scrapy利用selenium爬取豆瓣阅读的全步骤
工藤新二z 人气:0本文着重给大家讲解了关于scrapy利用selenium爬取豆瓣阅读的相关资料,文中通过代码实例讲解的非常细致,对大家的工作和学习具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
首先创建scrapy项目
命令:scrapy startproject douban_read
创建spider
命令:scrapy genspider douban_spider url
网址:https://read.douban.com/charts
关键注释代码中有,若有不足,请多指教
scrapy项目目录结构如下

douban_spider.py文件代码
爬虫文件
import scrapy
import re, json
from ..items import DoubanReadItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# allowed_domains = ['www']
start_urls = ['https://read.douban.com/charts']
def parse(self, response):
# print(response.text)
# 获取图书分类的url
type_urls = response.xpath('//div[@class="rankings-nav"]/a[position()>1]/@href').extract()
# print(type_urls)
for type_url in type_urls:
# /charts?type=unfinished_column&index=featured&dcs=charts&dcm=charts-nav
part_param = re.search(r'charts\?(.*?)&dcs', type_url).group(1)
# https://read.douban.com/j/index//charts?type=intermediate_finalized&index=science_fiction&verbose=1
ajax_url = 'https://read.douban.com/j/index//charts?{}&verbose=1'.format(part_param)
yield scrapy.Request(ajax_url, callback=self.parse_ajax, encoding='utf-8', meta={'request_type': 'ajax'})
def parse_ajax(self, response):
# print(response.text)
# 获取分类中图书的json数据
json_data = json.loads(response.text)
for data in json_data['list']:
item = DoubanReadItem()
item['book_id'] = data['works']['id']
item['book_url'] = data['works']['url']
item['book_title'] = data['works']['title']
item['book_author'] = data['works']['author']
item['book_cover_image'] = data['works']['cover']
item['book_abstract'] = data['works']['abstract']
item['book_wordCount'] = data['works']['wordCount']
item['book_kinds'] = data['works']['kinds']
# 把item yield给Itempipeline
yield item
item.py文件代码
项目的目标文件
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class DoubanReadItem(scrapy.Item): # define the fields for your item here like: book_id = scrapy.Field() book_url = scrapy.Field() book_title = scrapy.Field() book_author = scrapy.Field() book_cover_image = scrapy.Field() book_abstract = scrapy.Field() book_wordCount = scrapy.Field() book_kinds = scrapy.Field()
my_download_middle.py文件代码
所有request都会经过下载中间件,可以通过定制中间件,来完成设置代理,动态设置请求头,自定义下载等操作
import random
import time
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from scrapy.http.response.html import HtmlResponse
class MymiddleWares(object):
def __init__(self):
# 请求头列表
self.USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
def process_request(self, request, spider):
'''
下载中间件处理requests的方法
:param request:马上要被下载器下载request
:param spider:
:return:
'''
# 在spider中设置了meta的request_type的值为ajax meta参数会贯穿整个scrapy
request_type = request.meta.get('request_type')
# 如果不是ajax请求就需要通过selenium来自定义下载request
if not request_type:
print('in middler')
# 1、创建driver
driver = webdriver.Chrome()
# 2、请求url
driver.get(request.url)
# 3、等待
# driver.implicitly_wait(20)
time.sleep(3)
# 4、获取页面内容
html_str = driver.page_source
# 直接返回HtmlResponse给spider解析 下载器就不会下载这个request 达到自定义下载的目的
return HtmlResponse(url=request.url, body=html_str, request=request, encoding='utf-8')
else:
# 如果是ajax请求就需要通过scrapy下载器来下载request
# ajax请求直接返回json数据不适合上面的selenium下载
ua = random.choice(self.USER_AGENT_LIST)
# 设置请求头
if ua:
request.headers.setdefault('User-Agent', ua)
request.headers.setdefault('X-Requested-With', 'XMLHttpRequest')
pipeline.py文件代码
项目的管道文件
import pymongo
from itemadapter import ItemAdapter
class MongoPipeline:
# 存储集合名字
collection_name = 'book'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
'''
当spider启动的时候调用
:param spider:
:return:
'''
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
# 保存到mongo的douban_read数据库下的book集合中
def process_item(self, item, spider):
self.db[self.collection_name].update({'book_id': item['book_id']}, {'$set': dict(item)}, True)
# True:有则修改 无则新增
print(item)
return item
settings.py文件代码
配置信息
# Scrapy settings for douban_read project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'douban_read'
SPIDER_MODULES = ['douban_read.spiders']
NEWSPIDER_MODULE = 'douban_read.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'douban_read (+http://www.yourdomain.com)'
# Obey robots.txt rules
# robot协议
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
# 默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'douban_read.middlewares.DoubanReadSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# 配置下载器中间件
DOWNLOADER_MIDDLEWARES = {
'douban_read.my_download_middle.MymiddleWares': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# 配置ITEM_PIPELINES
ITEM_PIPELINES = {
'douban_read.pipelines.MongoPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# 配置mongo
MONGO_URI = 'localhost'
# 创建数据库:douban_read
MONGO_DATABASE = 'douban_read'
最后启动该项目即可
scrapy crawl douban_spider
数据就保存到mongo数据库了
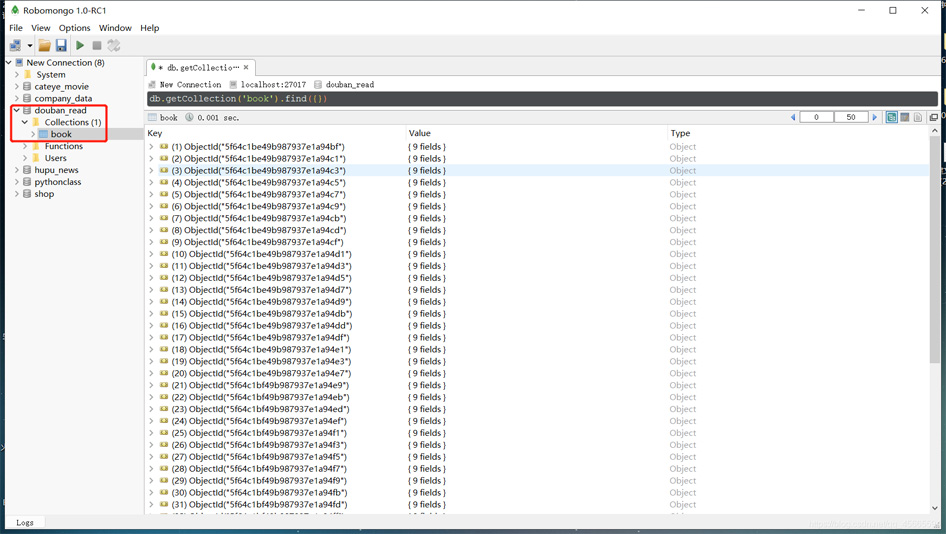
总结
加载全部内容