人工智能中小样本问题相关的系列模型演变及学习笔记(含元学习/小样本学习/生成对抗网络/迁移学习等)
FinTecher 人气:1【说在前面】本人博客新手一枚,象牙塔的老白,职业场的小白。以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手]
【再啰嗦一下】本来只想记一下GAN的笔记,没想到发现了一个大宇宙,很多个人并不擅长,主要是整理归纳!
一、Meta Learning 元学习综述
Meta Learning,又称为 learning to learn,已经成为继 Reinforcement Learning 之后又一个重要的研究分支。
元学习区别于机器学习的是:机器学习通常是在拟合一个数据的分布,而元学习是在拟合一系列相似任务的分布。
本节主要参考了大佬的知乎专栏:https://zhuanlan.zhihu.com/p/28639662
推荐Stanford助理教授Chelsea Finn开设的CS330 multitask and meta learning课程
- 在 Machine Learning 机器学习时代,对于复杂一点的分类问题,模型效果就不好了。
- Deep Learning 深度学习解决了一对一映射问题,但如果输出对下一个输入有影响,也就是sequential decision making问题,单一的深度学习就解决不了了。
- Deep Reinforcement Learning 深度强化学习对序列决策取得成效,但深度强化学习太依赖于巨量的训练,并且需要精确的Reward。
- 人类之所以能够快速学习的关键是人类具备学会学习的能力,能够充分利用以往的知识经验来指导新任务的学习,因此 Meta Learning 成为新的攻克方向。
1. 基本概念
元学习是要去学习任务中的特征表示,从而在新的任务上泛化。举个例子,以下图的图像分类来说,元学习的训练过程是在task1和task2上训练模型(更新模型参数),而在训练样本中的训练集一般称作support set,训练样本中的测试集一般叫做query set。测试过程是在测试任务上评估模型好坏,从图中可以看出,测试任务和训练任务内容完全不同。
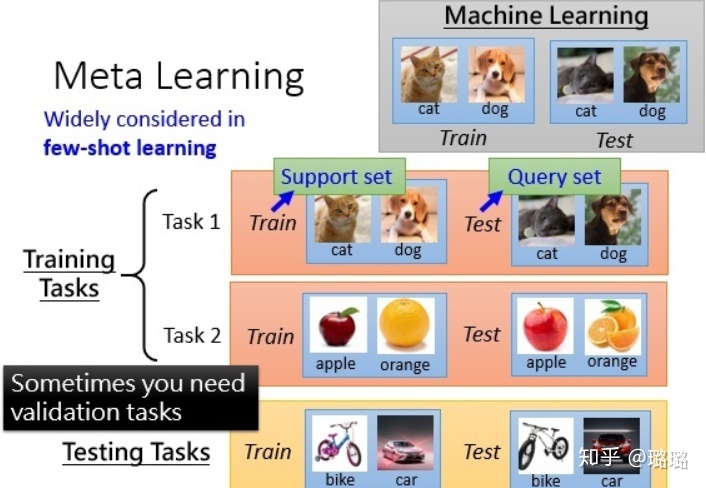
元学习解决的是学习如何学习的问题,元学习的思想是学习「学习(训练)」过程。元学习主要包括Zero-Shot/One-Shot/Few-Shot 学习、模型无关元学习(Model Agnostic Meta Learning)和元强化学习(Meta Reinforcement Learning)等。
- Zero-shot Learing 就是训练样本里没有这个类别的样本,但是如果我们可以学到一个牛逼的映射,这个映射好到我们即使在训练的时候没看到这个类,但是我们在遇到的时候依然能通过这个映射得到这个新类的特征。
- One-shot Learing 就是类别下训练样本只有一个或者很少,我们依然可以进行分类。比如我们可以在一个更大的数据集上或者利用knowledge graph、domain-knowledge 等方法,学到一个一般化的映射,然后再到小数据集上进行更新升级映射。
- Few-Shot Learing 的综述将在下一节重点整理,这里暂时不展开介绍。
元学习的主要方法包括基于记忆Memory的方法、基于预测梯度的方法、利用Attention注意力机制的方法、借鉴LSTM的方法、面向RL的Meta Learning方法、利用WaveNet的方法、预测Loss的方法等。
2. 基于记忆Memory的方法
基本思路:既然要通过以往的经验来学习,那么是不是可以通过在神经网络上添加Memory来实现呢?
代表方法包括:Meta-learning with memory-augmented neural networks、Meta Networks等。
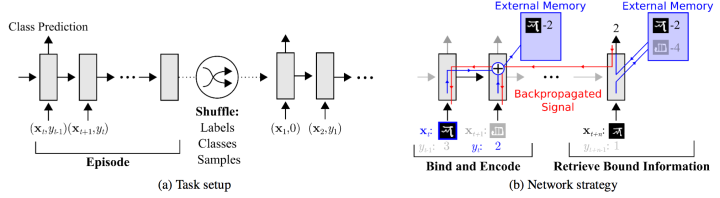
可以看到,网络的输入把上一次的y label也作为输入,并且添加了external memory存储上一次的x输入,这使得下一次输入后进行反向传播时,可以让y label和x建立联系,使得之后的x能够通过外部记忆获取相关图像进行比对来实现更好的预测。
3. 基于预测梯度的方法
基本思路:既然Meta Learning的目的是实现快速学习,而快速学习的关键一点是神经网络的梯度下降要准,要快,那么是不是可以让神经网络利用以往的任务学习如何预测梯度,这样面对新的任务,只要梯度预测得准,那么学习得就会更快了?
代表方法包括:Learning to learn by gradient descent by gradient descent 等。
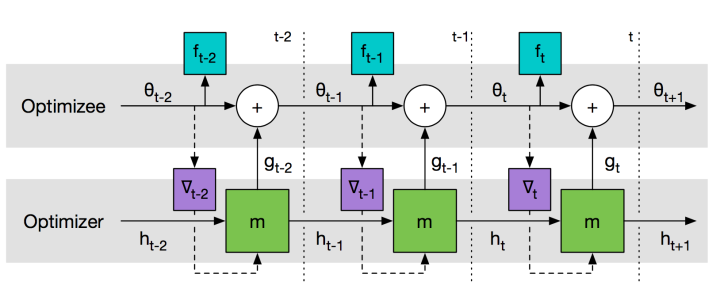
该方法训练一个通用的神经网络来预测梯度,用一次二次方程的回归问题来训练,优化器效果比Adam、RMSProp好,显然就加快了训练。
4. 利用Attention注意力机制的方法
基本思路:人的注意力是可以利用以往的经验来实现提升的,比如我们看一个性感图片,我们会很自然的把注意力集中在关键位置。那么,能不能利用以往的任务来训练一个Attention模型,从而面对新的任务,能够直接关注最重要的部分。
代表方法包括:Matching networks for one shot learning 等。
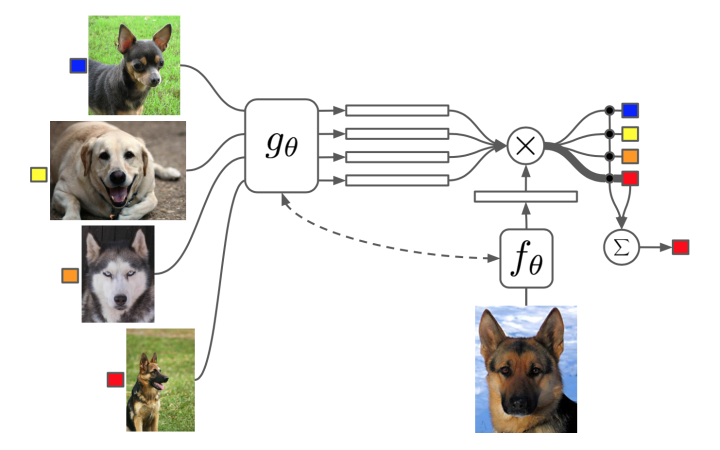
这篇文章构造一个attention机制,也就是最后的label判断是通过attention的叠加得到的:

attention a 则通过 g 和 f 得到。基本目的就是利用已有任务训练出一个好的attention model。
5. 借鉴LSTM的方法
基本思路:LSTM内部的更新非常类似于梯度下降的更新,那么,能否利用LSTM的结构训练出一个神经网络的更新机制,输入当前网络参数,直接输出新的更新参数?
代表方法包括:Optimization as a model for few-shot learning 等。
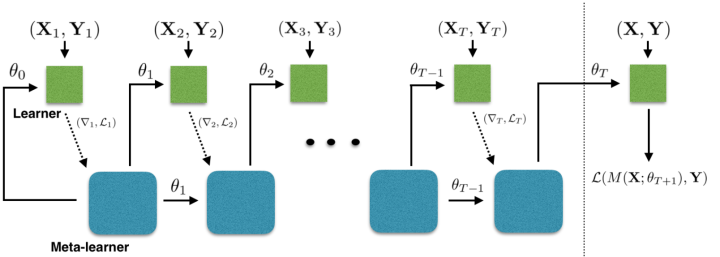
这篇文章的核心思想是下面这一段:

怎么把LSTM的更新和梯度下降联系起来才是更值得思考的问题吧。
6. 面向RL的Meta Learning方法
基本思路:Meta Learning可以用在监督学习,那么增强学习上怎么做呢?能否通过增加一些外部信息比如reward,之前的action来实现?
代表方法包括:Learning to reinforcement learn、Rl2: Fast reinforcement learning via slow reinforcement learning 等。
两篇文章思路一致,就是额外增加reward和之前action的输入,从而强制让神经网络学习一些任务级别的信息:
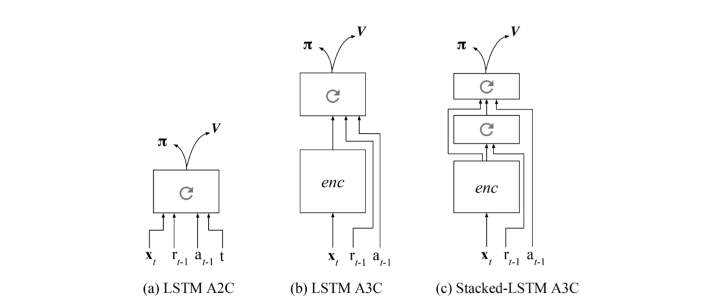
7. 通过训练一个好的base model的方法,并且同时应用到监督学习和强化学习
基本思路:之前的方法都只能局限在监督学习或强化学习上,能搞个更通用的?是不是相比finetune学习一个更好的base model就能work?
