JavaScript中对循环语句的优化技巧深入探讨
人气:0循环是所有编程语言中最为重要的机制之一,几乎任何拥有实际意义的计算机程序(排序、查询等)都里不开循环。 而循环也正是程序优化中非常让人头疼的一环,我们往往需要不断去优化程序的复杂度,却因循环而纠结在时间复杂度和空间复杂度之间的抉择。
在 javascript 中,有3种原生循环,for () {}, while () {}和do {} while (),其中最为常用的要数for () {}。
然而for正是 javascript 工程师们在优化程序时最容易忽略的一种循环。
我们先来回顾一下for的基本知识。
javascript 的for语法继承自c语言,for循环的基本语法有两种使用方法。
1. 循环数组
for循环的基本语法
for ( /* 初始化 */2 /* 判断条件 */2 /* 循环处理 */ ) {
//... 逻辑代码
}
我们以一段实例代码来进行详细说明。
var array = [1, 2, 3, 4, 5];
var sum = 0;
for (var i = 0, len = array.length; i < len; ++i) {
sum += array[i];
}
console.log('The sum of the array\'s items is %d.', sum);
//=> The sum of the array's items is 15.
在这段代码中,我们首先定义并初始化了一个用存储待累加项的数组和一个总和整形变量。 接下来,我们开始进行循环。在该for循环的初始化代码中,我们也定义并初始化了两个变量: i(计数器)和len(循环数组长度的别名),当i小於len时,循环条件成立,执行逻辑代码;每次逻辑代码执行完毕以后,i自增1。
在循环的逻辑代码中,我们把当前循环的数组项加到总和变量中。
这个循环用流程图表示为如下:
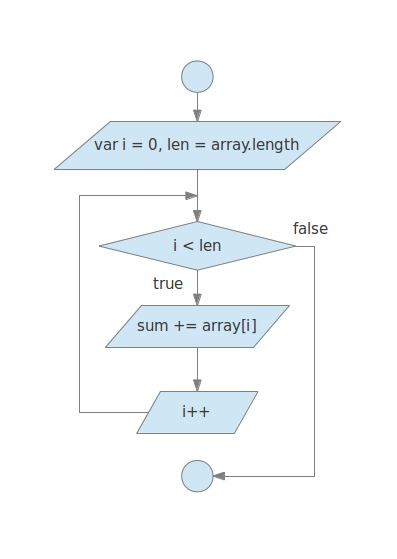
从这个流程图中我们不难发现,程序中真正的循环体不仅有我们的逻辑代码,还包含了实现循环自身的执行判断和循环处理。
这样,我们的优化思路就清晰了,我们可以从四个方面进行优化。
1.循环体前的初始化代码
2.循环体中的执行判断条件
3.逻辑代码
4.逻辑代码后的处理代码
ps: 其中第一点和第二点存在重要关系。
1.1 优化初始化代码和执行判断条件
我们先来看看一段大家都非常熟悉的代码。
// wrong!
for (var i = 02 i < list.length2 ++i) {
//... 逻辑代码
}
相信现在大部分写着 javascript 的工程师依然使用着这段看似狠正常的循环方法,但为什麼我在这里说它是错误的呢?
我们把这个循环的所有东西都拆开来看看:
1.初始化代码 - 这段循环只定义并初始化了一个计数器变量。
2.执行判断条件 - 当计数器小於list的长度时成立。
3.处理代码 - 计数器自增1。
我们再回顾一下上面的流程图,发现有什麼倪端没?
真正的循环体不仅有我们的逻辑代码,还包含了实现循环自身的执行判断和处理代码。 也就是说,i < list.length这个判断条件是每一次循环前都要执行的。而 javascript 中,对对象的属性或方法进行读取时,需要进行一次查询。
似乎明白了点什麼了吧?这个判断条件存在两个操作:1. 从list数组中查询length属性;2. 比较i与list.length的大小。
假设list数组含有 n 个元素,则程序需要在这个循环的执行判断中进行 2n 次操作。
如果我们把代码改成这样:
// Well
for (var i = 0, len = list.length; i < len; ++i) {
//...
}
在这段改进后的代码中,我们在循环体执行前的初始化代码中, 增加定义并初始化了一个len变量,用於存储list.length的值(关於变量、表达式、指针和值的相关内容将在第二篇中讨论)。 这样,我们在循环体中的执行判断中就无需再次对list数组进行属性查询,操作数为原先的一半。
以上步骤我们完善了算法的时间复杂度,而如果要继续优化空间复杂度的话,要如何做呢? 如果你的逻辑代码不受循环顺序限制,那你可以尝试以下优化方式。
for (var i = list.length - 1; i >= 0; --i) {
//...
