MySQL常见6个考题在实际工作中的运用
编程一生 人气:1题目一
MyISAM和InnoDB的区别,什么时候选择MyISAM
参考回答
InnoDB是目前MySQL主流版本(5.6、5.7、8.0)默认的存储引擎,支持事务、外键、行级锁,对于并发条件下要求数据的一致性,适用于对数据准确性要求高的场景。
MyISAM只支持表级锁、数据排列是按照插入顺序,没有做规则排序。适合应用以查询和插入为主,只有很少量的更新和删除操作,对事务的完整性和并发性要求不是很高的场景。
实际运用
看到很多人在选择存储引擎的时候会无脑的选择InnoDB,这个选择合理的一点是如果对数据准确性要求没有那么高,直接用NoSQL就好了。用MySQL就是为了可靠啊。
但是实际工作中,我设计的数据库中通常都会有几张MyISAM的数据表,通常用来存储历史记录,与使用InnoDB存储实时记录信息的配合使用。
举个例子:比如一条物流信息,在实时的表里存着目前物流的状态:比如配送中。这条物流在历史上经过了:正在通知快递公司取件、XXX已收揽等,这张记录表基本只有插入和查询,并且丢失一个中间状态不影响当前结果,这就很合适用MyISAM。
题目二
简述MySQL的MVCC多版本并发控制
参考回答

MVCC是对于事务隔离级别的读已提交RC和可重复读RR,基于乐观锁的实现。在LBCC(基于锁的并发控制)RC、RR和串行化分别是通过加行锁、间隙锁和表锁来基于悲观锁实现。而乐观锁的原理就是在特定的时间点(RC是每次读时,RR是事务开始时)生成一个当前快照,读数据读取快照,只在提交时判断是否有冲突,类似于git的branch和commit。
MVCC会在新开启一个事务时,给事务里包含的每行记录添加一个当前事务ID和回滚指针。并包含一个Read View,Read View里保存了当前活跃的事务列表,小于这些列表的最近的事务ID才是可见的。这样保证了读到的都是已提交的事务。
实际运用
MVCC不仅可以用于数据库,也是很常见的一种并发控制手段。比如使用有限状态自动机来控制的订单状态,在更新订单状态的时候先查询当前状态,比如当前状态是订单未提交,则更新时update XXX set status='订单已提交' where status='订单未提交',如果执行这条语句时,status已经发生了改变,这条语句就执行失败了。这样不通过数据库自身事务的MVCC,在业务逻辑里也实现了MVCC思想的乐观锁设计。
题目三
分布式锁的实现方式
参考回答
主流有三种
1>基于数据库
1.1>基于数据库主键:插入一条数据,指定主键。如果有两条插入会主键冲突,并发执行失败
1.2>基于数据库排他锁:提交一个update事务,如果这个事务不提交,其他也对锁定范围内执行update就会阻塞,解决并发问题
2>基于缓存比如redis的setNX
3>基于zookeeper
实际运用
相信很多人选择分布式锁都是选择第二种,第三种虽然并发性差一下,如果本来就引入了zk,而没有缓存,而分布式锁应用量又不那么大,为了减少引入新组件带来的风险和维护成本,也有可能选择zk。很多人大概认为自己没有用过基于数据库的分布式锁,实际上在不使用MVCC的时代并不是这样。
在使用spring进行业务开发的时候,常见的一种场景就是使用spring配置事务。默认级别是Repeatable Read可重复读。在这里面如果使用的是LBCC,一进入事务就加入一个排他锁,比如insert、update、delete或者select XXX for update。然后做其他的,比如进行一个RPC调用。这时候一旦出现并发,只有一个能顺利执行,其他都会被阻塞。实际上就相当于使用了分布式锁。
题目四
为什么采用B+树作为索引结构?
参考回答
如果采用Hash表,范围查找需要全表扫描;如果采用二叉查找树,由于无法保证平衡,可能退化为链表;如果采用平衡二叉树,通过旋转解决了平衡的问题,但是旋转操作效率太低;如果采用红黑树,树太高,IO次数多;如果采用普通B树,节点要存数索引和数据,一个内存页可存储的数据还是少,另外范围查找也需要多次IO;
而B+Tree有三个特性:
1>非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
2>叶子节点包含所有索引字段
3>叶子节点用指针链接,提高范围查询的性能
实际运用
在分布式场景下,我们的业务ID都是全局唯一的字符串。如果单纯从业务上来考虑,用业务ID作为数据库的主键就足够了。可以DBA往往要求使用整型的自增主键作为数据库主键,而这个主键对业务来说就是个浪费,没有任何业务含义。
如果了解了索引的底层结构就不难理解
1>整型比字符串占用更少的空间
2>同时大小比较也很快
3>之所以要自增是每次插入新的记录,对于叶子节点来说:记录会顺序的添加到当前索引节点的后续位置,当一页写满,会自动开辟一个新的页。而如果使用非自增主键,就需要插入的时候移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要读回来。分页操作造成大量的碎片,必须通过优化操作重建表并优化填充页面。
题目五
什么叫做覆盖索引?
参考回答
只需要在一棵辅助索引树上就可以获取SQL所需要的所有列数据,不需要回表。
实际运用
一些持久层框架比如mybatis的generator插件可以自动生成sql配置文件,这些配置文件往往效率很低。但是刚毕业的同学很多都不会去改这个文件,比如只需要个别列的时候会用java的lambda表达式等方式从逻辑上做处理。结果造成一些性能的问题。
我在根据一些条件进行范围查找的时候,如果只需要返回ID或者个别列,会自己去改mybatis的generator自动生成的文件,原因是尽量使用覆盖索引,较回表速度快。
想验证是否使用了覆盖索引,可以用explain执行计划,查看extra字段,如果只显示Using index说明正确使用了覆盖索引。如果extra为空或者除了using index还有filesort说明触发了回表。
题目六
查询在什么时候不走索引
参考回答
主要三种情况
1>不满足走索引的条件,常见的情况有
1.1>不满足最左匹配原则
1.2>查询条件使用了函数
1.3>or操作有一个字段没有索引
1.4>使用like条件以%开头
2>走索引效率低于全表扫描,常见的情况有
2.1>查询条件对null做判断,而null的值很多
2.2>一个字段区分度很小,比如性别、状态
3>需要回表的查询结果集过大,超过了配置的范围
实际运用
使用索引是为了对查询做优化,要衡量优化效果需要数据说话。所以需要一些工具来衡量,常用的有:
1>慢查询日志
开启慢查询日志,可以针对慢SQL进行分析看看哪些可以用索引进行优化
2>show processlist
show processlist 语句可以查看当前正在执行的SQL,如果一些SQL执行慢,block了其他的SQL,这是个很好的工具