主要方法包括:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks 等。
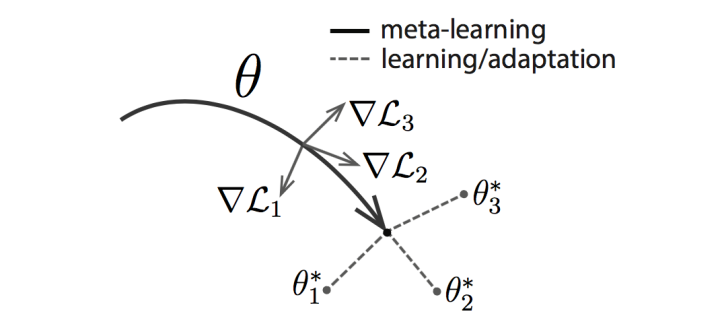
这篇文章的基本思路是同时启动多个任务,然后获取不同任务学习的合成梯度方向来更新,从而学习一个共同的最佳base。
8. 利用WaveNet的方法
基本思路:WaveNet的网络每次都利用了之前的数据,是否可以照搬WaveNet的方式来实现Meta Learning呢?就是充分利用以往的数据呀?
主要方法包括:Meta-Learning with Temporal Convolutions 等。
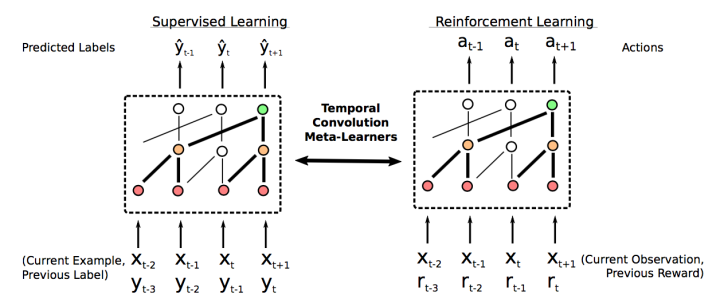
直接利用之前的历史数据,思路极其简单,效果极其之好,是目前omniglot,mini imagenet图像识别的state-of-the-art。
9. 预测Loss的方法
基本思路:要让学习的速度更快,除了更好的梯度,如果有更好的loss,那么学习的速度也会更快,因此,是不是可以构造一个模型利用以往的任务来学习如何预测Loss呢?
主要方法包括:Learning to Learn: Meta-Critic Networks for Sample Efficient Learning 等。
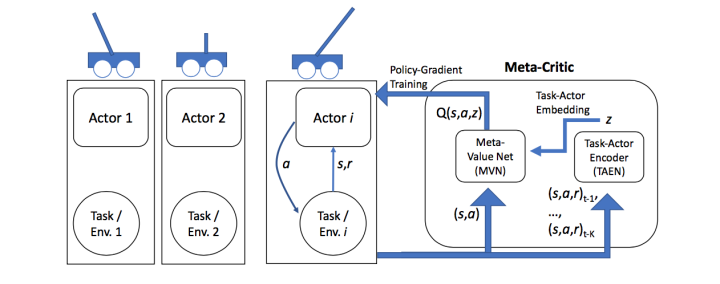
本文构造了一个Meta-Critic Network(包含Meta Value Network和Task-Actor Encoder)来学习预测Actor Network的Loss。对于Reinforcement Learning而言,这个Loss就是Q Value。
10. 小结
这是两年前的综述了,但是感觉质量很高。当然,后续又有了一些新进展。在应用上,元学习应用到了更广泛的问题上,例如小样本图像分类、视觉导航、机器翻译和语音识别等。在算法上,最值得一提的应该就是元强化学习,因为这样的结合将有望使智能体能够更快速地学习新的任务,这个能力对于部署在复杂和不断变化的世界中的智能体来说是至关重要的。
具体的,以上关于元学习的论文已经介绍了在策略梯度(policy gradient)和密集奖励(dense rewards)的有限环境中将元学习应用于强化学习的初步结果。此后,很多学者对这个方法产生了浓厚的兴趣,也有更多论文展示了将元学习理念应用到更广泛的环境中,比如:从人类演示中学习、模仿学习以及基于模型的强化学习。除了元学习模型参数外,还考虑了超参数和损失函数。为了解决稀疏奖励设置问题,也有了一种利用元学习来探索策略的方法。
尽管取得了这些进展,样本效率仍然是一项挑战。当考虑将 meta-RL 应用于实际中更复杂的任务时,快速适应这些任务则需要更有效的探索策略。因此在实际学习任务中,需要考虑如何解决元训练样本效率低下的问题。因此,伯克利 AI 研究院基于这些问题进行了深入研究,并开发了一种旨在解决这两个问题的算法。
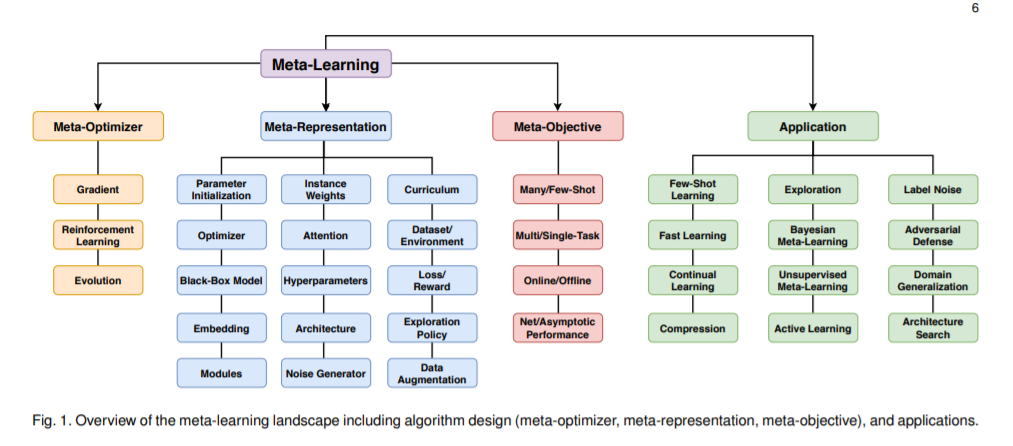
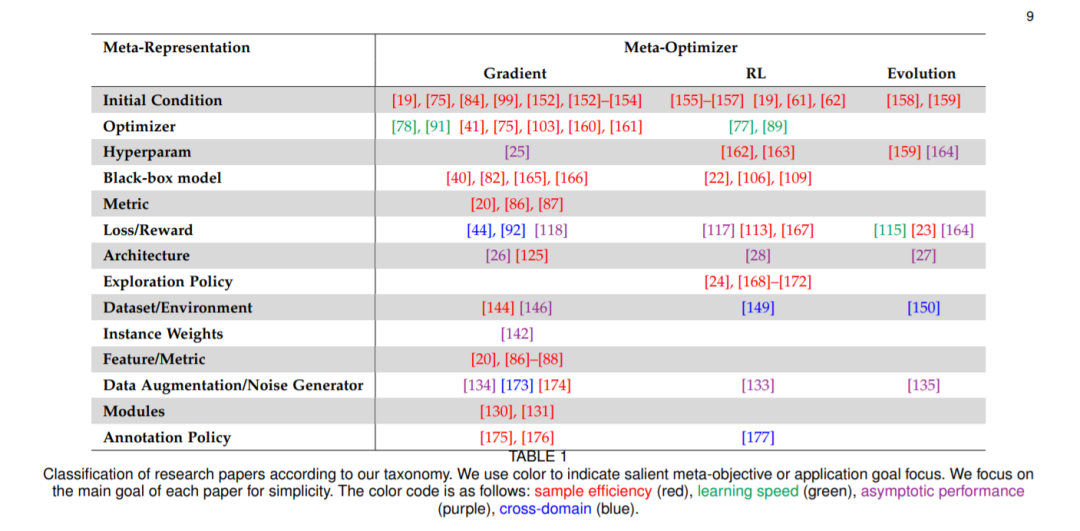
最后分享看到的元学习 meta learning 的2020综述论文。提出了一个新的分类法,对元学习方法的空间进行了更全面的细分:[认真看图]
论文标题:Meta-Learning in Neural Networks: A Survey
论文链接:https://arxiv.org/abs/2004.05439
二、Few-shot Learning 小样本学习综述
Few-shot Learning 可以说是 元学习 Meta Learning 在监督学习领域的一个应用,当然也有它自己研究领域的东西。
本节来自香港科技大学和第四范式的综述:Generalizing from a Few Examples: A Survey on Few-Shot Learning
该综述已被 ACM Computing Surveys 接收,还建立了 GitHub repo,持续更新:https://github.com/tata1661/FewShotPapers
1. 基本概念
机器学习在数据密集型应用中非常成功,但当数据集很小时,它常常受到阻碍。为了解决这一问题,近年来提出了小样本学习(FSL)。利用先验知识,FSL可以快速地泛化到只包含少量有监督信息的样本的新任务中。
大多数人认为FSL就是 meta learning,其实不是。FSL可以是各种形式的学习(例如监督、半监督、强化学习、迁移学习等),本质上的定义取决于可用的数据。但现在大多数时候在解决FSL任务时,采用的都是 meta Learning 的一些方法。
基于各个方法利用先验知识处理核心问题的方式,该综述将 FSL 方法分为三大类:
- 数据:利用先验知识增强监督信号
- 模型:利用先验知识缩小假设空间的大小
- 算法:利用先验知识更改给定假设空间中对最优假设的搜索
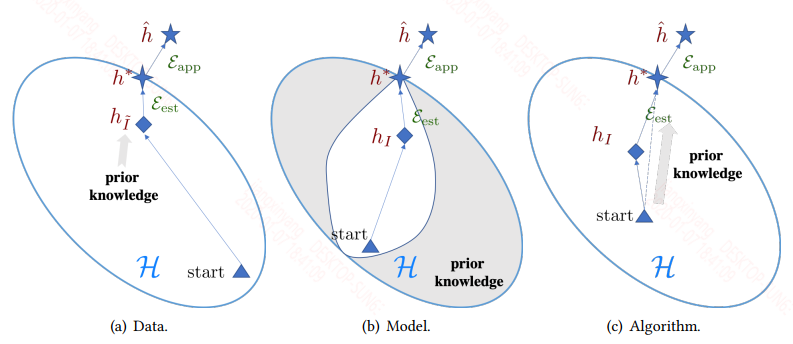
基于此,该综述将现有的 FSL 方法纳入此框架,得到如下分类体系:
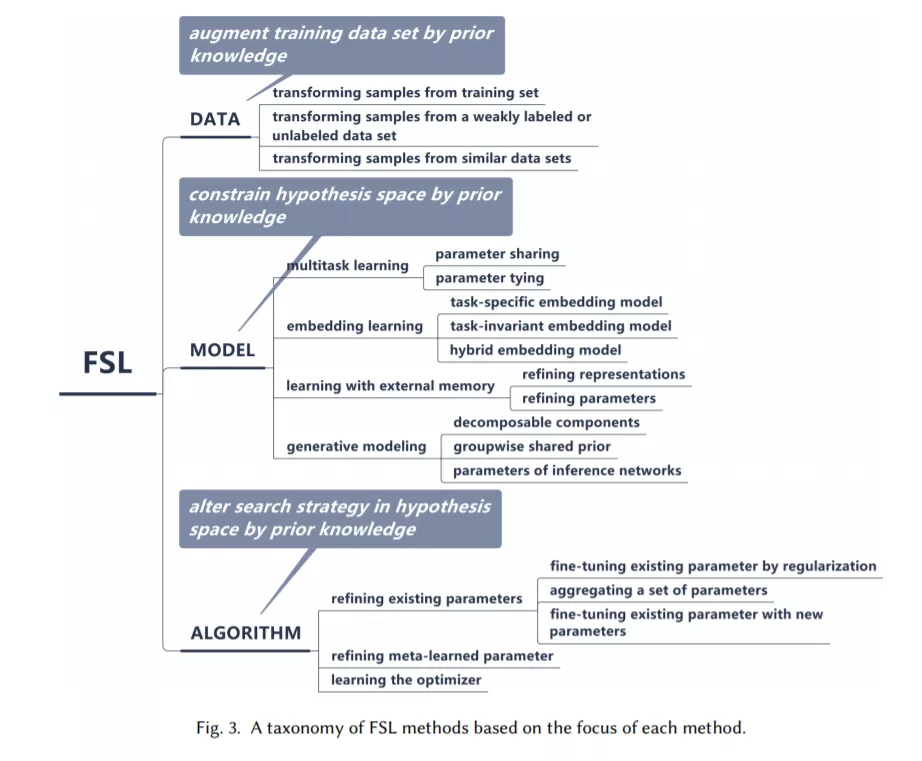
2. DATA
数据增强的方式有很多种,平时也被使用的比较多,在这里作者将数据增强的方法概括成三类:
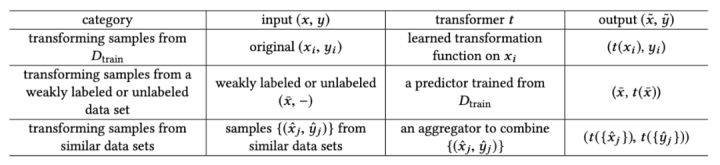
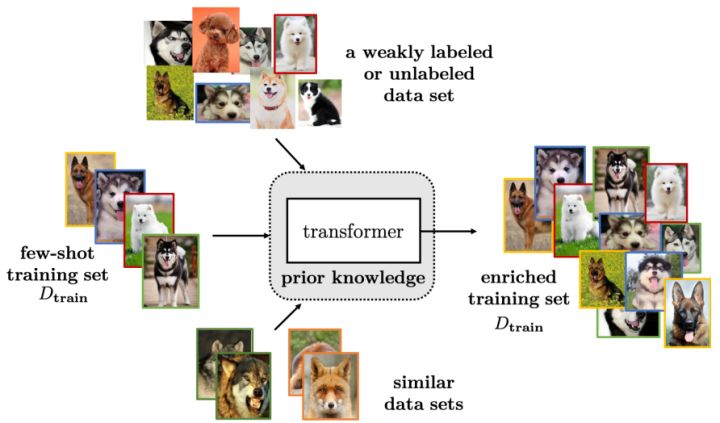
总之,数据增强没有什么神秘感,可以是手动在数据上修改(例如图片的旋转、句子中的同义词替换等),也可以是复杂的生成模型(生成和真实数据相近的数据)。数据增强的方式有很多种,大量合适的增强一定程度上可以缓解FSL问题,但其能力还是有限的。
3. MODEL
和模型剪枝中的理念类似,你一开始给一个小的模型,这个模型空间离真实假设太远了。而你给一个大的模型空间,它离真实假设近的概率比较大,然后通过先验知识去掉哪些离真实假设远的假设。
