ibm官方资料把应用程序从 Internet Explorer 迁移到 Mozilla
人气:0Netscape 最初开发 Mozilla 浏览器的时候,明智地决定支持 W3C 标准。因此,Mozilla 和 Netscape Navigator 4.x 以及 Microsoft Internet Explorer 遗留代码不完全向后兼容,比如后面将提到 Mozilla 不支持 <layer>。Internet Explorer 4 这些在 W3C 标准的概念出现之前建立的浏览器继承了很多古怪之处。本文中将讨论 Mozilla 的特殊模式,它为 Internet Explorer 和其他遗留浏览器提供了强大的 HTML 向后兼容功能。
我还将讨论 Mozilla 支持的非标准技术,如 XMLHttpRequest 和富文本编辑,因为当时 W3C 还没有对应的标准。其中包括:
- HTML 4.01 和 XHTML 1.0/1.1
- 级联样式表(CSS):CSS Level 1、CSS Level 2 以及 CSS Level 3 的部分。
- 文档对象模型(DOM):DOM Level 1、 DOM Level 2 和 DOM Level 3 的部分
- 数学标记语言:MathML Version 2.0
- 可扩展标记语言(XML):XML 1.0、Namespaces in XML、Associating Style Sheets with XML Documents 1.0、Fragment Identifier for XML
- XSL 转换:XSLT 1.0
- XML Path 语言:XPath 1.0
- 资源描述框架:RDF
- 简单对象访问协议:SOAP 1.1
- ECMA-262 修订版 3(JavaScript 1.5):ECMA
虽然存在 Web 标准,但不同浏览器的行为并不完全相同(实际上同一个浏览器在不同的平台上行为也不相同)。很多浏览器,如 Internet Explorer 依然支持 W3C 之前的、从未在 W3C 符合浏览器中获得广泛支持的 API。
深入讨论 Mozilla 和 Internet Explorer 的区别之前,首先介绍一下使 Web 应用程序具备可扩展性以便日后增加新浏览器支持的一些基本方法。
因为不同的浏览器有时会为同样的功能使用不同的 API,因此经常会在代码中看到很多 if() else() 块,来区别对待不同的浏览器。下面的代码块用于 Internet Explorer:
. . . var elm; if (ns4) elm = document.layers["myID"]; else if (ie4) elm = document.all["myID"]; |
上述代码不具备可扩展性,如果需要支持新的浏览器,必须修改 Web 应用程序中所有这样的代码块。
避免为新浏览器重新编码最简单的办法就是抽象功能。不要使用层层嵌套的 if() else() 块,把通用的任务抽象成单独的函数可以提高效率。这样不但代码更易于阅读,还便于增加新客户机支持:
var elm = getElmById("myID");
function getElmById(aID){
var element = null;
if (isMozilla || isIE5)
?element = document.getElementById(aID)
else if (isNetscape4)
element = document.layers[aID]
else if (isIE4)
element = document.all[aID];
return element;
}
|
上述代码仍然存在浏览器嗅探 或者检测用户使用何种浏览器的问题。浏览器嗅探一般通过用户代理完成,比如:
Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.5) Gecko/20031016 |
虽然使用用户代理来嗅探浏览器提供了所用浏览器的详细信息,但是出现新的浏览器版本时处理用户代理的代码可能出错,因而需要修改代码。
如果浏览器的类型无关紧要(假设禁止不支持的浏览器访问 Web 应用程序),最好通过浏览器本身的能力来嗅探。一般可以通过测试需要的 JavaScript 功能来完成。比如,与其使用:
if (isMozilla || isIE5) |
不如用:
if (document.getElementById) |
这样不用任何修改,在其他支持该方法的浏览器如 Opera 或 Safari 上也能工作。
但是如果准确性很重要,比如要验证浏览器是否满足 Web 应用程序的版本要求或者尝试避免某个 bug,则必须使用用户代理嗅探。
JavaScript 还允许使用内嵌条件语句,有助于提高代码的可读性:
var foo = (condition) ? conditionIsTrue : conditionIsFalse; |
比如,要检索一个元素,可以用如下代码:
function getElement(aID){
return (document.getElementById) ? document.getElementById(aID)
: document.all[aID];
}
|
|
Mozilla 和 Internet Explorer 的区别
首先讨论 Mozilla 和 Internet Explorer 在 HTML 行为方式上的区别。
