C语言使用setjmp和longjmp实现一个简单的协程
amjieker 人气:0正文
协程是什么呢,有人说是轻量级线程,有人说的用户级线程,其和线程的区别可能就是更轻量、操作系统无感的。 其实从根本来说的话,协程本质上就是在一个进程上的程序而已,外部感知不到它的存在。
协程其实我感觉对理解函数压栈入栈、进程的上下文切换也是非常有帮助的。
以下内容均在 Linux的 x86_64 环境下实现。 这里不讨论其他的实现。
(C/C++)函数的工作原理
对于汇编上的函数来说,就是一个过程。
汇编执行的逻辑就是一条指令一条指令的去执行,去处理。
这里分为两个地方,第一个是代码区,我们的pc指针指向当前指向的指令。
在x86_64下,寄存器$rip存放着 pc 指针。
第二个是栈区(别杠,这里不讨论堆区、静态区、常量区等等等),栈是一种先进后出的结构。一般用来存放数据。
在x86_64下,栈顶指针放在$rsp的位置。
$rbp用来存放栈帧的起始。
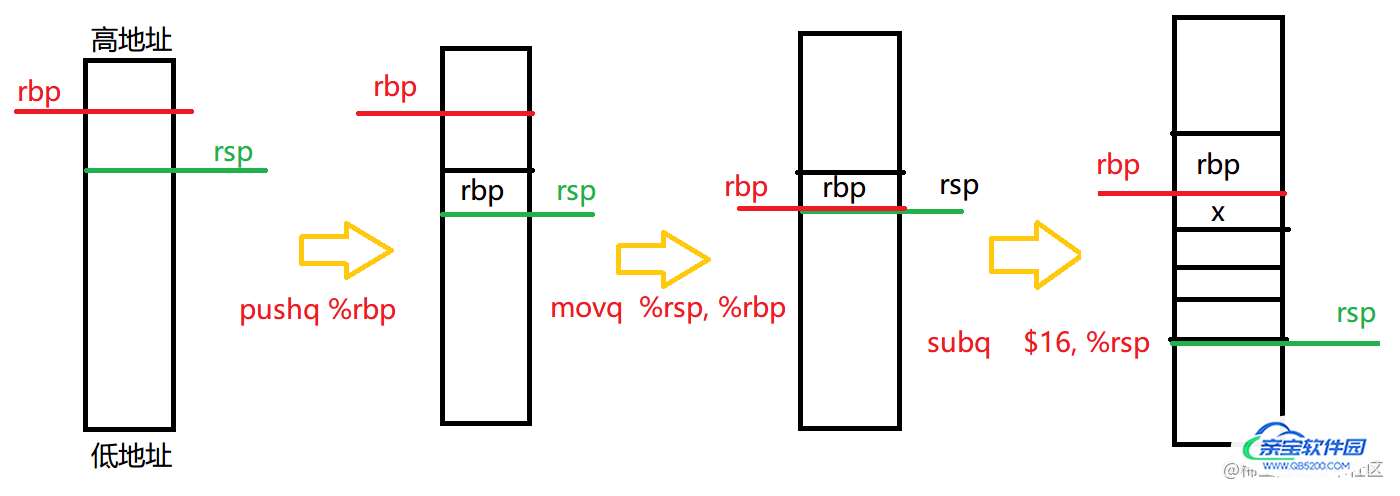
看一个最简单的汇编代码:
int fun() {
return 0;
}
fun:
pushq %rbp
movq %rsp, %rbp
movl $0, %eax
popq %rbp
ret
pushq 指令是将 $rbp的值压入栈中,然后$rsp指针移动。
movq 指令就是将 A 移动到 B 位置去。
popq 指令就是把东西从栈中弹出到A,栈指针移动。
函数入栈示意图
具体函数传参和栈帧请看这一篇文章 https:
(C/C++)内嵌汇编
C/C++支持我们内嵌汇编在代码中。 形如:
asm volatile("", :::)
(volatile是为了防止被优化掉)
格式为:
asm volatile("InSTructiON List" : Output : Input : Clobber/Modify);
你可以利用汇编来完成赋值操作
int a=114514, b;
asm volatile("movl %1, %%eax;
movl %%eax, %0;"
:"=r"(b) /* output */
:"r"(a) /* input */
:"%eax" /* clobbered register */
);
(linux下)setjmp和longjmp
如何用可以看这一篇文章 https:
setjmp和longjmp在本文中主要起到什么作用呢?
切换上下文
啊,好高大上啊,听不懂。
说人话,就是保存一下当前的寄存器(因为是协程,只有寄存器够了)
setjmp原理就是保存好当前时刻的寄存器。
然后在longjmp调用的时候,将恢复 jmp_buf所存放的寄存器的值,以达到跨函数跳转的目的。
这两个东西就非常适合用来做我们这个的上下文切换。
当然,你也可以用 ucontext来做这一件事情,只不过,我们这个是个简单的例子罢了。
协程的实现
首先,抛开调度器不谈,我们只用关心什么?
独立的运行空间、上下文...?