作者根据使用不同的先验知识将MODEL的方法分成4类:

3.1 Multitask Learning
对于多个共享信息的任务(例如数据相同任务不同、数据和任务都不同等),都可以用多任务学习来训练。
多任务分为硬参数共享和软参数共享两种模式:
- 硬参数共享认为任务之间的假设空间是有部分重叠的,体现在模型上就是有部分参数是共享的。而共享的参数可以是模型的前面一些层,表征任务的低阶信息。也可以是在嵌入层之后,不同的嵌入层将不同任务嵌入到同一不变任务空间,然后共享模型参数等。
- 软参数共享不再显示的共享模型参数,而是让不同的任务的参数相似。这就可以通过不同任务的参数正则,或者通过损失来影响参数的相似,以此让不同任务的假设空间类似。
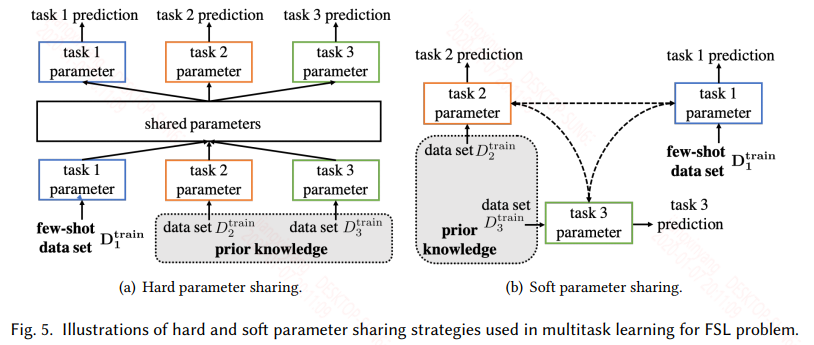
多任务通过多个任务来限制模型的假设空间:
- 对于硬参数共享,多个任务会有一个共享的假设空间,然后每个任务还有自己特定的假设空间。
- 对于软参数共享也类似,软参数更灵活,但也需要精心设计。
3.2 Embedding Learning
嵌入学习很好理解,将训练集中所有的样本通过一个函数 f 嵌入到一个低维可分的空间Z,然后将测试集中的样本通过一个函数 g 嵌入到这个低维空间Z,然后计算测试样本和所有训练样本的相似度,选择相似度最高的样本的标签作为测试样本的标签。
根据task-specific和task-invariant,以及两者的结合可以分为三种,嵌入学习如下:
- Task-specific是在任务自身的训练集上训练的,通过构造同类样本相同,不同类样本不同的样本对作为数据集,这样数据集会有一个爆炸式的扩充,可以提高样本的复杂度,然后可以用如siamese network等来训练。
- Task-invariant是在一个大的且和任务相似的source数据集上训练一个嵌入模型,然后直接用于当前任务的训练集和测试集嵌入。
- 实际上现在用的比较多的还是两者的结合,既可以利用大的通用数据集学习通用特征,又可以在特定任务上学习特定的特征,而现在常用的训练模式是meta learning中的metric-based的方式,此类常见的模型有match network、prototypical network、relation network等。
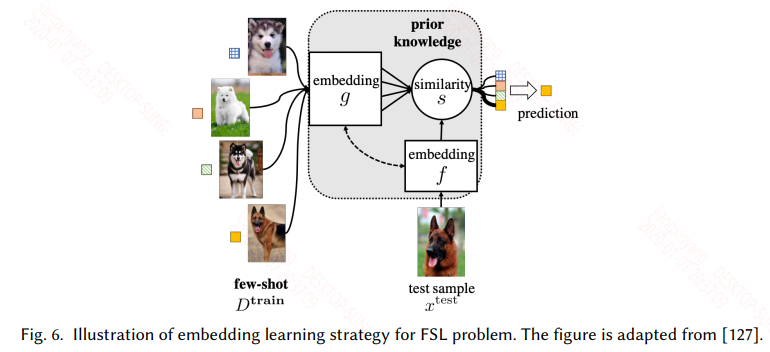
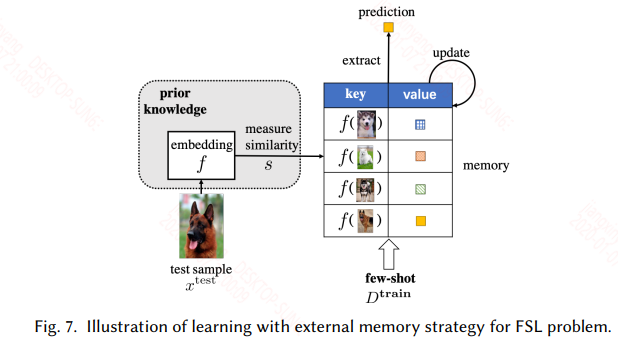
3.3 Learning with External Memory
具有外部存储机制的网络都可以用来处理这一类问题,其实本质上和迁移学习一样。只不过这里不更新模型的参数,只更新外部记忆库。外部记忆库一般都是一个矩阵,如神经图灵机,其外部记忆库具有读写操作。
在这里就是在一个用大量类似的数据训练的具有外部存储机制的网络上,用具体task的样本来更新外部记忆库。这类方法需要精心设计才能有好的效果,比如外部记忆库写入或更新的规则可能就影响模型能够在当前任务上的表现。具体的如下图所示:
3.4 Generative Modeling
引入了生成式的模型来解FSL问题。
4. ALGORITHM
在机器学习中,通常使用SGD及其变体(例如ADAM、RMSProp等)来寻找最优参数。但是在FSL中,样本数量很少,这种方法就失效了。
在这一节,我们不再限制假设空间。根据使用不同的先验知识,可以将ALGORITHM分为下面3类:

4.1 Refine Existing Parameters
本质就是pretrained + fine-tuning的模式,最常见的就是直接在pre-trianed的模型上直接fine-tuning参数,还可以在一个新的网络上使用pre-trained的部分参数来初始化等。
4.2 Refine Meta-learned Parameters
该小节是基于 meta learning 的解决方法,利用元学习器学习一个好的初始化参数。之后在新的任务上,只要对这个初始化参数少量迭代更新就能很好的适应新的任务。这种方法最经典的模型就是MAML,MAML的训练模式如下图所示:
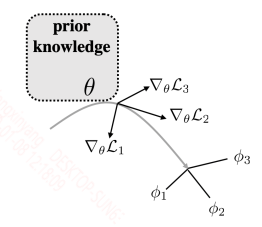
上面的参数是元学习器的参数,最后用多个任务的梯度矢量和来更新参数。这样的方式也有一个问题,就是新的任务的特性必须要和元训练中的任务相近,这样值才能作为一个较好的初始化值,否则效果会很差。因此,也就有不少研究在根据新任务的数据集来动态的生成一个适合它的初始化参数。
4.3 Learn Search Steps
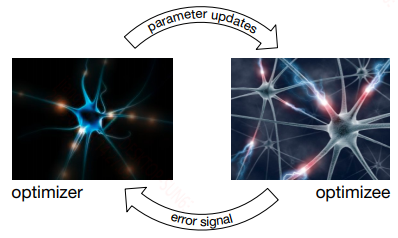
上一节使用元学习来获得一个较好的初始化参数,而本节旨在用元学习来学习一个参数更新的策略。针对每一个子任务能给定特定的优化方式实际上是提高性能的唯一方法,这里就是设计一个元优化器来为特定的任务提供特定的优化方法,具体的如下图所示:
梯度的更新也可以写成:
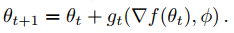
在这里使用RNN来实现,因为RNN具有时序记忆功能,而梯度迭代的过程中正好是一个时序操作。具体的训练如下图所示:
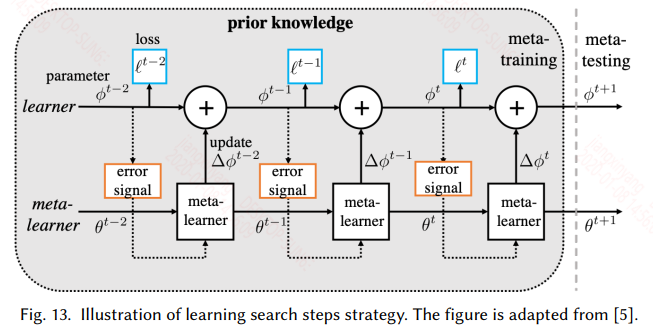
训练过程大致如下:
- 对于每个任务,同样划分训练集和测试集,训练集经过meta-learner得到一系列的梯度,因为RNN每个时刻都有输出,因此每个时刻的梯度都去依次更新learner的参数ϕ。这样看就相当于一个batch的样本就更新了T次learner
- 训练完一轮之后,用测试集在learner上的到的梯度来更新meta-learner的参数
这和上一节面临的问题一样,meta-learner 学到的更新策略是针对这一类任务的,一旦新任务和元训练中的任务偏差较大时,这种更新策略可能就失效了。
5. FUTURE WORKS
未来的方向可能有:
- 从使用的先验数据:例如利用更多的先验知识、多模态的数据等