3>show profile分析SQL
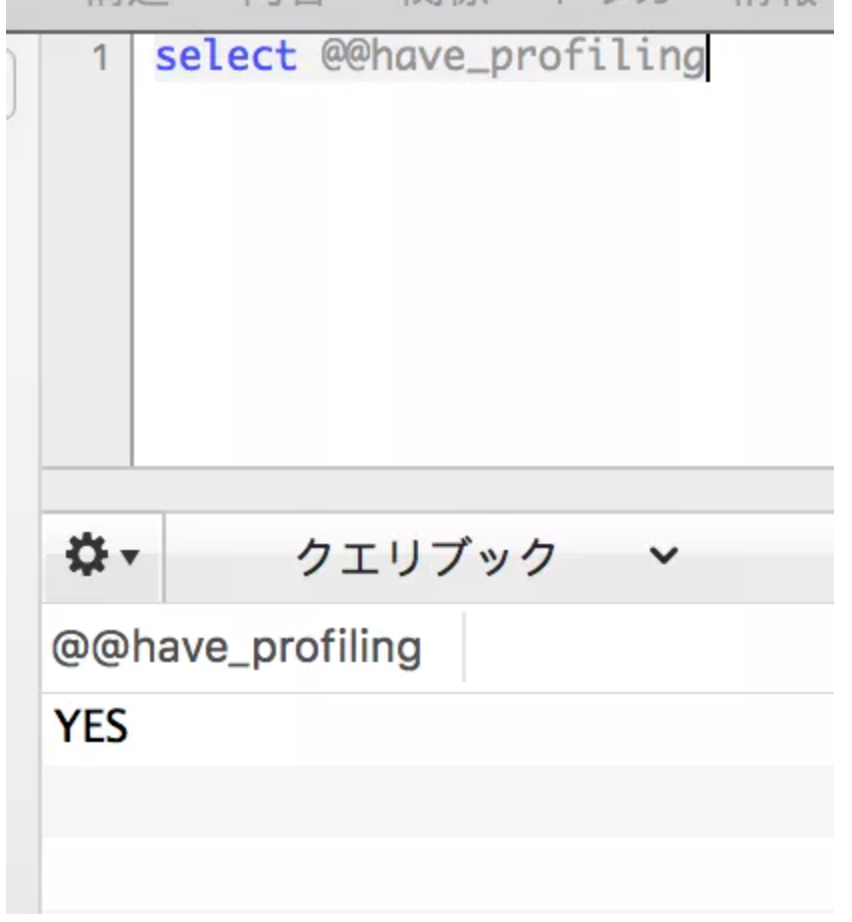
使用这个工具可以分析出时间究竟耗费在哪个阶段。先查询是否支持

