/cn/downloads/elasticsearch 进行,如 windows 版本只需要下载安装包,启动 elasticsearch.bat 文件,浏览器访问 http://localhost:9200
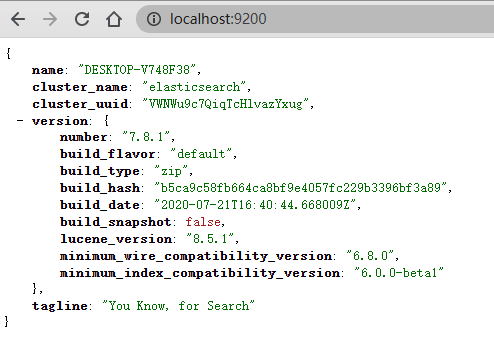
如此,表示 ES 安装完毕。
为更好地查看 ES 数据,再安装一下 elasticsearch-head 可视化插件。前往下载地址:https://github.com/mobz/elasticsearch-head
主要步骤:
- git clone git://github.com/mobz/elasticsearch-head.git
- cd elasticsearch-head
- npm install
- npm run start
- open http://localhost:9100/
可能会出现如下情况:
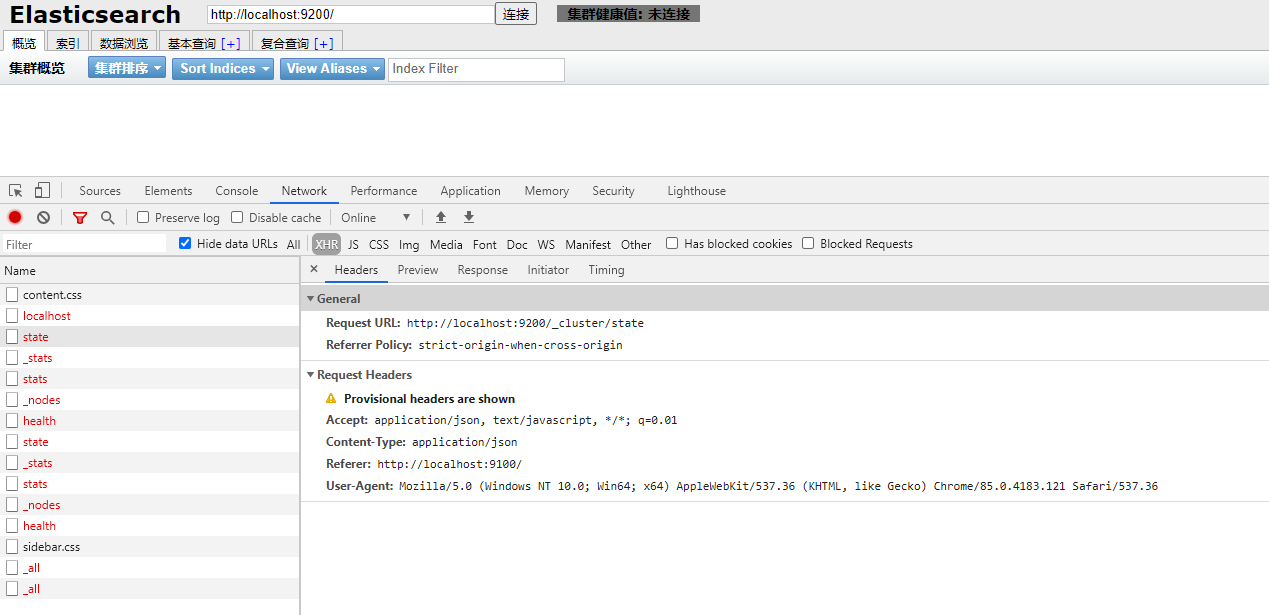
发现是跨域的问题。
解决办法是在 elasticsearch 的 config 文件夹中的 elasticsearch.yml 中添加如下两行配置:
http.cors.enabled: true http.cors.allow-origin: "*"
刷新页面:
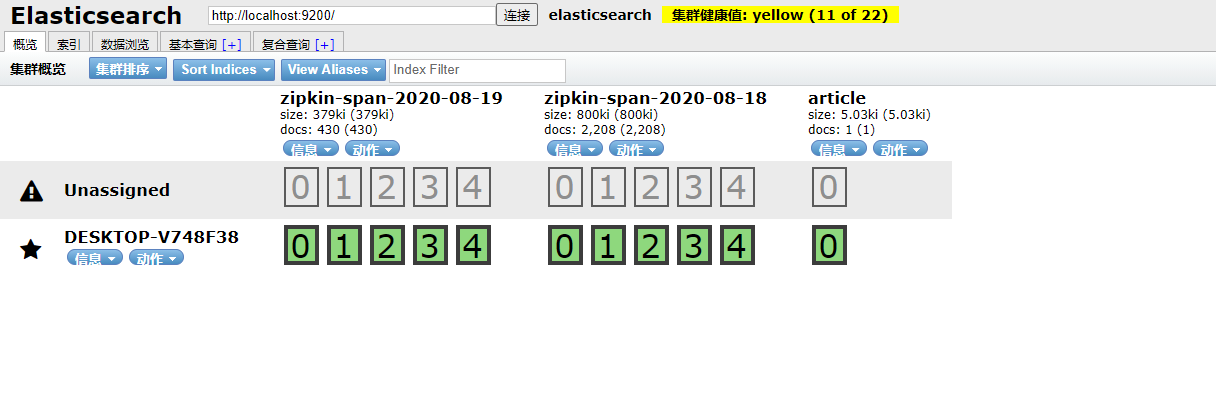
这里的 article 索引就是我通过 spring boot 项目自动创建的索引。
下面我们进入正题。
Spring Boot 引入 ES
创建一个 spring-boot 项目,引入 es 的依赖:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency>
配置 application.yml:
server: port: 8060 spring: elasticsearch: rest: uris: http://localhost:9200
创建一个测试的对象,article:
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import java.util.Date;
@Document(indexName = "article")
public class Article {
@Id
private String id;
private String title;
private String content;
private Integer userId;
private Date createTime;
// ... igonre getters and setters
}
下面介绍 Spring Boot 中操作 ES 数据的三种方式:
- 实现 ElasticsearchRepository 接口
- 引入 ElasticsearchRestTemplate
- 引入 ElasticsearchOperations
实现对应的 Repository:
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface ArticleRepository extends ElasticsearchRepository<Article, String> {
}
下面可以使用这个 ArticleRepository 来操作 ES 中的 Article 数据。
我们这里没有手动创建这个 Article 对应的索引,由 elasticsearch 默认生成。
下面的接口,实现了 spring boot 中对 es 数据进行插入、更新、分页查询、滚动查询、删除等操作。可以作为一个参考。其中,使用了 Repository 来获取、保存、删除 ES 数据,使用 ElasticsearchRestTemplate 或 ElasticsearchOperations 来进行分页/滚动查询。
根据 id 获取/删除数据
@Autowired
private ArticleRepository articleRepository;
@GetMapping("{id}")
public JsonResult findById(@PathVariable String id) {
Optional<Article> article = articleRepository.findById(id);
JsonResult jsonResult = new JsonResult(true);
