基于NodeJS的前后端分离的思考与实践(六)Nginx + Node.js + Java 的软件栈部署实践
人气:0淘宝网线上应用的传统软件栈结构为 Nginx + Velocity + Java,即:
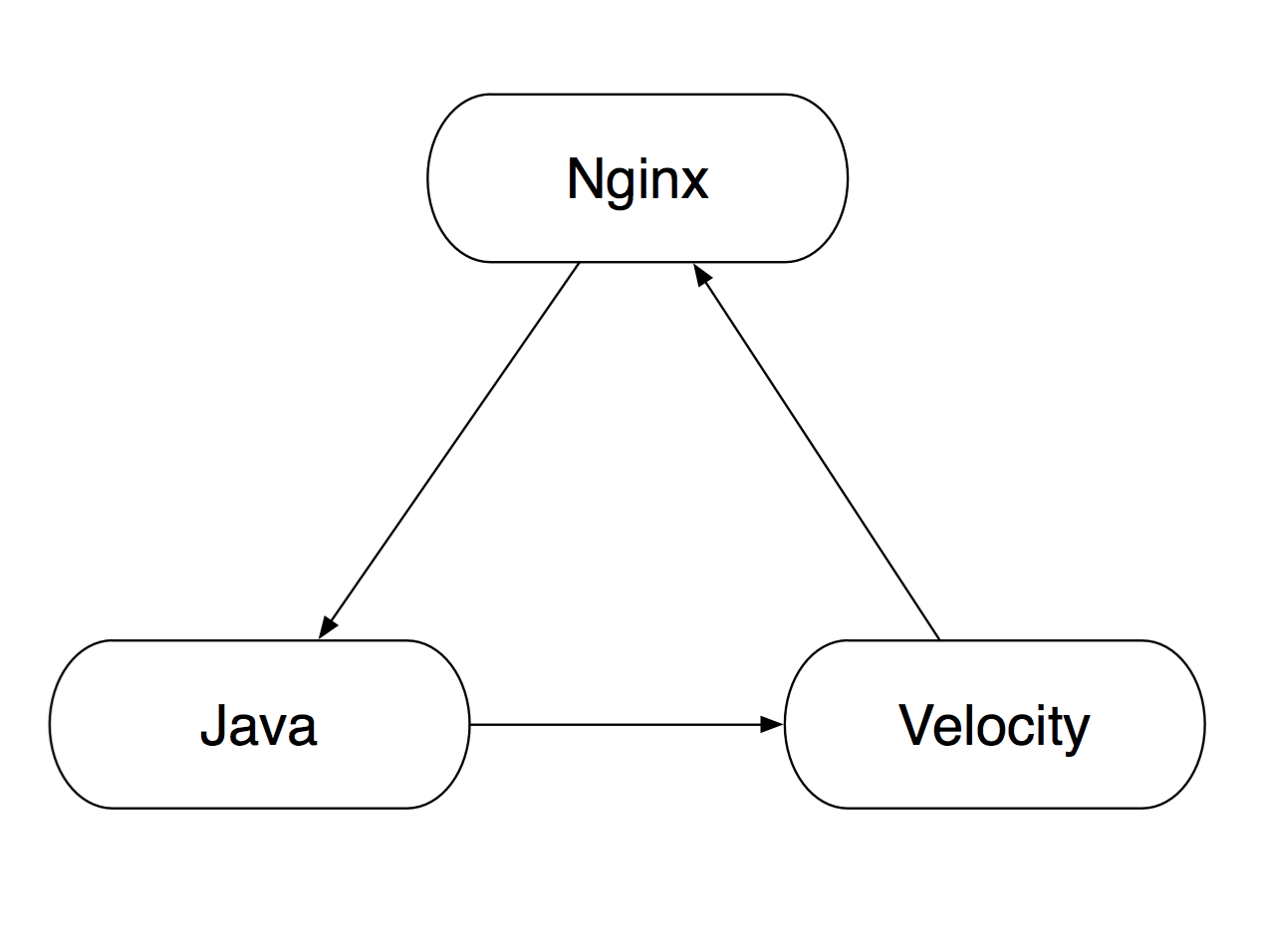
在这个体系中,Nginx 将请求转发给 Java 应用,后者处理完事务,再将数据用 Velocity 模板渲染成最终的页面。
引入 Node.js 之后,我们势必要面临以下几个问题:
技术栈的拓扑结构该如何设计,部署方式该如何选择,才算是科学合理?项目完成后,该如何切分流量,对运维来说才算是方便快捷?遇到线上的问题,如何最快地解除险情,避免更大的损失?如何确保应用的健康情况,在负载均衡调度的层面加以管理?承系统拓扑
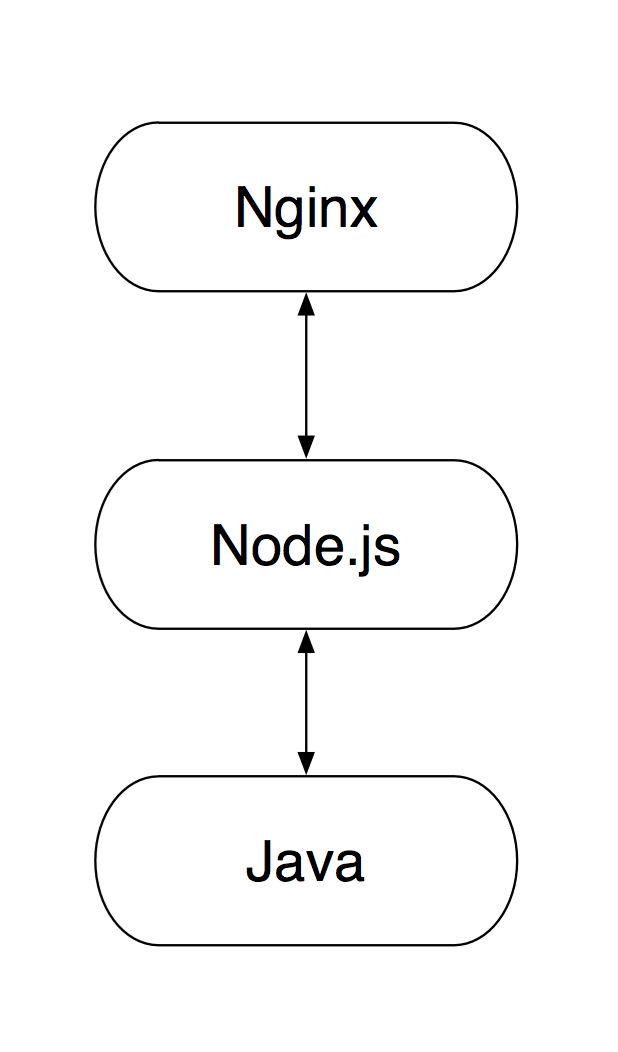
按照我们在前后端分离的思考与实践(二)- 基于前后端分离的模版探索一文中的思路,Velocity 需要被 Node.js 取代,从而让这个结构变成:
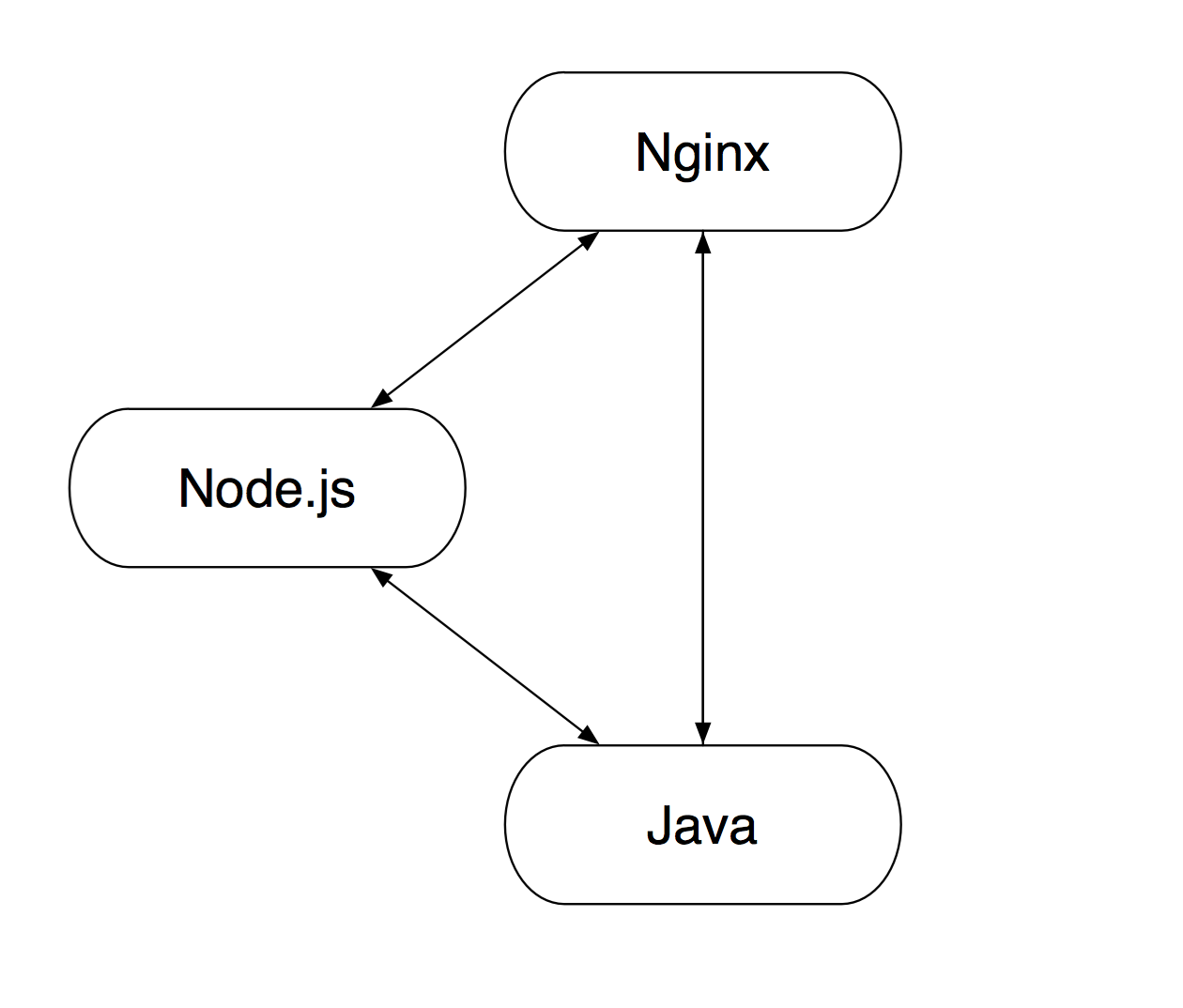
这当然是最理想的目标。然而,在传统栈中首次引入 Node.js 这一层毕竟是个新尝试。为了稳妥起见,我们决定只在收藏夹的宝贝收藏页面(shoucang.taobao.com/item_collect.htm)启用新的技术,其它页面沿用传统方案。即,由 Nginx 判断请求的页面类型,决定这个请求究竟是要转发给 Node.js 还是 Java。于是,最后的结构成了:
部署方案
上面的结构看起来没什么问题了,但其实新问题还等在前面。在传统结构中,Nginx 与 Java 是部署在同一台服务器上的,Nginx 监听 80 端口,与监听高位 7001 端口的 Java 通信。现在引入了 Node.js ,需要新跑一个监听端口的进程,到底是将 Node.js 与 Nginx + Java 部署在同一台机器,还是将 Node.js 部署在单独的集群呢?