- 从使用的模型方法:用新的网络结构去替换以前的,例如用transformer替换RNN
- 从使用的场景:现在FSL在字符识别、图像识别、小样本分割等取得效果,在目标检测、目标跟踪、NLP中的各项任务上等值得尝试
- 理论分析
- ......
三、生成对抗网络 GAN 综述
说到小样本学习,就想说比较时髦的生成对抗网络GAN。别误会,生成对抗网络并不是只针对小样本生成,还有很多别的丰富应用。
1. GAN
GANs是一种结构化的概率模型,由两个对立的模型组成:生成模型(G)用于捕获数据分布,判别模型(D)用于估计生成数据的概率,以确定生成的数据是来自真实数据分布,还是来自G的分布。D和G使用基于梯度的优化技术(同时梯度下降)玩一个极小极大零和博弈,直到纳什均衡。
GANs在一些实际任务中表现良好,例如图像生成、视频生成、域自适应和图像超分辨率等。传统的GANs虽然在很多方面都取得了成功,但是由于D和G训练的不平衡,使得GANs在训练中非常不稳定。D利用迅速饱和的逻辑损失。另外,如果D可以很容易的区分出真假图像,那么D的梯度就会消失,当D不能提供梯度时,G就会停止更新。
近年来,对于模式崩溃问题的处理有了许多改进,因为G产生的样本基于少数模式,而不是整个数据空间。另一方面,引入了几个目标(损失)函数来最小化与传统GANs公式的差异。最后,提出了几种稳定训练的方法。
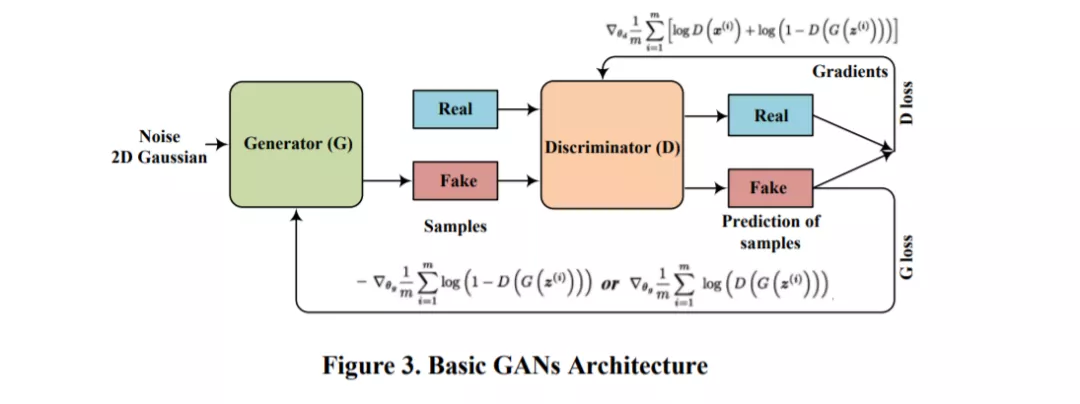
2. DCGAN
顾名思义,DCGAN主要讨论CNN与GAN如何结合使用并给出了一系列建议。另外还讨论了GAN特征的可视化、潜在空间插值等问题。
3. ImprovedGAN
Ian Goodfellow等人提供了诸多训练稳定GAN的建议,包括特征匹配、mini-batch识别、历史平均、单边标签平滑以及虚拟批标准化等技巧。讨论了GAN不稳定性的最佳假设。
4. PACGAN
PACGAN讨论的是的如何分析model collapse,以及提出了PAC判别器的方法用于解决model collapse。思想其实就是将判别器的输入改成多个样本,这样判别器可以同时看到多个样本可以从一定程度上防止model collapse。
5. WGAN
WGAN首先从理论上分析了原始GAN模型存在的训练不稳定、生成器和判别器的loss无法只是训练进程、生成样本缺乏多样性等问题,并通过改进算法流程针对性的给出了改进要点。
6. CycleGAN
CycleGAN讨论的是image2image的转换问题,提出了Cycle consistency loss来处理缺乏成对训练样本来做image2image的转换问题。Cycle Consistency Loss 背后的主要想法,图片A转化得到图片B,再从图片B转换得到图片A',那么图片A和图片A'应该是图一张图片。
7. Vid2Vid
Vid2Vid在生成器中加入光流约束,判别器中加入光流信息及对前景和背景分别建模,重点解决视频转换过程中前后帧图像的不一致性。
8. PGGAN
PGGAN创造性地提出了以一种渐进增大(Progressive growing)的方式训练GAN,利用逐渐增大的PGGAN网络实现了效果令人惊叹的生成图像。“Progressive Growing” 指的是先训练 4x4 的网络,然后训练 8x8,不断增大,最终达到 1024x1024。这既加快了训练速度,又大大稳定了训练速度,并且生成的图像质量非常高。
9. StackGAN
StackGAN是由文本生成图像,StackGAN模型与PGGAN工作的原理很像,StackGAN 首先输出分辨率为64×64 的图像,然后将其作为先验信息生成一个 256×256 分辨率的图像。
10. BigGAN
BigGAN模型是基于 ImageNet 生成图像质量最高的模型之一。该模型很难在本地机器上实现,而且 有许多组件,如 Self-Attention、 Spectral Normalization 和带有投影鉴别器的 cGAN等。
11. StyleGAN
StyleGAN应该是截至目前最复杂的GAN模型,该模型借鉴了一种称为自适应实例标准化 (AdaIN) 的机制来控制潜在空间向量 z。虽然很难自己实现一个StyleGAN,但是它提供了很多有趣的想法。
12. 小结
当然前文有一些方法没有提到的,例如CGAN、自编码GAN等。
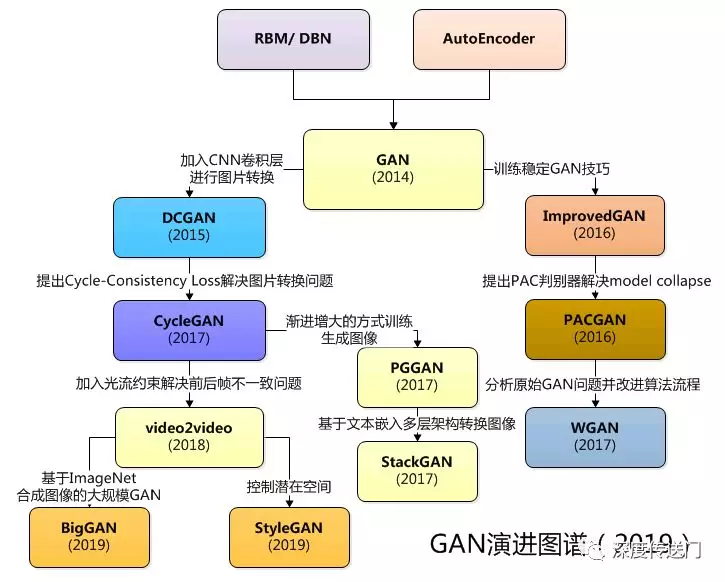
说到这里,放一张大佬整理的GAN家族主要模型的概要图:
- 左边部分主要是改进模型解决例如图片转换、文本转图像、生成图片、视频转换等实际问题。
- 右边部分主要是解决GAN框架本身存在的一些问题。
同时,再分享一下生成式对抗网络(GANs)最新2020综述,分类更全面更细致:[认真看图][认真看图]
- 主要包括基于重新设计的网络结构、新的目标函数和替代优化算法的技术三个大类

GAN 已经在一些特定应用上与其它机器学习算法相结合,例如半监督学习、迁移学习、强化学习和多模态学习等。GAN 在图像处理与计算机视觉(例如图像超分辨率、图像生成、目标检测和视频处理等)、自然语言处理(例如文本生成等)、音乐(例如歌词生成等)、语音与音频、医学以及数据科学中的典型应用(例如之前我的随笔里提到的数据补全、异常检测、时间序列预测等)。
同时,GAN 被用于特征学习领域(例如特征选择、哈希和度量学习等)和其它机器学习任务(例如主动学习、在线学习 、零/小样本学习和多任务学习等)。可以说,计算机领域的很多研究分支中的算法模型都能够互相迁移、彼此融合,从而在不同领域有了拓展性的应用。
四、迁移学习综述
说到小样本学习,我也想再说说迁移学习。但是别误会,迁移学习也并不是只针对小样本学习,还有很多别的丰富应用。
本文主要参考了一篇综述:A Survey on Transfer Learning
1. 基本概念
在许多机器学习和数据挖掘算法中,一个重要的假设就是目前的训练数据和将来的训练数据,一定要在相同的特征空间并且具有相同的分布。然而,在许多现实的应用案例中,这个假设可能不会成立。这种情况下,如果知识的迁移做得成功,我们将会通过避免花费大量昂贵的标记样本数据的代价,使得学习性能取得显著的提升。近年来,为了解决这类问题,迁移学习作为一个新的学习框架出现在人们面前。