遗留浏览器在 HTML 中引入了工具提示,在链接上显示 alt 属性作为工具提示的内容。最新的 W3C HTML 规范增加了 title 属性,用于包含链接的详细说明。现代浏览器应该使用 title 属性显示工具提示,Mozilla 仅支持用该属性显示工具提示而不能用 alt 属性。
HTML 标记可以包含多种实体,W3 标准体 专门作了规定。可以通过数字或者字符引用来引用这些实体。比如,可以用 #160 或者等价的字符引用 来引用空白字符 。
一些旧式浏览器,如 Internet Explorer,有一些怪异的地方,比如允许用正常文本内容替换实体后面的分号(;):
Foo Foo |
Mozilla 将把上面的 呈现为空格,虽然违反了 W3C 规范。如果后面紧跟着更多字符,浏览器就不能解析 ,如:
12345 |
这样的代码在 Mozilla 中无效,因为违反了 W3 标准。为了避免浏览器的差异,应坚持使用正确的形式( )。
|
文档对象模型(DOM)是包含文档元素的树状结构。可以通过 JavaScript API 来操纵它,对此 W3C 已有标准。但是在 W3C 标准化之前,Netscape 4 和 Internet Explorer 4 以类似的方式实现了这种 API。Mozilla 仅实现了 W3C 标准不支持的那些遗留 API。
未按照跨浏览器的方式检索元素的引用,应使用 document.getElementById(aID),该方法可用于 Internet Explorer 5.5+、Mozilla,是 DOM Level 1 规范的一部分。
Mozilla 不支持通过 document.elementName 甚至按照元素名来访问元素,而 Internet Explorer 则支持这种方法(也称为全局名称空间污染)。Mozilla 也不支持 Netscape 4 的 document.layers 方法和 Internet Explorer 的 document.all 方法。除了 document.getElementById 可以检索元素之外,还可用 document.layers 和 document.all 获得具有特定标签名称的全部文档元素列表,比如所有的 <div> 元素。
W3C DOM Level 1 使用 getElementsByTagName() 方法获得所有相同标签名的元素的引用。该方法在 JavaScript 中返回一个数组,可用于 document 元素,也可用于其他节点只检索对应的子树。要获得 DOM 树中所有元素的列表,可使用 getElementsByTagName(*)。
表 1 中列出了 DOM Level 1 方法,大部分用于把元素移动到特定位置或切换其可视性(菜单、动画)。Netscape 4 使用 <layer> 标签(Mozilla 不支持)作为可以任意定位的 HTML 元素。在 Mozilla 中,可使用 <div> 标签定位元素,Internet Explorer 也用它,HTML 规范中也包含它。
表 1. 用于访问元素的方法
| 方法 | 说明 |
| document.getElementById( aId ) | 返回具有指定 ID 的元素的引用。 |
| document.getElementsByTagName( aTagName ) | 返回文档中具有指定名称的元素数组。 |
Mozilla 通过 JavaScript 支持遍历 DOM 树的 W3C DOM API(如表 2 所示)。文档中每个节点都可使用这些 API 方法,可以在任何方向上遍历树。Internet Explorer 也支持这些 API,还支持原来用于遍历 DOM 树的 API,比如 children 属性。
表 2. 用于遍历 DOM 的方法
| 属性/方法 | 说明 | ||||||||||||||||||||||||||
| childNodes | 返回元素所有子节点的数组。 | ||||||||||||||||||||||||||
| firstChild | 返回元素的第一个子节点。 | ||||||||||||||||||||||||||
| getAttribute( aAttributeName ) | 返回指定属性的值。 | ||||||||||||||||||||||||||
| hasAttribute( aAttributeName ) | 返回一个 Boolean 值表明当前节点是否包含指定名称的属性。 | ||||||||||||||||||||||||||
| hasChildNodes() | 返回一个布尔指表明当前节点是否有子节点。 | ||||||||||||||||||||||||||
| lastChild | 返回元素的最后一个子节点。 | ||||||||||||||||||||||||||
| nextSibling | 返回紧接于当前节点之后的节点。 | ||||||||||||||||||||||||||
| nodeName | 用字符串返回当前节点的名称。 | ||||||||||||||||||||||||||
| nodeType | 返回当前节点的类型。
| ||||||||||||||||||||||||||
| nodeValue | 返回当前节点的值。对于包含文本的节点,如文本和注释节点返回其字符串值。对于属性节点返回属性值。其他节点返回 null。 | ||||||||||||||||||||||||||
| ownerDocument | 返回包含当前节点的 document 对象。 | ||||||||||||||||||||||||||