对于每一个协程来说,我们自然是不希望开辟在栈上的,(当前栈帧被摧毁\从新利用怎么办?)
我们可以动态的分配在堆上,将这一块内存当为这个协程的栈。
当然,协程是一个函数,并且可以调用另外的函数,(调用另外的函数的时候分配的内存就是这个协程所在的这一块内存)
现在我们要做三件事情。
- 将
%rsp切换到新分配的堆,而不是用原来有的栈。 - 函数的传参保存在哪儿。
- 还是就是,协程执行完了,主程序肯定不能直接退出,当前协程是应该返回主程序的地址?显然不可行,需要hook返回地址,让我们的协程回不去来的位置。
有点像什么呢?
正常的调用是这样:
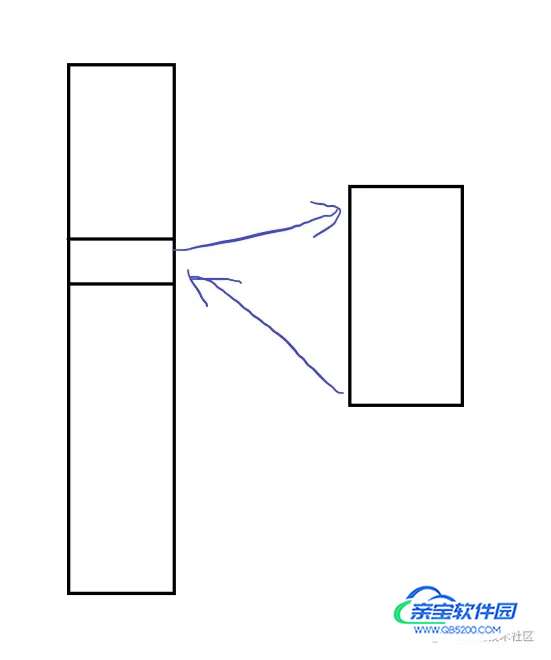
我们将push一个新的函数地址进去。
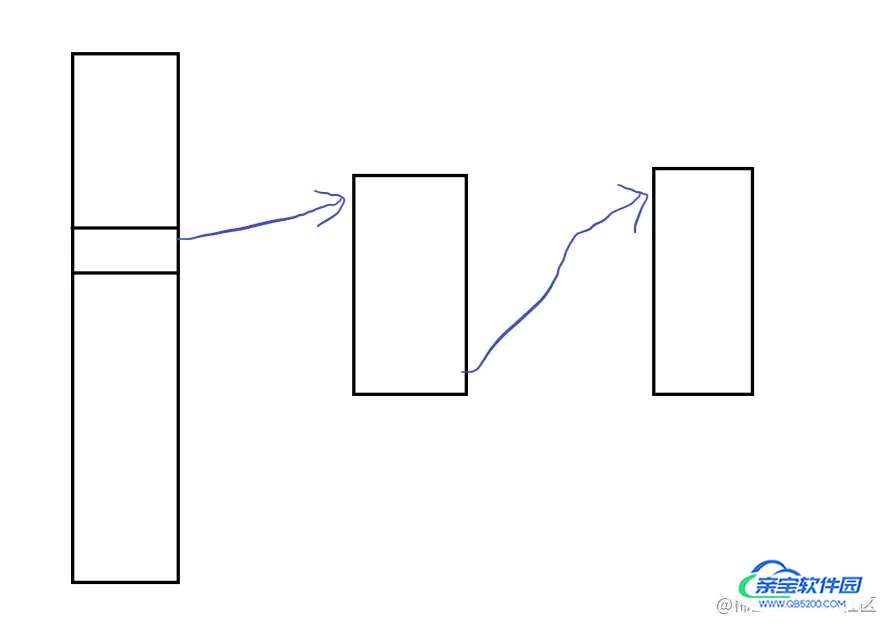
下面是汇编实现:
asm volatile(
"movq %0, %%rsp;" // 更改 %rsp 为 当前分配的堆地址 now
"movq %2, %%rdi;" // 传参
"pushq %3;" // 拆分call指令,将 自定义的新函数压入返回地址
"jmp *%1;" // 跳转到协程执行
:
: "b"(now), "d"(func), "a"(arg), "c"(exit_)
: "memory");
结构体定义
#define alignment16(a) ((a) & (~(16 - 1))) // 向前对齐
#define STACK_SIZE 4096
enum co_status {
CO_NEW = 1,
CO_DEAD,
};
struct co {
void (*func)(void *);
void *arg;
enum co_status status;
jmp_buf context;
uint8_t stack[STACK_SIZE];
};
上下文管理
std::vector<co *> context; std::unordered_map<co *, int> has_context; co main_co; co *now_co;
辅助函数
void refresh_context(co *buf) {
if (!has_context.count(buf)) {
context.push_back(buf);
has_context[buf] = context.size() - 1;
}
}
void exit_() {
now_co->status = CO_DEAD;
while (1) {
yield();
}
}
新建协程
注意到rsp的对齐,不对齐rsp会段错误
注意堆和栈的增长是反的
co *coroutine(void (*func)(void *), void *arg) {
co *cur = new co;
cur->arg = arg;
cur->func = func;
cur->status = CO_NEW;
void *now = (void *)(alignment16(((uintptr_t)cur->stack + STACK_SIZE)));
int res = setjmp(main_co.context); // 保存当前上下文
refresh_context(&(main_co)); // 刷新上下文
if (res == 0) {
now_co = cur; // 协程创建成功,立马开始执行,直到第一次 yield
asm volatile(
"movq %0, %%rsp;"
"movq %2, %%rdi;"
"pushq %3;"
"jmp *%1;"
:
: "b"(now), "d"(func), "a"(arg), "c"(exit_)
: "memory");
}
return cur;
}
协程让步
这里用的 0 和 1来区分是否为切换上下中的让步和苏醒操作。
void yield() {
assert(now_co != NULL);
int res = setjmp(now_co->context); // 保存上下文
refresh_context(now_co);
if (res == 0) {
now_co = context[(rand()) % context.size()]; // 挑选幸运观众
longjmp(now_co->context, 1); // 跳转到其他上下文继续执行
}
}
协程回收
这里,当协程没有执行完,状态不为 CO_DEAD 时,当前调用wait的程序就得一直让出
直到等到 CO_DEAD时 ,将其回收掉。
void wait(co *co_) {
while (co_->status != CO_DEAD) yield();
for (auto v = context.begin(); v != context.end();
v++) // 比较慢,可改用红黑树引用删除节点
if (*v == co_) {
context.erase(v);
break;
}
has_context.erase(co_);
delete co_;
}
总体代码和测试代码
#include <assert.h>
#include <setjmp.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <queue>