我们来比较一下两种方式各自特点:
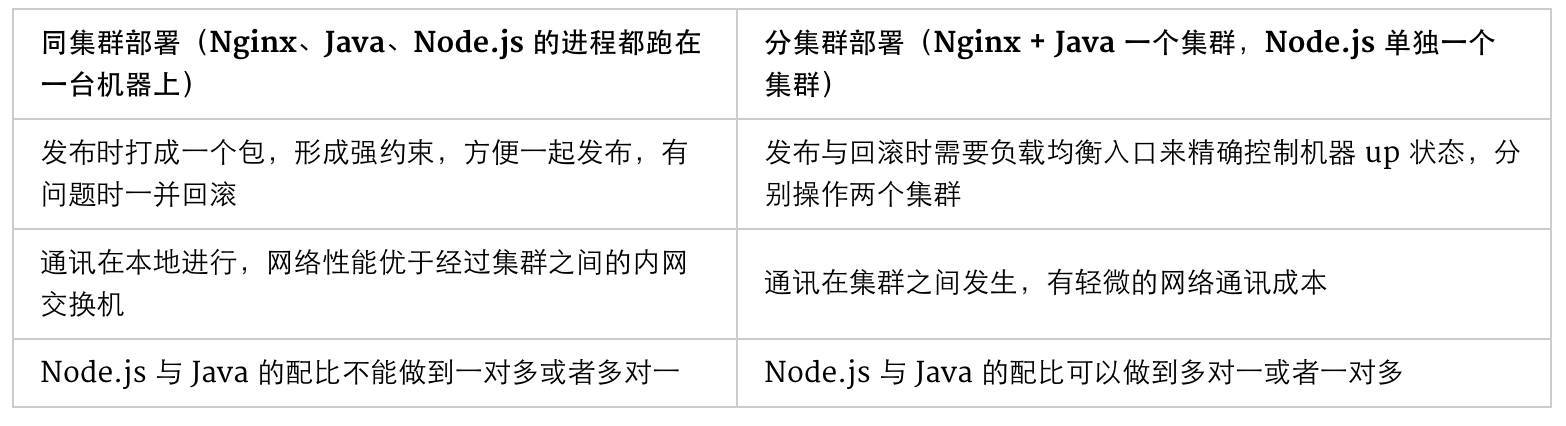
淘宝网收藏夹是一个拥有千万级日均 PV 的应用,对稳定性的要求性极高(事实上任何产品的线上不稳定都是不能接受的)。如果采用同集群部署方案,只需要一次文件分发,两次应用重启即可完成发布,万一需要回滚,也只需要操作一次基线包。性能上来说,同集群部署也有一些理论优势(虽然内网的交换机带宽与延时都是非常乐观的)。至于一对多或者多对一的关系,理论上可能做到服务器更加充分的利用,但相比稳定性上的要求,这一点并不那么急迫需要去解决。所以在收藏夹的改造中,我们选择了同集群部署方案。
灰度方式
为了保证最大程度的稳定,这次改造并没有直接将 Velocity 代码完全去掉。应用集群中有将近 100 台服务器,我们以服务器为粒度,逐渐引入流量。也就是说,虽然所有的服务器上都跑着 Java + Node.js 的进程,但 Nginx 上有没有相应的转发规则,决定了获取这台服务器上请求宝贝收藏的请求是否会经过 Node.js 来处理。其中 Nginx 的配置为:
location = "/item_collect.htm" {
proxy_pass http://127.0.0.1:6001; # Node.js 进程监听的端口
}
只有添加了这条 Nginx 规则的服务器,才会让 Node.js 来处理相应请求。通过 Nginx 配置,可以非常方便快捷地进行灰度流量的增加与减少,成本很低。如果遇到问题,可以直接将 Nginx 配置进行回滚,瞬间回到传统技术栈结构,解除险情。
第一次发布时,我们只有两台服务器上启用了这条规则,也就是说大致有不到 2% 的线上流量是走 Node.js 处理的,其余的流量的请求仍然由 Velocity 渲染。以后视情况逐步增加流量,最后在第三周,全部服务器都启用了。至此,生产环境 100% 流量的商品收藏页面都是经 Node.js 渲染出来的(可以查看源代码搜索 Node.js 关键字)。