}
这段代码通过把循环顺序倒置,把i计数器从最后一个元素下标(list.length - 1)开始,向前循环。 以达到把循环所需变量数减到 1 个,而且在执行判断中,降低了变量查询的次数,减少了执行 cpu 指令前的耗时。
1.2 优化逻辑代码
在循环中,我们得到循环当前的数组元素自然是为了对其或利用其进行一些操作,这不免会出现对该元素数次的调用。
var array = [
{ name: 'Will Wen Gunn', type: 'hentai' },
{ name: 'Vill Lin', type: 'moegril' }
];
for (var i = array.length - 1; i >= 0; --i) {
console.log('Name: %s', array[i].name);
console.log('He/She is a(n) %s', array[i].type);
console.log('\r\n');
}
/*=>
Name: Vill Lin
He/She is a(n) moegril
Name: Will Wen Gunn
He/She is a(n) hentai
*/
这段代码中,程序需要对每个数组元素的name和type属性进行查询。 如果数组有 n 个元素,程序就进行了 4n 次对象查询。
1. array[i]
2. array[i].name
3. array[i]
4. array[i].type
相信此时你一定想到了解决方法了吧,那就是把当前数组元素的值赋值到一个变量中,然后在逻辑代码中使用它。
var array = [
{ name: 'Will Wen Gunn', type: 'hentai' },
{ name: 'Vill Lin', type: 'moegril' }
];
var person = null;
for (var i = array.length - 1; i >= 0 && (person = array[i]); --i) {
console.log('Name: %s', person.name);
console.log('He/She is a(n) %s', person.type);
console.log('\r\n');
}
person = null;
这样看起来的确美观了不少。
1. array[i] => var person
2. person.name
3. person.type
有点像 emcascript5 中的foreach,不过这两者之间差别狠大,这里不多做解释。
ps:感谢大家的指正,经过实验得知,如果数组内的元素是直接传值定义的,则在循环中得到值一定是值,而非指针。 所以无论是定义表达式还是变量,都会有额外的内存空间请求。
1.3 优化处理代码
实际上,循环体中的处理代码并没有太多东西可以进行优化,i计数器也就是自增1就足够了。
ps:如果有什麼好的建议或方法,欢迎提供。:)
2. 循环对象(object)
在 javascript 中,for还可以对 object 的属性和方法进行历遍。 需要注意的是,for循环无法对对象所属的包装类型或是构造函数中原型属性、方法(prototype)进行历遍。
语法比循环数组还要简单。
for (/* 初始化 */ var key in object) {
//... 逻辑代码
}
我们常常这个方法来进行对对象的操作。
var person = {
'name' : 'Will Wen Gunn',
'type' : 'hentai',
'skill' : ['Programming', 'Photography', 'Speaking', 'etc']
};
for (var key in person) {
value = person[key];
// if the value is array, convert it to a string
if (value instanceof Array) {
value = value.join(', ');
}
console.log('%s: %s', key, value);
}
/*=>
name: Will Wen Gunn
type: hentai
skill: Programming, Photography, Speaking, etc
*/
如果你曾使用过 mongodb,那你对它的 query 机制绝对不会陌生。 因为 mongodb 的 query 机制就像是它的 api 的灵魂,灵活的 curd 操作方式为 mongodb 赢得了不少人气和发展动力。
而在 nanodb 的 mongo api 实现中,query 的实现方式就大面积地使用了循环对象。
var myDB = nano.db('myDB');
var myColl = myDB.collection('myColl');
var _cursor = myColl.find({
type : 'repo',
language : 'JavaScript'
});
_cursor
.sort({
star: 1
})
.toArray(function(err, rows) {
if (err)
return console.error(err);
console.log(rows);
});
而我们需要优化的,并非循环本身,而是对你需要进行历遍的对象进行优化。
就比如说 nanodb 中的 nanocollection 类,虽然表面看上去就是一个数组, 存有所有的元素,或是一个对象,用元素的 id 作为键,然后对元素进行存储。
但事实并非如此,曾经使用过 underscore 的同学应该会知道其中的_.invert方法。 这是一个相当有趣的方法,它把所传入的对象的键与值反过来。
var person = {
'name' : 'Will Wen Gunn',
'type' : 'hentai'
};
var _inverted = _.invert(person);
console.log(_inverted);
/*=>
{
'Will Wen Gunn' : 'name',
'hentai' : 'type'
}
*/
如果你是需要使用循环对象来对对象的某些属性的值进行查询,那你就可以尝试一下以下方法。
var person = {
'name' : 'Will Wen Gunn',
'type' : 'hentai'
};
var name = 'Will Wen Gunn';
var _inverted = _.invert(person);
if (_inverted[name] === 'name') {
console.log('Catched!');
}
//=> Catched!