支持的话,可以用select @@profiling 查看是否开启,如果结果为0说明未开启。需要先set @@profiling=1;
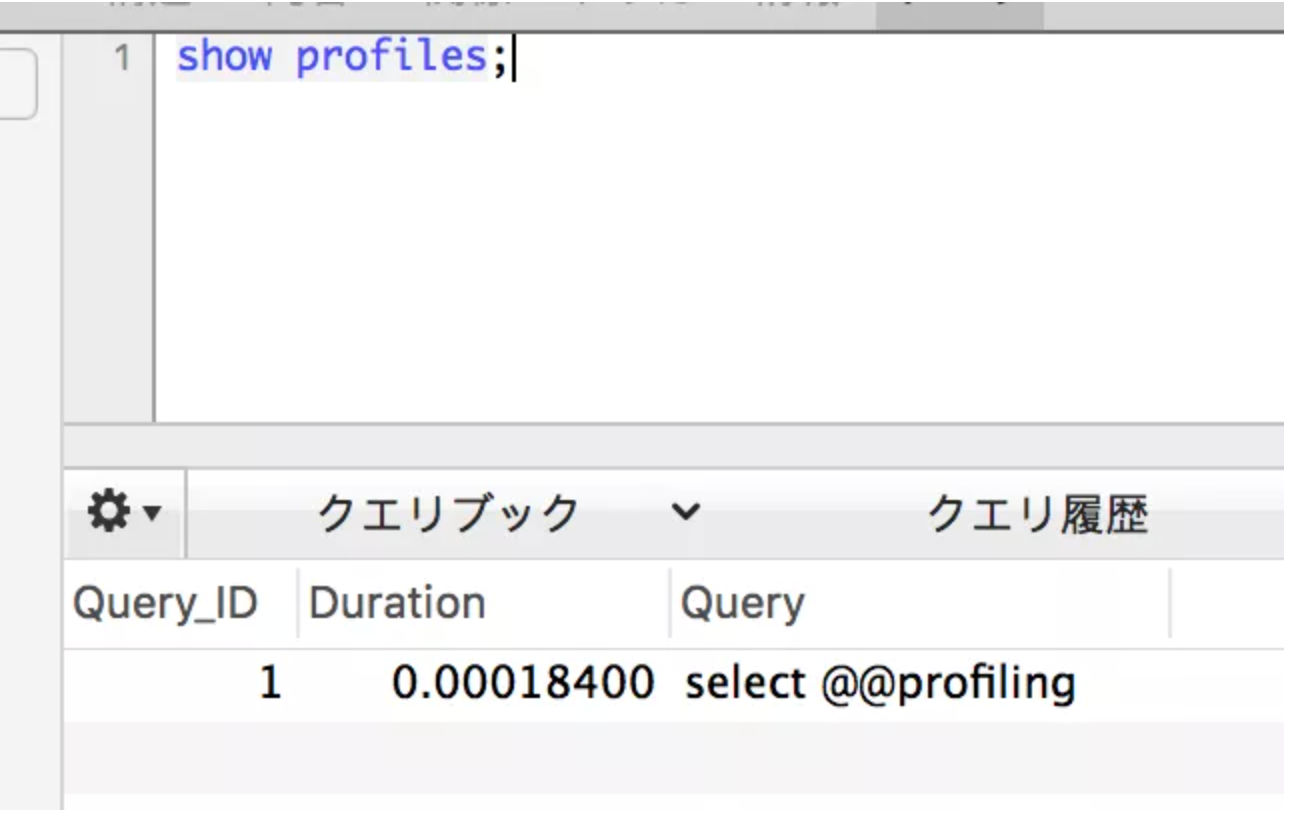
这时候就可以用show profiles查看每一条SQL语句耗费的时间
show profile for query XXID 可以查看具体耗费在哪个阶段
4>Trace分析优化器的执行计划
使用set optimizer_trace='enabled=on',end_markers_in_json=on;可以打开trace分析,想查看具体的优化器执行计划,只要执行
select * from `information_schema`.optimizer_trace即可
点击开每一步都有很详细的分析
总结
知识只要学透了都可以灵活运用。在运用的时候要注意衡量效果。一个常见的误区是开发人员无脑的在MySQL上层加缓存,用来提高效率。但是缓存只适用于读多写少的情况,比如在金融交易系统,数据读写比例1:1。数据总是查询出来下一刻就被更新了,这时候用缓存反而加重系统的负担和复杂性。
这时候,我们可以先利用工具查询数据库的读写比例。比如show global status like 'Com_______' 这个SQL可以查看select、update、insert、delete都被执行了多少次。

或者show global status like 'Innodb_row_%' 除了查看Innodb的读写情况,还可以查看锁的情况。

思考
请网上搜索一下「58Mysql军规」然后思考每条军规背后的理论支撑。
加载全部内容