从数据结构的角度分析 for each in 比 for in 快的多
人气:0之前听说火狐的JS引擎支持for each in的语法,例如下述的代码:
var arr = [10,20,30,40,50];
for each(var k in arr)
console.log(k);
即可直接遍历出arr数组的内容。
由于只有FireFox才支持,所以几乎所有的JS代码都不用这一特征。
不过在ActionScript里天生就支持for each的语法,不论Array还是Vector,还是Dictionary,只要是可枚举的对象都可以for in和for each in。
之前并没有感觉有太大的差异,为了懒得敲一个each单词,一直用熟悉的for in来遍历。
不过今天仔细琢磨了会,从数据结构的角度分析了下,觉得for in和for each in效率上有着本质的区别,无论是JS还是AS。
原因很简单:Array不是真正意义上的数组!
何为真正意义的数组?当然就是传统语言里type[]定义的数据类型,所有元素都是连续保存的。
“Array”虽然也是数组的意思,但熟悉JS的都知道,它其实是个非线性的伪数组,下标可以是任意数字。写入arr[1000000]并非真正申请容纳一百万个元素的空间,而是把1000000转换成相应的哈希值,对应到很小一块储存空间里,从而节省了大量内存。
例如有如下数组:
var arr = [];
arr[10] = 1000;
arr[20] = 2000;
arr[30] = 5000;
arr[40] = 8000;
arr[200] = 9000;
用for...in遍历Array,是个很累赘的过程:
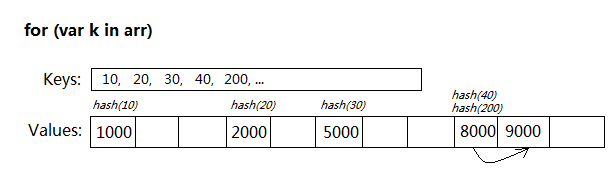
遍历时每次访问arr[k],都要进行一次Hash(k)计算,根据散列表的容量取模,如果存在冲突还得寻找最终的值结果。
如果支持for each...in的语法,其内部的数据结构就决定了会快很多:
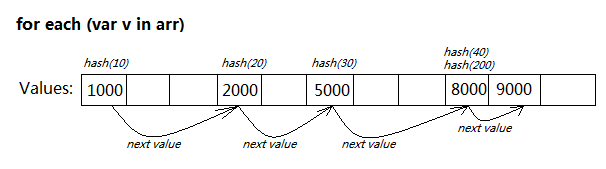
Array里直接把每个values作为节点,通过链表关联起来维护。每当有值添加或删除,就更新其链接关系。
当for each...in遍历时,只需从第一个节点往后迭代即可,无需任何Hash计算。
当然,对于AS3里Vector这样的线性数组来说,两者相差不大;同理,HTML5里支持二进制的数组ArrayBuffer也是如此。不过从理论上来看,即使arr是个连续的线性数组,for each in还是要快一点:
for...in遍历时,每次访问arr[k]都要进行下标越界检查;而for each in则根据内部链表,直接从底层反馈出迭代变量,节省了越界检查的过程。
加载全部内容