然而利用for进行对象查询并没有太大的可优化之处,一切都还需从实际需求出发。: p
接下来我们来看看其他两种循环,while () {}和do {} while ()。 相信任何接收过计算机科学课程的朋友都这两个循环都不会陌生。他们唯一的区别就在与执行循环体的逻辑顺序。
while () {}的执行顺序与for () {}类似,执行判断在逻辑代码之前,不过省去了初始化和处理代码。
当给予的条件时,便执行逻辑代码,直到条件不再成立为止。
var sum = 0;
while (sum < 10) {
sum += sum + 1;
}
console.log(sum);
//=> 15
do {} while ()则是把执行判断放到了逻辑代码之后,也就是“先斩后奏”。
var sum = 0;
do {
sum += sum + 1;
} while (sum < 10);
console.log(sum);
//=> 15
while () {}与do {} while ()同样不需要计数器,而是通过某些条件来判断是否执行或继续执行逻辑代码。
3. while () {}和do {} while ()
while () {}和do {} while ()主要用於业务逻辑中,为达到某一目的而不断执行一系列操作,如任务队列。
但这两种循环是危险的,因为它们默认只受执行条件的控制,如果一旦逻辑代码内一直没有对执行判断產生任何影响,就会出现死循环。
var sum = 02
// warning!
while (sum < 10) {
sum = 1 + 12
}
这样的代码无异於while (true) {},所以在使用之前,必须明确执行条件和如何对执行条件產生影响的方法。
4. 善用循环控制语句
相信所有 javascript 工程师都使用过break语句,但continue语句却相对少用。 实际上,在不少优秀的 javascript 开源项目中,都能发现continue的身影。
为了地瞭解continue语句的作用,我们还是先来看看一段实例代码
// Node.js Broadcast Server
var net = require('net');
var util = require('util');
var broadcastServer = net.createServer();
// Client Store
broadcastServer.clients = [];
// Clients Broadcast Method
net.Socket.prototype.broadcast = function(msg) {
var clients = broadcastServer.clients;
// 获得发佈广播的客户端在集閤中的下标
var index = clients.indexOf(this);
for (var i = clients.length - 1; i >= 0; --i) {
if (i === index) {
// 如果为发佈广播的客户端,则结束当前循环体
continue;
}
currClient = clients[i];
if (!currClient.destroyed) {
currClient.write(
util.format(
'\r[Echo Client %s:%d] %s\nInput: ',
currClient.remoteAddress, currClient.remotePort, msg)
);
}
}
};
// A new client connected
broadcastServer.on('connection', function(client) {
broadcastServer.clients.push(client);
// Welcome
client.write('[Broadcast Server] Welcome!\nInput:');
client.broadcast(client, 'Joined!');
// Message handle
client.on('data', function(msg) {
client.broadcast(msg);
client.write('\rInput:');
});
// Disconnect handle
client.on('end', function() {
client.broadcast('Left!');
})
});
// Bind
broadcastServer.listen(8080, function() {
console.log('Broadcast Server bound.');
});
这段代码基於 node.js 的net模块实现了一个 broadcast server,在其中的broadcast方法中,我们使用了continue语句, 用以实现将信息向除发佈广播的客户端外的所有已建立连接的客户端。
代码内容相当简单, 当某一客户端需要向其他客户端发佈广播时,则调用该客户端所对应client对象的broadcast方法, 在broadcast方法中,程序会先获取当前客户端在以缓存的客户端 socket 集合中的位置下标, 然后对所有客户端 socket 进行循环发佈,当循环计数器来到之前获得的位置下标,则跳过当前循环体中的逻辑代码,继续下一个循环。
相信学习过 c/c++ 语言的工程师都会从各种地方得到这样一个忠告:“不要使用 goto 语句。”
而这个“臭名昭著”的goto语句其实就是一个代码流程控制器,关於goto语句的详细内容这里不会详细说明。 然而 javascript 没有明显的goto语句,但从break语句和continue语句中,不难发现 javascript 中goto的影子。
这是因为break语句和continue语句允许接受由一个定义好的 label 名称,以进行代码跳转。
我们来看看 mdn 提供的实例代码。
var i, j;
loop1:
for (i = 0; i < 3; i++) { //The first for statement is labeled "loop1"
loop2:
for (j = 0; j < 3; j++) { //The second for statement is labeled "loop2"
if (i == 1 && j == 1) {
continue loop1;
} else {
console.log("i = " + i + ", j = " + j);
}
}
}
// Output is:
// "i = 0, j = 0"
// "i = 0, j = 1"
// "i = 0, j = 2"
// "i = 1, j = 0"
// "i = 2, j = 0"
// "i = 2, j = 1"
// "i = 2, j = 2"
// Notice how it skips both "i = 1, j = 1" and "i = 1, j = 2"
在这段实例代码中,实现了两层循环,而在每层循环外都定义了一个label,用於之后的continue语句进行调用。