迁移学习主要有以下三个研究问题:1)迁移什么,2)如何迁移,3)何时迁移。
- “迁移什么”提出了迁移哪部分知识的问题。 一些知识对单独的域或任务有用,一些知识对不同的领域是通用的,可以用来提高目标域或目标任务的性能。
- “何时迁移”提出了哪种情况下运用迁移学习。当源域和目标域无关时,强行迁移可能并不会提高目标域上算法的性能,甚至会损害性能。这种情况称为负迁移。
- 当前大部分关于迁移学习的工作关注于“迁移什么”和“如何迁移”,隐含着一个假设:源域和目标域彼此相关。然而,如何避免负迁移是一个很重要的问题。
基于迁移学习的定义,我们归纳了传统机器学习方法和迁移学习的异同见下表:

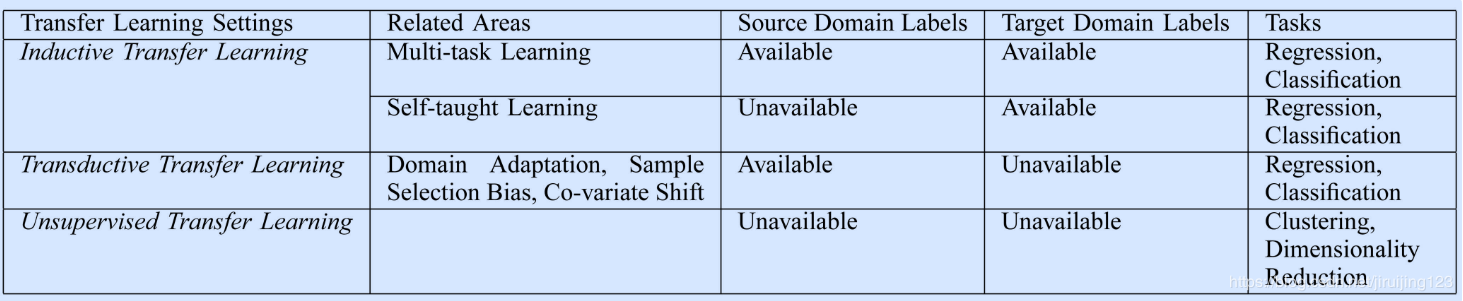
(1)inductive transfer learning:推导迁移学习,也叫归纳迁移学习。其目标任务和源任务不同,无论目标域与源域是否相同。这种情况下,要用目标域中的一些已标注数据生成一个客观预测模型以应用到目标域中。根据源域中已标注和未标注数据的不同情况,可以进一步将inductive transfer learning分为两种情况:
- 源域中大量已标注数据可用。这种情况下推导迁移学习和多任务学习类似。然而,推导迁移学习只关注于通过从源任务中迁移知识以便在目标任务中获得更高性能,然而多任务学习尝试同时学习源任务和目标任务。
- 源域中无已标注数据可用。这种情况下推导迁移学习和自我学习相似。自我学习中,源域和目标域间的标签空间可能不同,这意味着源域中的边缘信息不能直接使用。因此当源域中无已标注数据可用时这两种学习方法相似。
transductive transfer learning:转导迁移学习,也叫直推式迁移学习。其源任务和目标任务相同,源域和目标域不同。这种情况下,目标域中无已标注数据可用,源域中有大量已标注数据可用。根据源域和目标域中的不同状况,可以进一步将转导迁移学习分为两类:
- 源域和目标域中的特征空间不同
- 源域和目标域间的特征空间相同,但输入数据的边缘概率分布不同。这种情况与自适应学习相关,因为文本分类、样本选择偏差和协方差移位中的知识迁移都有相似的假设。
(3)unsupervised transfer learning:无监督迁移学习。与推导迁移学习相似,目标任务与源任务不同但相关。然而,无监督迁移学习专注于解决目标域中的无监督学习问题,例如聚类、降维、密度估计等。这种情况下,训练中源域和目标域都无已标注数据可用。
2. 迁移学习的分类
上述三种迁移学习可以基于“迁移什么”被分为四种情况:

(1)Instance-based TL(样本迁移):可以被称为基于实例的迁移学习。尽管source domain数据不可以整个直接被用到target domain里,但是在source domain中还是找到一些可以重新被用到target domain中的数据。对它们调整权重,使它能与target domain中的数据匹配之后可以进行迁移。
instance reweighting(样本重新调整权重)和importance sampling(重要性采样)是instance-based TL里主要用到的两项技术。
例如在这个例子中就是找到例子3,然后加重它的权值,这样在预测的时候它所占权重较大,预测也可以更准确。

(2)Feature-representation-transfer(特征迁移):可以被称为基于特征表示的迁移学习。找到一些好的有代表性的特征,通过特征变换把source domain和target domain的特征变换到同样的空间,使得这个空间中source domain和target domain的数据具有相同的分布,然后进行传统的机器学习就可以了。
特征变换这一块可以举个栗子:比如评论男生的时候,你会说“好帅!好有男人味!好有担当!”,评论女生的时候,你会说“好漂亮!好有女人味!好温柔!”可以看出共同的特征就是“好看”。把“好帅”映射到“好看”,把“好漂亮”映射到“好看”,“好看”便是它们的共同特征。
(3)Parameter-transfer(参数/模型迁移):可以被称为基于参数的迁移学习。假设source tasks和target tasks之间共享一些参数,或者共享模型hyperparameters(超参数)的先验分布。这样把原来的模型迁移到新的domain时,也可以达到不错的精度。
(4)Relational-knowledge-transfer(关系迁移):可以被称为基于关系知识的迁移学习。把相似的关系进行迁移,比如生物病毒传播到计算机病毒传播的迁移,比如师生关系到上司下属关系的迁移。最近,统计关系学习技术主导了这一领域。
3. 小结
综合第1小节和第2小节的内容,下图展示了不同迁移学习分类中不同方法的使用情况:

与生成对抗网络GAN一样,迁移学习同样可以在很多领域使用,同时,可以与很其他机器学习算法相结合,道理是相通的。
说到这里,前面各种方法中的统计学习实现实在是太恐怖了,我只想接下来重点介绍一下深度迁移学习的内容,即深度学习+迁移学习!
4. “小王爱迁移”系列学习内容:含深度迁移学习!
本小节主要分享一下大佬的知乎专栏的学习内容,主要包括迁移学习领域经典的各大方法,用于辅助对上文的理解:
(1)迁移成分分析(TCA):Domain adaptation via transfer component analysis,2009-2011
主要思想是:属于基于特征的迁移学习方法。PCA是一个大矩阵进去,一个小矩阵出来,TCA是两个大矩阵进去,两个小矩阵出来。从学术角度讲,TCA针对domain adaptation问题中,源域和目标域处于不同数据分布时,将两个领域的数据一起映射到一个高维的再生核希尔伯特空间。在此空间中,最小化源和目标的数据距离,同时最大程度地保留它们各自的内部属性。直观地理解就是,在现在这个维度上不好最小化它们的距离,那么就找个映射,在映射后的空间上让它们最接近,那么不就可以进行分类了吗?