jsonResult.put("article", article.orElse(null));
return jsonResult;
}
@DeleteMapping("{id}")
public JsonResult delete(@PathVariable String id) {
// 根据 id 删除
articleRepository.deleteById(id);
return new JsonResult(true, "删除成功");
}
保存数据
@PostMapping("")
public JsonResult save(Article article) {
// 新增或更新
String verifyRes = verifySaveForm(article);
if (!StringUtils.isEmpty(verifyRes)) {
return new JsonResult(false, verifyRes);
}
if (StringUtils.isEmpty(article.getId())) {
article.setCreateTime(new Date());
}
Article a = articleRepository.save(article);
boolean res = a.getId() != null;
return new JsonResult(res, res ? "保存成功" : "");
}
private String verifySaveForm(Article article) {
if (article == null || StringUtils.isEmpty(article.getTitle())) {
return "标题不能为空";
} else if (StringUtils.isEmpty(article.getContent())) {
return "内容不能为空";
}
return null;
}
分页查询数据
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Autowired
ElasticsearchOperations elasticsearchOperations;
@GetMapping("list")
public JsonResult list(Integer currentPage, Integer limit) {
if (currentPage == null || currentPage < 0 || limit == null || limit <= 0) {
return new JsonResult(false, "请输入合法的分页参数");
}
// 分页列表查询
// 旧版本的 Repository 中的 search 方法被废弃了。
// 这里采用 ElasticSearchRestTemplate 或 ElasticsearchOperations 来进行分页查询
JsonResult jsonResult = new JsonResult(true);
NativeSearchQuery query = new NativeSearchQuery(new BoolQueryBuilder());
query.setPageable(PageRequest.of(currentPage, limit));
// 方法1:
SearchHits<Article> searchHits = elasticsearchRestTemplate.search(query, Article.class);
// 方法2:
// SearchHits<Article> searchHits = elasticsearchOperations.search(query, Article.class);
List<Article> articles = searchHits.getSearchHits().stream().map(SearchHit::getContent).collect(Collectors.toList());
jsonResult.put("count", searchHits.getTotalHits());
jsonResult.put("articles", articles);
return jsonResult;
}
滚动查询数据
@GetMapping("scroll")