| parentNode | 返回当前节点的父节点。 | ||||||||||||||||||||||||||
| previousSibling | 返回当前节点之前的相邻节点。 | ||||||||||||||||||||||||||
| removeAttribute( aName ) | 从当前节点中删除指定的属性。 | ||||||||||||||||||||||||||
| setAttribute( aName, aValue ) | 设置指定属性的值。 |
Internet Explorer 有一种非标准的特殊行为,这些 API 很多跳过(比如)新行字符生成的空白文本节点。Mozilla 则不跳过,因此有时候需要区分这些节点。每个节点都有一个 nodeType 属性指定了节点类型。比如,元素节点类型是 1,文本节点是 3,而注释节点是 8。仅处理元素节点最好的办法是遍历所有子节点,然后处理那些 nodeType 为 1 的节点:
HTML:
<div id="foo">
<span>Test</span>
c </div>
JavaScript:
var myDiv = document.getElementById("foo");
var myChildren = myXMLDoc.childNodes;
for (var i = 0; i < myChildren.length; i++) {
if (myChildren[i].nodeType == 1){
// element node
}
}
|
Mozilla 支持向 DOM 动态增加内容的遗留方法,如 document.write、document.open 和 document.close。Mozilla 也支持 Internet Explorer 的 InnerHTML 方法,该方法基本上可以在任何节点上使用。但是不支持 OuterHTML(围绕着元素添加标记,标准中也没有等价的方法)和 innerText(设置节点的文本值,在 Mozilla 中可使用 textContent)。
Internet Explorer 有一些非标准的、Mozilla 不支持的内容操作方法,包括检索值、插入文本以及邻近某个节点插入元素,比如 getAdjacentElement 和 insertAdjacentHTML。表 3 说明了 W3C 标准和 Mozilla 操纵内容的方法,这些方法适用于任何 DOM 节点。
表 3. Mozilla 用于操纵内容的方法
| 方法 | 说明 |
| appendChild( aNode ) | 创建新的子节点。返回新建子节点的引用。 |
| cloneNode( aDeep ) | 创建调用节点的副本并返回。如果 aDeep 为 true,则复制该节点的整个子树。 |
| createElement( aTagName ) | 创建并返回一个 aTagName 指定类型的无父 DOM 节点。 |
| createTextNode( aTextValue ) | 创建并返回一个新的无父 DOM 文本节点,值由 aTextValue 指定。 |
| insertBefore( aNewNode, aChildNode ) | 在 aChildNode 前插入 aNewNode,前者必须是当前节点的子节点。 |
| removeChild( aChildNode ) | 删除 aChildNode 并返回对它的引用。 |
| replaceChild( aNewNode, aChildNode ) | 用 aNewNode 替换 aChildNode 并返回被删除节点的引用。 |
出于性能方面的原因,可以在内存中创建文档而不是处理已有文档的 DOM。DOM Level 1 Core 引入了文档片断,这是一种轻型文档包含一般文档接口的一个子集。比如没有 getElementById 但是有 appendChild。很容易向已有文档添加文档片断。
Mozilla 使用 document.createDocumentFragment() 创建文档片断,该方法返回一个空的文档片断。
但是,Internet Explorer 的文档片断实现没有遵循 W3C 标准,仅仅返回一般的文档。
|
Mozilla 和 Internet Explorer 的多数差异都和 JavaScript 有关。但问题通常源自浏览器向 JavaScript 公开的 API,比如 DOM 钩子。两种浏览器在核心 JavaScript 上区别不大,遇到的问题通常和时间有关。
Date 惟一的区别是 getYear 方法。根据 ECMAScript 规范(这是 JavaScript 所遵循的规范),该方法没有解决千年问题,在 2004 年运行 new Date().getYear() 将返回“104”。根据 ECMAScript 规范,getYear 返回的年份减去 1900 最初是为了在 1998 年返回“98”。ECMAScript Version 3 废止了 getYear,用 getFullYear() 代替。Internet Explorer 修改了 getYear() 使其和 getFullYear() 类似,消除了千年问题,而 Mozilla 坚持采用标准的行为方式。
不同的浏览器执行 JavaScript 的方式是不同的。比如,下列代码假设 script 块执行的时候 div 节点已经存在于 DOM 中:
...