主要步骤为:输入是两个特征矩阵,首先计算L和H矩阵,然后选择一些常用的核函数进行映射(比如线性核、高斯核)计算K,接着求
(2)测地线流式核方法(GFK):Geodesic flow kernel for unsupervised domain adaptation,2011-2012
SGF方法的主要思想:把source和target分别看成高维空间(Grassmann流形)中的两个点,在这两个点的测地线距离上取d个中间点,然后依次连接起来。这样,由source和target就构成了一条测地线的路径。只需要找到合适的每一步的变换,就能从source变换到target了。
SGF方法的主要贡献在于:提出了这种变换的计算及实现了相应的算法。但是它有很明显的缺点:到底需要找几个中间点?就是说这个参数d是没法估计的。
GFK方法解决了SGF的问题:
- 如何确定source和target路径上中间点的个数。它通过提出一种kernel方法,利用路径上的所有点的积分,把这个问题解决了。
- 当有多个source的时候,我们如何决定使用哪个source跟target进行迁移?GFK提出Rank of Domain度量,度量出跟target最近的source来解决这个问题。
GFK方法有以下几个步骤:选择最优的子空间维度进行变换、构建测地线、计算测地线流式核、以及构建分类器。
(3)联合分布适配(JDA):Transfer feature learning with joint distribution adaptation,2013
主要思想是:属于基于特征的迁移学习方法。是一个概率分布适配的方法,而且适配的是联合概率。JDA方法同时适配两个分布,然后非常精巧地规到了一个优化目标里。用弱分类器迭代,最后达到了很好的效果。
和TCA的主要区别有两点:
- 1)TCA是无监督的(边缘分布适配不需要label),JDA需要源域有label。
- 2)TCA不需要迭代,JDA需要迭代。
-------------------------------------------------------------------------------------------
(4)在线迁移学习:A framework of online transfer learning,2010-2014
这是在线迁移学习研究的第一篇文章,作者分别对同构OTL和异构OTL提出了相应的方法,就是基于SVM以及集成学习进行组合。
基本思想是:先针对可用的源域数据建立一个分类器,然后,每来一个目标域数据,就对这个新数据建立一个分类器,然后与在源域上建立的这个分类器进行组合。
核心问题是:确定源域和新数据分类器各自应该以怎么样的权重进行组合。
(5)负迁移:提出“传递迁移学习”的解决思路,2015-2017
如果两个领域之间基本不相似,那么就会大大损害迁移学习的效果。还是拿骑自行车来说,拿骑自行车的经验来学习开汽车,这显然是不太可能的。因为自行车和汽车之间基本不存在什么相似性。所以,这个任务基本上完不成。这时候,可以说出现了负迁移(negative transfer)。
产生负迁移的原因主要有:
- 源域和目标域压根不相似,谈何迁移?------数据问题
- 源域和目标域是相似的,但是,迁移学习方法不够好,没找到可迁移的成分。 ------方法问题
因此,在实际应用中,找到合理的相似性,并且选择或开发合理的迁移学习方法,能够避免负迁移现象。
随着研究的深入,已经有新的研究成果在逐渐克服负迁移的影响:
- 杨强教授团队2015在数据挖掘领悟顶级会议KDD上发表了传递迁移学习文章《Transitive transfer learning》,提出了传递迁移学习的思想。
- 杨强教授团队在2017年人工智能领域顶级会议AAAI上发表了远领域迁移学习文章《Distant domain transfer learning》,可以用人脸来识别飞机。
这些研究的意义在于,传统迁移学习只有两个领域足够相似才可以完成,而当两个领域不相似时,传递迁移学习却可以利用处于这两个领域之间的若干领域,将知识传递式的完成迁移。这个是很有意义的工作,可以视为解决负迁移的有效思想和方法。

(6)开放集迁移学习:Open Set Domain Adaptation,2017
现有的domain adaptation都针对的是一个“封闭”的任务,就是说,source和target中的类别是完全一样的,source有几类,target就有几类。这些方法都只是理想状态下的domain adaptation。而真正的环境中,source和target往往只会共享一些类的信息,而不是全部。
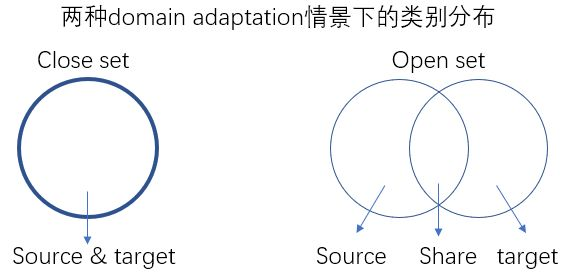
整个文章的解决思路大致是这样的:
- 利用source和target的关系,给target的样本打上标签
- 并将source转换到和target同一个空间中
两者依次迭代,直到收敛。作者根据target domain是否有label,把问题分成了unsupervised和semi-supervised domain adaptation,然后分开解决。
(7)张量迁移学习:When Unsupervised Domain Adaptation Meets Tensor Representations,2017
现有的那些domain adaptation方法都只是针对向量(vector)的。而这种表示所带来的问题就是,当把这些数据应用于高维度表示(如卷积)时,数据首先要经过向量化(vectorization)。此时,无法精准完备地保留一些统计属性。所以作者提出,不经过向量化来进行domain adaptation的方法,很自然地用到了tensor(张量)。
(8)从经验中学习迁移:Learning To Transfer,2018
提出了一个新颖的研究问题:类似于增量学习,如何最大限度地利用已有的迁移学习经验,使得其对新问题的泛化能力很好?同时也可以避免一出现新问题就从头进行学习。
在解决问题的方法上,虽然用的都是老方法,但是能够想到新已有方法很好地应用于这个问题。引来的拓展思考:在深度网络中如何持续学习?
(9)探秘任务迁移:Taskonomy: Disentangling Task Transfer Learning,2018
诸如物体识别、深度估计、边缘检测等一些常见的计算机视觉任务,彼此之间都或多或少地有一些联系。比如,我们很清楚地知道曲面的法线和深度是相关的:它们是彼此的梯度。但与此同时,另一些任务我们却不清楚,例如,一个房间中的关键点检测和阴影是如何协同工作完成姿态估计的?
已有的相关工作均忽略了这些任务的关联性,而是单独地对各个任务进行建模。不利用任务之间的相关性,无疑是十分耗时和复杂的。即使是要在不同的任务之间进行迁移,由于不同任务的不同任务空间之间的联系尚不清楚,也无法实现简单有效的任务迁移。
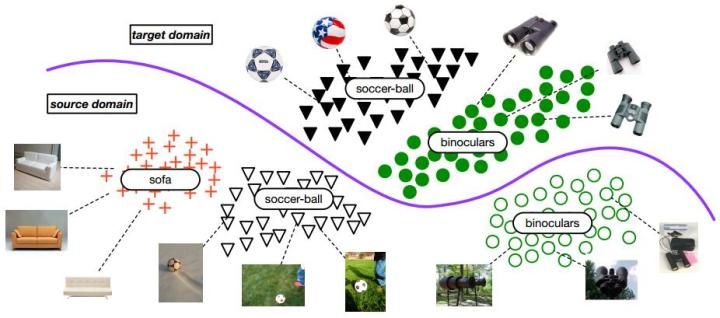
(10)选择性对抗迁移学习:Partial Transfer Learning with Selective Adversarial Networks,2018
传统的迁移学习问题情境都是,源域和目标域的类别空间一样。在大数据时代,通常我们会有大量的源域数据。这些源域数据比目标域数据,在类别上通常都是丰富的。比如基于ImageNet训练的图像分类器,必然是针对几千个类别进行的分类。我们实际用的时候,目标域往往只是其中的一部分类别。
因此,就要求相应的迁移学习方法能够对目标域,选择相似的源域样本(类别),同时也要避免负迁移。但是目标域通常是没有标签的,不知道和源域中哪个类别更相似。作者指出这个问题叫做partial transfer learning(部分迁移学习)。
(11)联邦迁移学习:2018
事实上,Google在2017年的一篇论文里进行了去中心化的推荐系统建模研究。其核心是,手机在本地进行模型训练,然后仅将模型更新的部分加密上传到云端,并与其他用户的进行整合。一些研究者也提出了CryptoDL深度学习框架、可扩展的加密深度方法、针对于逻辑回归方法的隐私保护等。但是,它们或只能针对于特定模型,或无法处理不同分布数据。
正是为了解决上述这些挑战,香港科技大学杨强教授和微众银行AI团队,最近提出了联邦迁移学习 (Federated Transfer Learning, FTL)。FTL将联邦学习的概念加以推广,强调在任何数据分布、任何实体上,均可以进行协同建模学习。
这项工作在国内,是杨教授与微众银行AI团队主导,目的是建立数据联邦,以解决大数据无法聚合的问题。在国外,目前是Google在进行相关的研究。二者的区别:微众银行AI团队的做法是,用户维度部分重叠,特征维度不重叠;而Google则是反过来:特征重叠,用户不重叠。
联邦迁移学习 vs 迁移学习 vs 多任务学习
- 多任务学习和FTL都注重多个任务的协同学习,最终目标都是要把所有的模型变得更强。但是,多任务学习强调不同任务之间可以共享训练数据,破坏了隐私规则。而FTL则可以在不共享隐私数据的情况下,进行协同的训练。
- 迁移学习注重知识从一个源领域到另一个目标领域的单向迁移。而这种单向的知识迁移,往往伴有一定的信息损失,因为通常只会关注迁移学习在目标领域上的效果,而忽略了在源领域上的效果。FTL则从目标上就很好地考虑了这一点,多个任务之间协同。
- 迁移学习和多任务学习都可以解决模型和数据漂移的问题,这一点在FTL中也得到了继承。