第一层循环在loop1的 label 中,也就是说在后面的程序中,如果在continue语句或break语句选择了loop1 label,就会跳出最外层循环。
第二层循环在顶层循环中的loop2的 label 中,若在continue语句或break语句中选择了loop2 label,就会回到顶层循环的循环体内。
通过使用循环控制语句,我们可以对原有的循环执行判断进行干涉,以至於可以构建出十分复杂的逻辑系统。 说句题外话,linux kernel 中有非常多的goto语句,至於为什麼还是能经常听到不要用goto语句之流的言论,就自己 google 吧。
5. 高级循环
5.1 展开循环
我们先来看看两段代码,你猜猜哪一个的性能更加。
// Setup
var array = [
["DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA"],
["DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA"],
["DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA"],
["DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA"],
["DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA"],
["DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA"],
["DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA"],
["DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA", "DATA"]
];
function process(item) {
// Do something with item
}
// Case 1
for (var i = array.length - 1; i >= 0; i--) {
for (var j = array[i].length - 1; j >= 0; i--) {
process(array[i][j]);
}
}
// Case 2
for (var i = array.length - 1; i >= 0; i = i - 4) {
for (var j = array[i].length - 1; j >= 0; j = j - 6) {
process(array[i][j]);
process(array[i][j - 1]);
process(array[i][j - 2]);
process(array[i][j - 3]);
process(array[i][j - 4]);
process(array[i][j - 5]);
}
for (var j = array[i - 1].length - 1; j >= 0; j = j - 6) {
process(array[i][j]);
process(array[i][j - 1]);
process(array[i][j - 2]);
process(array[i][j - 3]);
process(array[i][j - 4]);
process(array[i][j - 5]);
}
for (var j = array[i - 2].length - 1; j >= 0; j = j - 6) {
process(array[i][j]);
process(array[i][j - 1]);
process(array[i][j - 2]);
process(array[i][j - 3]);
process(array[i][j - 4]);
process(array[i][j - 5]);
}
for (var j = array[i - 3].length - 1; j >= 0; j = j - 6) {
process(array[i][j]);
process(array[i][j - 1]);
process(array[i][j - 2]);
process(array[i][j - 3]);
process(array[i][j - 4]);
process(array[i][j - 5]);
}
}
我需要对array中的所有子数组的元素进行历遍,有两种方案,一种是我们平常所使用的方法,另一种是把循环任务展开。 答案是 case 2 性能更好,因为在每 6 个元素之间的执行判断都全部删除了,自然比往常的都要快。
这里我们来看看一种更给力的解决方案。 如果一个业务环节中需要对大数据集进行迭代处理,而这个数据集从开始迭代起,数据量不会再改变, 那麼可以考虑採用一种名为 duff 装置的技术。这项技术是以其的创造者 tom duff 的名字来命名的, 这项技术最先实现於 c 语言。后来 jeff greenberg 将其移植到 javascript 中,并经过 andrew b. king 修改并提出了一种更为高效的版本。
//credit: Speed Up Up Your Site (New Riders, 2003)
var iterations = Math.floor(values.length / 8);
var leftover = values.length % 8;
var i = 0;
if (leftover > 0) {
do {
process(values[i++]);
} while (--leftover > 0);
}
do {
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
} while (--iterations > 0);
这种技术的工作原理是通过计算values的长度除以 8 以得到需要迭代的次数,并以math.floor()函数来保证结果为整数, 然后再计算不能被 8 整除时的餘数,并对这些元素单独进行处理,其餘则 8 次为单次展开次数来进行迭代。
我将这种装置再加以封装,可以得到一种带有异步味道的 api。
function duff(array, mapper) {
var n = Math.floor(array.length / 8);
var l = array.length % 8;
var i = 0;
if (l > 0) {
do {
mapper(array[i++]);
} while (--i > 0);
}
do {
mapper(array[i++]);
mapper(array[i++]);
mapper(array[i++]);
mapper(array[i++]);
mapper(array[i++]);
mapper(array[i++]);
mapper(array[i++]);
mapper(array[i++]);
} while (--n > 0);
}
duff([...], function(item) {
//...