<div id="foo">Loading...</div>
<script>
document.getElementById("foo").innerHTML = "Done.";
</script>
|
但是并不能保证这一点。为了保证所有的元素已经存在,应该对 <body> 元素使用 onload 事件处理程序:
<body onload="doFinish()">
<div id="foo">Loading...</div>
<script>
function doFinish() {
var element = document.getElementById("foo");
element.innerHTML = "Done.";
}
</script>
...
|
这类与时间有关的问题也和硬件有关,速度慢的系统可能会发现速度快的系统隐藏起来的 bug。一个具体的例子是 window.open,它打开新的窗口:
<script>
function doOpenWindow(){
var myWindow = window.open("about:blank");
myWindow.location.href = "http://www.ibm.com";
}
</script>
|
这段代码的问题在于 window.open 是异步的,在窗口打开之前没有阻塞 JavaScript 的执行。因此,window.open 后面的行有可能在新窗口打开之前执行。可以在新窗口的 onload 处理程序中解决这个问题,然后回调打开它的窗口(使用 window.opener)。
JavaScript 可以通过 document.write 即时用字符串生成 HTML。主要的问题在于,如果内嵌在 HTML 文档(因此也在一个 <script> 标签中)的 JavaScript 生成的 HTML 又包含 <script> 标签怎么办。如果文档采用 严格呈现模式,就会把字符串中的 </script> 解释成外层 <script> 的结束标签。下面的代码很好地说明了这一点:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
...
<script>
document.write("<script>alert("Hello")</script>")
</script>
|
由于该页面采用严格模式,Mozilla 解析器就会看到第一个 <script> 并解析它直到发现第一个结束标签,即第一个 </script> 。这是因为解析器不知道 JavaScript(或者其他任何语言)何时采用严格模式。在特殊模式下,解析器在解析的过程中分析 JavaScript(因而降低了速度)。Internet Explorer 总是采用特殊模式,因此不真正支持 XHTML。为了在 Mozilla 中使用严格模式,需要将字符串分解成两部分:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
...
<script>
document.write("<script>alert("Hello")</" + "script>")
</script>
|
Mozilla 提供了多种方法调试为 Internet Explorer 创建的应用程序中的 JavaScript 相关问题。第一个工具是内置的 JavaScript 控制台,如图 1 所示,它记录了错误和警告信息。在 Mozilla 中选择 Tools -> Web Development -> JavaScript Console,或者在 Firefox(来自 Mozilla 的独立浏览器产品)中选择 Tools -> JavaScript Console 就能打开它。
图 1. JavaScript 控制台
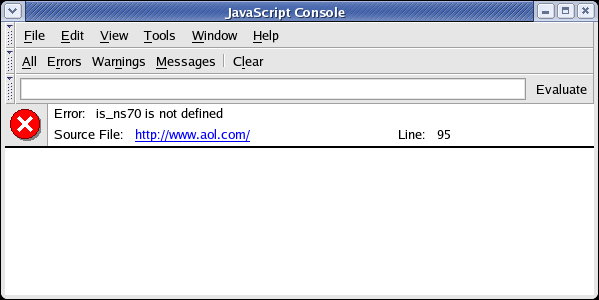
JavaScript 控制台可以显示完整的日志列表,也可以分别显示错误、警告和消息。图 1 中的错误消息表明,aol.com 第 95 行访问的变量 is_ns70 不存在。单击该链接可以打开 Mozilla 内部的查看源代码窗口,突出显示出错的一行。
控制台还允许对 JavaScript 求值。要计算输入的 JavaScript 语法,在输入字段中输入 1+1 然后按 Evaluate,结果如图 2 所示。