转
灰度过程并不是一帆风顺的。在全量切流量之前,遇到了一些或大或小的问题。大部分与具体业务有关,值得借鉴的是一个技术细节相关的陷阱。
健康检查
在传统的架构中,负载均衡调度系统每隔一秒钟会对每台服务器 80 端口的特定 URL 发起一次 get 请求,根据返回的 HTTP Status Code 是否为 200 来判断该服务器是否正常工作。如果请求 1s 后超时或者 HTTP Status Code 不为 200,则不将任何流量引入该服务器,避免线上问题。
这个请求的路径是 Nginx -> Java -> Nginx,这意味着,只要返回了 200,那这台服务器的 Nginx 与 Java 都处于健康状态。引入 Node.js 后,这个路径变成了 Nginx -> Node.js -> Java -> Node.js -> Nginx。相应的代码为:
var http = require('http');
app.get('/status.taobao', function(req, res) {
http.get({
host: '127.1',
port: 7001,
path: '/status.taobao'
}, function(res) {
res.send(res.statusCode);
}).on('error', function(err) {
logger.error(err);
res.send(404);
});
});
但是在测试过程中,发现 Node.js 在转发这类请求的时候,每六七次就有一次会耗时几秒甚至十几秒才能得到 Java 端的返回。这样会导致负载均衡调度系统认为该服务器发生异常,随即切断流量,但实际上这台服务器是能够正常工作的。这显然是一个不小的问题。