});
这里是一组对於以上三种迭代解决方案的性能测试及其结果。http://jsperf.com/spreaded-loop
5.2 非原生循环
在任何编程语言中,能够实现循环的,不止语言所提供的原生循环语句,还可以通过其他方式来间接实现。
让我们先来温习一下高中数学的一点内容——数列的通项公式。
bacause
a[1] = 1
a[n] = 2 * a[n - 1] + 1
so
a[n] + 1 = 2 * a[n - 1] + 2
= 2 * (a[n - 1] + 1)
(a[n] + 1) / (a[n - 1] + 1) = 2
then
a[n] + 1 = (a[n] + 1) / (a[n - 1] + 1) * (a[n - 1] + 1) / (a[n - 2] + 1) * ... * (a[2] + 1) / (a[1] + 1) * (a[i] + 1)
a[n] + 1 = 2 * 2 * ... * 2 * 2
a[n] + 1 = 2^n
a[n] = 2^n - 1
final
a[n] = 2^n - 1
看了上面这段简单的演算,估计你也猜到我们将要讨论的内容了吧。 是的,我们还可以使用递归来实现循环。
递归是数学和计算机科学中非常重要的一种应用方法,它是指函数在其使用时调用其自身。
在 node.js 社区中,递归被用来实现一种非常重要的技术:中间件技术。 这是一段尚未公佈的新版本的 webjs 中的中间件实现代码。
/**
* Middlewares run method
* @param {String} url Current request url
* @param {Object} req the request object
* @param {Object} res the response object
* @param {Function} out Complete Callback
* @return {Function} the server
*/
server.runMiddlewares = function(url, req, res, out) {
var index = -1;
var middlewares = this._usingMiddlewares;
// run the next middleware if it is exists
function next(err) {
index++;
// current middleware
var curr = middlewares[index];
if (curr) {
var check = new RegExp(curr.route);
// Check the route
if (check.test(url)) {
try {
function later() {
debug('A middleware says it need to be later on %s', url);
// The dependencies do not right now
if (middlewares.indexOf(curr) !== middlewares.length - 1) {
_later(curr);
index--;
next();
} else {
debug('A middleware dependencies wrong');
// This middleware can not run
out();
}
}
// Run the middleware
if (utils.isFunc(curr.handler)) {
// Normal middleware function
curr.handler(req, res, next, later);
} else if (utils.isObject(curr.handler) && utils.isFunc(curr.handler.emit)) {
// Server object
curr.handler.emit('request', req, res, next, later);
} else {
// There are something wrong about the middleware
next();
}
} catch(err) {
next();
}
} else {
next();
}
} else {
// Out to next step of the pipeline
out();
}
}
// if the middleware depend on other middlewares,
// it can let it later to run
function _later(curr) {
var i = middlewares.indexOf(curr);
var _tmp1 = middlewares.slice(0, i);
_tmp1.push(middlewares[i + 1], curr);
var _tmp2 = middlewares.slice(i + 2);
[].push.apply(_tmp1, _tmp2);
middlewares = _tmp1;
}
// first middleware
next();
return this;
};
虽然这段代码看上去狠复杂,不过如果我们对其精简之后,就清晰许多了。
server.runMiddlewares = function(url, req, res, out) {
var index = -1;
var middlewares = this._usingMiddlewares;
// run the next middleware if it is exists
function next(err) {
index++;
// current middleware
var curr = middlewares[index];
if (curr) {
var check = new RegExp(curr.route);
// Check the route
if (check.test(url)) {
// run the current middleware
curr.handler(req, res, next);
} else {
next();
}
} else {
// Out to next step of the pipeline
out();
}
}
// first middleware
next();
return this;
};
递归之所以可以用於中间件系统的实现,是因为递归是最适合 node.js 中异步 i/o 的程序流程响应方式。
在这段中间件实现代码中,this._usingmiddlewares为循环数组,function next()是循环体,其中check.test(url)为执行判断条件, 而循环处理代码就是循环体中最前面的index计数器自增 1 和next函数自身的递归调用。
加载全部内容