-------------------------------------------------------------------------------------------
(12)深度神经网络的可迁移性:How transferable are features in deep neural networks,2014
深度网络的一个事实:前面几层都学习到的是通用的特征(general feature),后面的网络更偏重于学习特定的特征(specific feature)。
虽然该论文并没有提出一个创新方法,但是通过实验得到了以下几个结论,对以后的深度学习和深度迁移学习都有着非常高的指导意义:
- 神经网络的前3层基本都是general feature,进行迁移的效果会比较好。
- 深度迁移网络中加入fine-tune,效果会提升比较大,可能会比原网络效果还好。
- Fine-tune可以比较好地克服数据之间的差异性。
- 深度迁移网络要比随机初始化权重效果好。
- 网络层数的迁移可以加速网络的学习和优化。
(13)深度迁移学习:例如DaNN、DDC、DAN等,2014-2015
DaNN(Domain Adaptive Neural Network)的结构异常简单,它仅由两层神经元组成:特征层和分类器层。作者的创新工作在于,在特征层后加入了一项MMD适配层,用来计算源域和目标域的距离,并将其加入网络的损失中进行训练。所以,整个网络的优化目标也相应地由两部分构成:在有label的源域数据上的分类误差,以及对两个领域数据的判别误差。
但是,由于网络太浅,表征能力有限,故无法很有效地解决domain adaptation问题(通俗点说就是精度不高)。因此,后续的研究者大多数都基于其思想进行扩充,例如将浅层网络改为更深层的AlexNet、ResNet、VGG等,例如将MMD换为多核的MMD等。
DDC(Deep Domain Confusion)针对预训练的AlexNet(8层)网络,在第7层(也就是feature层,softmax的上一层)加入了MMD距离来减小source和target之间的差异。这个方法简称为DDC。下图是DDC的算法插图。
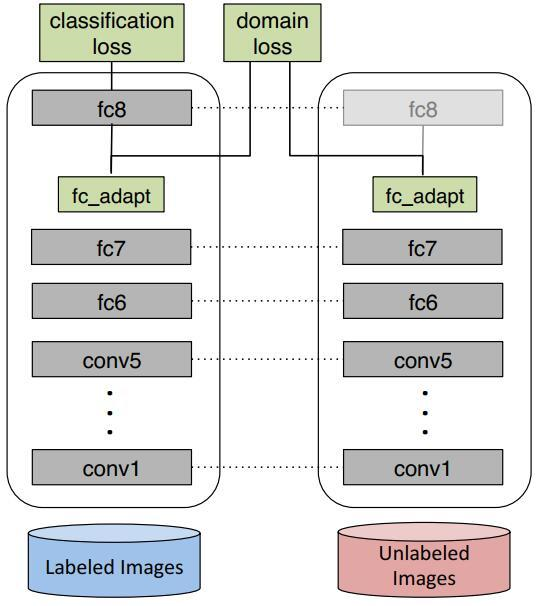
从上图可以很明显地看出,DDC的思想非常简单:在原有的AlexNet网络的基础上,对网络的fc7层(分类器前一层)后加一层适配层(adaptation layer)。适配层的作用是,单独考察网络对源域和目标域的判别能力。如果这个判别能力很差,那么我们就认为,网络学到的特征不足以将两个领域数据区分开,因而有助于学习到对领域不敏感的特征表示。
DAN(Deep Adaptation Network)是在DDC的基础上发展起来的,它很好地解决了DDC的两个问题:
- 一是DDC只适配了一层网络,可能还是不够,因为Jason的工作中已经明确指出不同层都是可以迁移的,所以DAN就多适配几层。
- 二是DDC是用了单一核的MMD,单一固定的核可能不是最优的核。DAN用了多核的MMD(MK-MMD),效果比DDC更好。
DAN的创新点是多层适配和多核MMD。下图是DAN的网络结构示意图。
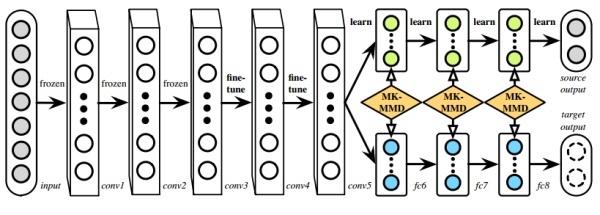
DDC和DAN作为深度迁移学习的代表性方法,充分利用了深度网络的可迁移特性,然后又把统计学习中的MK-MMD距离引入,取得了很好的效果。DAN的作者在2017年又进一步对其进行了延伸,做出了Joint Adaptation Network (JAN),进一步把feature和label的联合概率分布考虑了进来,可以视作之前JDA(joint distribution adaptation)的深度版。
(14)深度迁移学习文章解读:Simultaneous Deep Transfer Across Domains and Tasks,2015
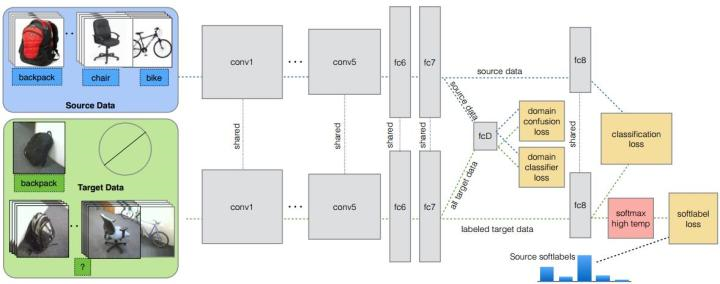
针对情况:target的部分class有少量label,剩下的class无label。文章最大的创新点是:现有的方法都是domain classifier加上一个domain confusion,就是适配。作者提出这些是不够的,所以提出了还要再加一个soft label loss。意思就是在source和target进行适配的时候,也要根据source的类别分布情况来进行调整target的。其实本意和JDA差不多。
网络结构如下图所示。网络由AlexNet修改而来,前面的几层都一样,区别只是在第fc7层后面加入了一个domain classifier,也就是进行domain adaptation的一层,在fc8后计算网络的loss和soft label的loss。就现在的研究成果看来,绝大多数也都是在深度网络后加一些相关的loss层,以之来提高网络的适配性。本质并没有很大的创新性。
(15)深度迁移度量学习:Deep Transfer Metric Learning,2015
已有的metric learning研究大多数集中在传统方法和深度方法中,它们已经取得了长足的进步。但是这些单纯的度量研究,往往只是在数据分布一致的情况下有效。如果数据分布发生了变化,已有的研究则不能很好地进行处理。因此,迁移学习就可以作为一种工具,综合学习不同数据分布下的度量,使得度量更稳定。
另一方面,已有的迁移学习工作大多都是基于固定的距离,例如MMD,因此无法学习到更好的距离表达。虽然近年来有一些迁移度量学习的工作,但它们都只考虑在数据层面将特征分布差异减小,而忽略了在源领域中的监督信息。因而,作者提出要在深度迁移网络中对度量进行学习,有效利用源领域中的监督信息,学习到更泛化的距离表达。
(16)用于部分迁移学习的深度加权对抗网络:Importance Weighted Adversarial Nets for Partial Domain Adaptation,2018
作者提出了一个深度加权对抗网络,如下图所示。网络的主要部分是:分别作用于源域和目标域的两个特征提取器(分别叫做 



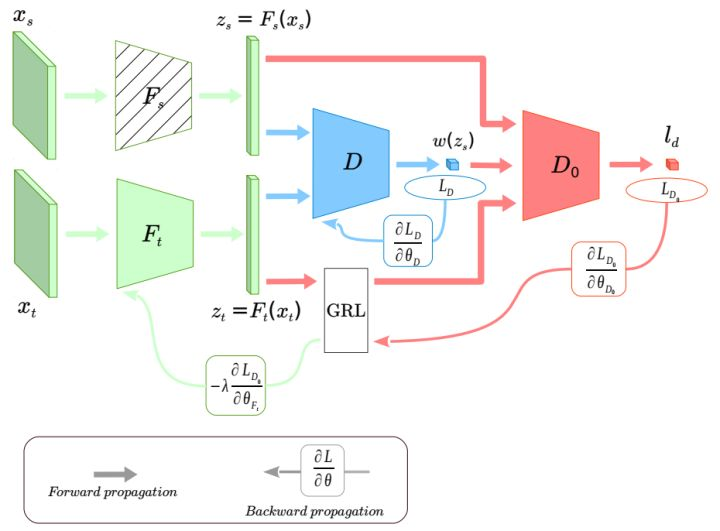
本文核心创新点是,从任务出发,直观地构造出两阶段式对抗网络,对源域中与目标域共享的类别样本进行有效筛选。另一个与已有工作不同的地方是,作者分别对源域和目标域采用了不同的特征提取器。
(17)基于条件对抗网络的领域自适应:Conditional Adversarial Domain Adaptation,2018
Domain adaptation问题一直以来是迁移学习和计算机视觉领域等的研究热点。从传统方法,到深度方法,再到最近的对抗方法,都在尝试解决此问题。作者在本文中提出,现在的对抗方法面临两个挑战:
- 一是当数据特征具有非常复杂的模态结构时,对抗方法无法捕获多模态的数据结构,容易造成负迁移。
- 二是当上面的问题存在时,domain classifier就很容易出错,所以造成迁移效果不好。
本文提出了基于条件对抗网络的领域自适应方法,主要由Condition + Adversarial + Adaptation这三部分构成。进行condition的时候,用到了一个叫做multilinear map的数学工具,主要是来刻画多个特征和类别之间的关系。
(18)深度迁移学习用于时间序列分类:Transfer learning for time series classification,2018
基本方法与在图像上进行深度迁移一致,先在一个源领域上进行pre-train,然后在目标领域上进行fine-tune。
网络的结构如下图所示。网络由3个卷积层、1个全局池化层、和1个全连接层构成。使用全连接层的好处是,在进行不同输入长度序列的fine-tune时,不需要再额外设计池内化层。
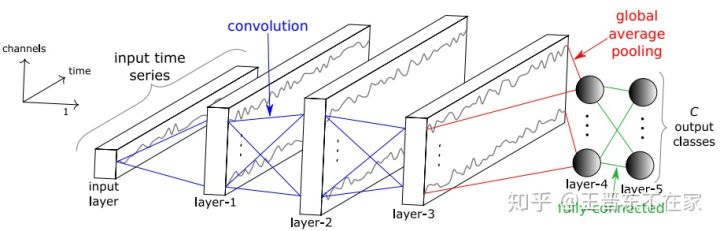
与图像的区别就是,输入由图片换成了时间序列。注意到,图片往往具有一定的通道数(如常见的R、G、B三通道)。时间序列也有通道,即不同维的时间序列数据。最简单的即是1维序列,可以认为是1个通道。多维时间序列则可以认为是多个通道。
(19)最大分类器差异的领域自适应:Maximum Classifier Discrepancy for Unsupervised Domain Adaptation,2018
方法的主要思想非常简单:用源域训练的网络如果用到目标域上,肯定因为目标域与源域的不同,效果也会有所不同。效果好的我们就不管了,重点关注效果不好的,因为这才能体现出领域的差异性。为了找到这些效果差的样本,作者引入了两个独立的分类器 

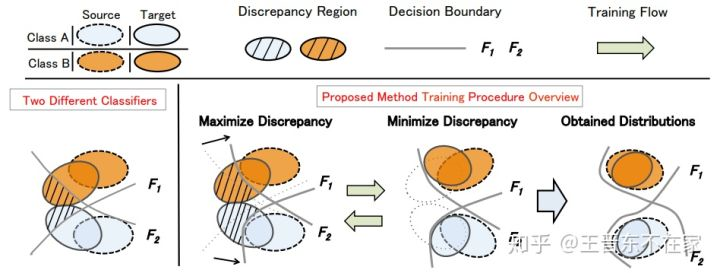
(20)异构网络的迁移:Learn What-Where to Transfer,2019
本文另辟蹊径,从根源上研究不同架构的深度网络如何进行迁移,并提供了行之有效的解决方案。
深度网络都是对迁移学习最为友好的学习架构。从最简单的finetune(微调),到固定网络的特征提取层不变在倒数第二层加入可学习的距离,再到通过领域对抗的思想学习隐式分布距离,深度迁移学习方法大行其道。在诸多图像分类、分割检测等任务上取得了不错的效果。
纵观这些方法的思路,大多均逃脱不开一个固有的模式:源域和目标域的网络架构完全相同,固定前若干层,微调高层或在高层中加入分布适配距离。然而,在迁移模型变得越来越臃肿、特定数据集精度不断攀升的同时,极少有人想过这样一个问题:
- 这种固定+微调的模式是否是唯一的迁移方法?