#include <unordered_map>
#define alignment16(a) ((a) & (~(16 - 1))) // 向前对齐
#define STACK_SIZE 4096
enum co_status {
CO_NEW = 1,
CO_DEAD,
};
struct co {
void (*func)(void *);
void *arg;
enum co_status status;
jmp_buf context;
uint8_t stack[STACK_SIZE];
};
std::vector<co *> context;
std::unordered_map<co *, int> has_context;
co main_co;
co *now_co;
char __init_time__ = [] {
srand(time(NULL));
return 0;
}();
void refresh_context(co *buf) {
if (!has_context.count(buf)) {
context.push_back(buf);
has_context[buf] = context.size() - 1;
}
}
void exit_();
co *coroutine(void (*func)(void *), void *arg) {
co *cur = new co;
cur->arg = arg;
cur->func = func;
cur->status = CO_NEW;
void *now = (void *)(alignment16(((uintptr_t)cur->stack + STACK_SIZE)));
int res = setjmp(main_co.context);
refresh_context(&(main_co));
if (res == 0) {
now_co = cur;
asm volatile(
"movq %0, %%rsp;"
"movq %2, %%rdi;"
"pushq %3;"
"jmp *%1;"
:
: "b"(now), "d"(func), "a"(arg), "c"(exit_)
: "memory");
}
return cur;
}
void yield() {
assert(now_co != NULL);
int res = setjmp(now_co->context);
refresh_context(now_co);
if (res == 0) {
now_co = context[(rand()) % context.size()];
longjmp(now_co->context, 1);
}
}
void wait(co *co_) {
while (co_->status != CO_DEAD) yield();
for (auto v = context.begin(); v != context.end();
v++) // 比较慢,可改用红黑树引用删除节点
if (*v == co_) {
context.erase(v);
break;
}
has_context.erase(co_);
delete co_;
}
void exit_() {
now_co->status = CO_DEAD;
while (1) {
yield();
}
}
int count = 1;
void entry(void *arg) {
for (int i = 0; i < 5; i++) {
printf("task: [%s] seq:[%d] \n", (const char *)arg, count++);
yield();
}
}
int main() {
co *co1 = coroutine(entry, (void *)"a");
co *co2 = coroutine(entry, (void *)"b");
co *co3 = coroutine(entry, (void *)"c");
wait(co1);
wait(co2);
wait(co3);
printf("%d over\n", count);
return 0;
}
效果
task: [a] seq:[1]
task: [b] seq:[2]
task: [a] seq:[3]
task: [a] seq:[4]
task: [a] seq:[5]
task: [b] seq:[6]
task: [a] seq:[7]
task: [c] seq:[8]
task: [c] seq:[9]
task: [b] seq:[10]
task: [b] seq:[11]
task: [c] seq:[12]
task: [b] seq:[13]
task: [c] seq:[14]
task: [c] seq:[15]
16 over
调度顺序是随机的。
总结
本文主要简单介绍了一个一种可能的协程的实现方法,但是极其简陋和不规范,如有纰漏,请指正。
通过对协程的学习和理解,可以大概明白线程的工作原理,进程的工作原理,为什么线程要比进程耗费资源。
可以了解到C/C++函数调用的基础流程,以及如何搞一个函数让其不返回等操作。
本文没有涉及调度,涉及得很简陋,协程的状态只有 新建和死亡。中间的其他状态没有标注。
加载全部内容