排查一番发现,默认情况下, Node.js 会使用 HTTP Agent 这个类来创建 HTTP 连接,这个类实现了 socket 连接池,每个主机+端口对的连接数默认上限是 5。同时 HTTP Agent 类发起的请求中默认带上了 Connection: Keep-Alive,导致已返回的连接没有及时释放,后面发起的请求只能排队。
最后的解决办法有三种:
禁用 HTTP Agent,即在在调用 get 方法时额外添加参数 agent: false,最后的代码为:
var http = require('http');
app.get('/status.taobao', function(req, res) {
http.get({
host: '127.1',
port: 7001,
agent: false,
path: '/status.taobao'
}, function(res) {
res.send(res.statusCode);
}).on('error', function(err) {
logger.error(err);
res.send(404);
});
});
设置 http 对象的全局 socket 数量上限:
http.globalAgent.maxSockets = 1000;
在请求返回的时候及时主动断开连接:
http.get(options, function(res) {
}).on("socket", function (socket) {
socket.emit("agentRemove"); // 监听 socket 事件,在回调中派发 agentRemove 事件
});
实践上我们选择第一种方法。这么调整之后,健康检查就没有再发现其它问题了。
合
Node.js 与传统业务场景结合的实践才刚刚起步,仍然有大量值得深入挖掘的优化点。比比如,让 Java 应用彻底中心化后,是否可以考分集群部署,以提高服务器利用率。或者,发布与回滚的方式是否能更加灵活可控。等等细节,都值得再进一步研究。
加载全部内容