public JsonResult scroll(String scrollId, Integer size) {
// 滚动查询 scroll api
if (size == null || size <= 0) {
return new JsonResult(false, "请输入每页查询数");
}
NativeSearchQuery query = new NativeSearchQuery(new BoolQueryBuilder());
query.setPageable(PageRequest.of(0, size));
SearchHits<Article> searchHits = null;
if (StringUtils.isEmpty(scrollId)) {
// 开启一个滚动查询,设置该 scroll 上下文存在 60s
// 同一个 scroll 上下文,只需要设置一次 query(查询条件)
searchHits = elasticsearchRestTemplate.searchScrollStart(60000, query, Article.class, IndexCoordinates.of("article"));
if (searchHits instanceof SearchHitsImpl) {
scrollId = ((SearchHitsImpl) searchHits).getScrollId();
}
} else {
// 继续滚动
searchHits = elasticsearchRestTemplate.searchScrollContinue(scrollId, 60000, Article.class, IndexCoordinates.of("article"));
}
List<Article> articles = searchHits.getSearchHits().stream().map(SearchHit::getContent).collect(Collectors.toList());
if (articles.size() == 0) {
// 结束滚动
elasticsearchRestTemplate.searchScrollClear(Collections.singletonList(scrollId));
scrollId = null;
}
if (scrollId == null) {
return new JsonResult(false, "已到末尾");
} else {
JsonResult jsonResult = new JsonResult(true);
jsonResult.put("count", searchHits.getTotalHits());
jsonResult.put("size", articles.size());
jsonResult.put("articles", articles);
jsonResult.put("scrollId", scrollId);
return jsonResult;
}
}
ES 深度分页 vs 滚动查询
上次遇到一个问题,同事跟我说日志检索的接口太慢了,问我能不能优化一下。开始使用的是深度分页,即 1,2,3..10, 这样的分页查询,查询条件较多(十多个参数)、查询数据量较大(单个日志索引约 2 亿条数据)。
分页查询速度慢的原因在于:ES 的分页查询,如查询第 100 页数据,每页 10 条,是先从每个分区 (shard,一个索引默认是 5 个 shard) 中把命中的前 100 * 10 条数据查出来,然后由协调节点进行合并等操作,最后给出第 100 页的数据。也就是说,实际被加载到内存中的数据远超过理想情况。
这样,索引的 shard 越大,查询页数越多,查询速度就越慢。
ES 默认的 max_result_window 是 10000 条,也就是正常情况下,用分页查询到 10000 条数据时,就不会再返回下一页数据了。
如果不需要进行跳页,比如直接查询第 100 页数据,或者数据量非常大,那么可以考虑用 scroll 查询。
在 scroll 查询下,第一次需要根据查询参数开启一个 scroll 上下文,设置上下文缓存时间。以后的滚动只需要根据第一次返回的 scrollId 来进行即可。
scroll 只支持往下滚动,如果想要往回滚动,还可以根据 scrollId 缓存查询结果,这样就可以实现上下滚动查询了 —— 就像大家经常使用的淘宝商品检索时上下滚动一样。
加载全部内容