- 如果2个网络结构不同(比如),则上述模式直接失效,此时如何做迁移?
本文将这一思路具体表述为2点:What to transfer和Where to transfer
- What部分解决网络的可迁移性:源域中哪些层可以迁移到目标域哪些层?
- Where部分解决网络迁移多少:源域中哪些层的知识迁移多少给目标域的哪些层?
简单来说就是:学习源域网络中哪些层的知识可以迁移多少给目标域的哪些层。
五、深度迁移学习综述
说到迁移学习,我想最时髦的就是深度迁移学习了。有了深度学习的加持,迁移学习在人工智能领域有着丰富的应用。
上一节的内容其实已经包含了深度迁移学习的很多方法,包括非常多的idea,本节就作为辅助理解用吧!
本文参考了一篇综述:A Survey on Deep Transfer Learning
这里强推大佬的知乎专栏和guthub:https://github.com/jindongwang/transferlearning
1. 基本概念
深度迁移学习是通过深度神经网络研究如何利用其他领域的知识。随着深度神经网络在各个领域的广泛应用,大量的深度迁移学习方法被提出。包括离线/在线、增量学习、生成对抗、同构/异构等,可以说是非常丰富。
2. 深度迁移学习的分类
本文将深度迁移学习分为四类:基于实例的深度迁移学习、基于映射的深度迁移学习、基于网络的深度迁移学习和基于对抗的深度迁移学习。

(1)基于实例的深度迁移学习。与迁移学习分类中的第一类是一致的,这里不再赘述。
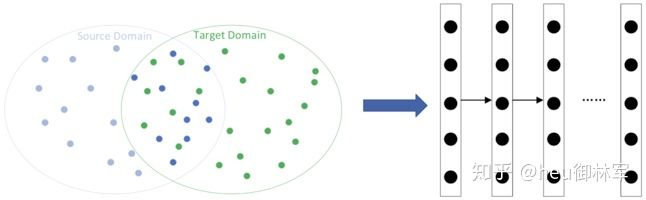
(2)基于映射的深度迁移学习。与迁移学习分类中的第二类是一致的,这里不再赘述。
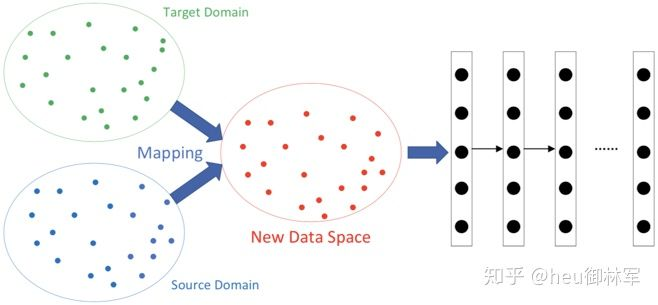
(3)基于网络的深度迁移学习。将原领域中预先训练好的部分网络,包括其网络结构和连接参数,重新利用,将其转化为用于目标领域的深度神经网络的一部分。
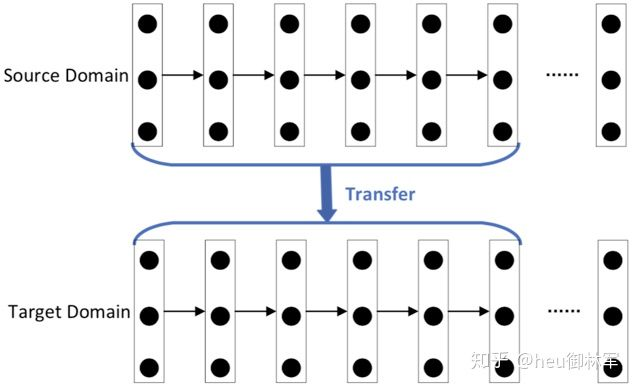
(4)基于对抗的深度迁移学习。在生成对抗网络 GAN 的启发下,引入对抗性技术,寻找既适用于源域又适用于目标域的可迁移表达。
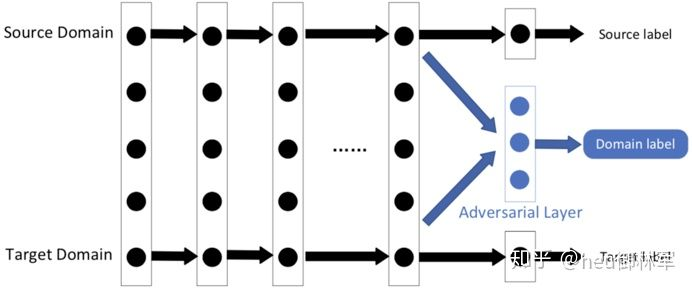
负迁移和可迁移性测度是传统迁移学习中的重要问题。如何利用深度神经网络在无监督或半监督学习中进行知识的迁移会受到越来越多的关注。
补充一点,元学习与迁移学习的区别联系是什么?
- 元学习关注的是一组任务T~p(T),元学习的目标是从T1,T2...中不断学习,从中学到更通用的知识,从而具有适应新任务Ti的能力,它关注的是任务T到Ti这个过程。
- 迁移学习通常只有一个源域A(当然可以有多个),一个目标域B,目标是学习A到B的迁移,更关注的是A到B的这个过程。
当然,两者有很多重叠之处,要结合着看,互相补充,互相学习。
六、其他概念介绍:知识蒸馏、增量学习
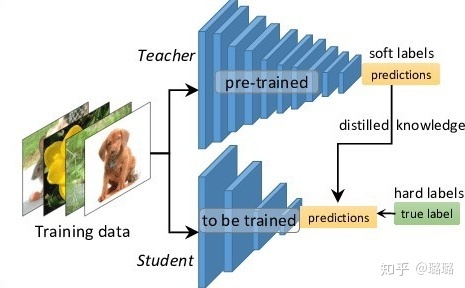
1. 知识蒸馏
知识蒸馏被广泛的用于模型压缩和迁移学习当中。
知识蒸馏可以将一个网络的知识转移到另一个网络,两个网络可以是同构或者异构。做法是先训练一个teacher网络,然后使用这个teacher网络的输出和数据的真实标签去训练student网络。
- 可以用来将网络从大网络转化成一个小网络,并保留接近于大网络的性能。
- 可以将多个网络的学到的知识转移到一个网络中,使得单个网络的性能接近emsemble的结果。
2. 增量学习
主要关注的是灾难性遗忘,平衡新知识与旧知识之间的关系。即如何在学习新知识的情况下不忘记旧知识。
引用Robipolikar对增量学习算法的定义,即一个增量学习算法应同时具有以下特点:
- 可以从新数据中学习新知识
- 以前已经处理过的数据不需要重复处理
- 每次只有一个训练观测样本被看到和学习
- 学习新知识的同时能保持以前学习到的大部分知识
- 一旦学习完成后训练观测样本被丢弃
- 学习系统没有关于整个训练样本的先验知识
在概念上,增量学习与迁移学习最大的区别就是对待旧知识的处理:
- 增量学习在学习新知识的同时需要尽可能保持旧知识,不管它们类别相关还是不相关的。
- 迁移学习只是借助旧知识来学习新知识,学习完成后只关注在新知识上的性能,不再考虑在旧知识上的性能。
如果您对异常检测感兴趣,欢迎浏览我的另一篇博客:异常检测算法演变及学习笔记
如果您对智能推荐感兴趣,欢迎浏览我的另一篇博客:智能推荐算法演变及学习笔记 、CTR预估模型演变及学习笔记
如果您对知识图谱感兴趣,欢迎浏览我的另一篇博客:行业知识图谱的构建及应用、基于图模型的智能推荐算法学习笔记
如果您对时间序列分析感兴趣,欢迎浏览我的另一篇博客:时间序列分析中预测类问题下的建模方案 、深度学习中的序列模型演变及学习笔记
如果您对数据挖掘感兴趣,欢迎浏览我的另一篇博客:数据挖掘比赛/项目全流程介绍 、机器学习中的聚类算法演变及学习笔记
如果您对人工智能算法感兴趣,欢迎浏览我的另一篇博客:人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)、人工智能领域常用的开源框架和库(含机器学习/深度学习/强化学习/知识图谱/图神经网络)
如果你是计算机专业的应届毕业生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的应届生,你如何准备求职面试?
如果你是计算机专业的本科生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的本科生,你可以选择学习什么?
如果你是计算机专业的研究生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的研究生,你可以选择学习什么?
如果你对金融科技感兴趣,欢迎浏览我的另一篇博客:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之后博主将持续分享各大算法的学习思路和学习笔记:hello world: 我的博客写作思路
加载全部内容