图 2. JavaScript 控制台求值
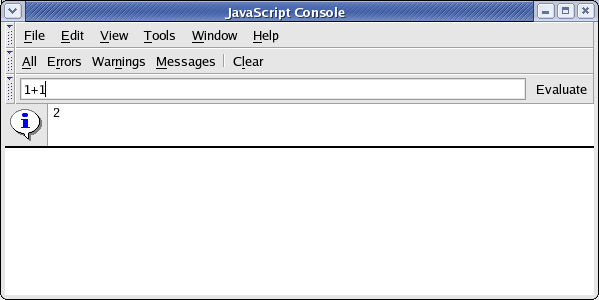
Mozilla 的 JavaScript 引擎内建了对调试的支持,从而为 JavaScript 开发人员提供了强大的工具。图 3 所示的 Venkman 是一种强大的跨平台 JavaScript 调试器,它与 Mozilla 集成在一起。它通常和 Mozilla 发行包捆绑在一起,可以通过选择 Tools -> Web Development -> JavaScript Debugger 打开它。Firefox 没有捆绑这个调试器,但是可以从 http://www.mozilla.org/projects/venkman/ 下载安装。还可以在开发页面上找到相关教程,开发页面的 URL 为 http://www.hacksrus.com/~ginda/venkman/。
图 3. Mozilla 的 JavaScript 调试器

JavaScript 调试器可以调试在 Mozilla 浏览器窗口中运行的 JavaScript。它支持断点管理、查看调用栈和变量/对象检查这样的标准调试特性。所有特性都可通过用户界面或者调试器的交互控制台来访问。通过控制台,可以在和调试的 JavaScript 代码同一作用域内执行任何 JavaScript。
和 Internet Explorer 及其他浏览器相比,Mozilla 对级联样式表(CSS)的支持是最好的,包括 CSS1、CSS2 的全部和 CSS3 的一部分。
对于下面提到的多数问题,Mozilla 都会在 JavaScript 控制台中添加错误或警告记录。如果遇到和 CSS 有关的问题请检查 JavaScript 控制台。
与 CSS 有关的最常见的问题就是:未应用所引用的 CSS 文件中的 CSS 定义。这通常是因为服务器为 CSS 文件提供了错误的 mimetype。CSS 规范指出,CSS 文件的 MIME 类型应该是 text/css。Mozilla 遵守这一点,在严格标准模式下只有这种 MIME 类型的 CSS 文件才会被加载。Internet Explorer 总是加载 CSS 文件,无论使用什么 mimetype。如果以严格的文档类型开始,则该网页被认为是严格标准模式。为了解决这个问题,可以让服务器发送正确的 mimetype 或者删除文档类型。下一节将进一步讨论文档类型。
很多 Web 应用程序没有在 CSS 中使用单位,尤其是如果使用 JavaScript 设置 CSS。Mozilla 允许这样做,只要页面不以严格模式呈现。因为 Internet Explorer 不支持真正的 XHTML,没有指定单位也不必担心。如果页面处于严格标准模式而没有使用单位,则 Mozilla 将忽略该样式:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html>
<body>
// works in strict mode
<div style="width:40px; border:1px solid black;">
Text
</div>
// will fail in strict mode
<div style="width:40; border:1px solid black;">
Text
</div>
</body>
</html>
|
因为上面的例子使用了严格的文档类型,页面以严格标准模式呈现。第一个 div 的宽度为 40px,因为使用了单位;但是第二个 div 没有设置宽度,因此使用默认值 100%。如果通过 JavaScript 设置宽度,情况也是一样。
因为 Mozilla 支持 CSS 标准,它也支持通过 JavaScript 设置 CSS 的 CSS DOM 标准。可以通过元素的 style 成员访问、删除和修改元素的 CSS 规则:
<div id="myDiv" border:1px solid black;">
Text
</div>
<script>
var myElm = document.getElementById("myDiv");
myElm.style.width = "40px";
</script>
|
通过这种方法可以访问每一个 CSS 属性。同样,如果网页采用严格模式,就必须设置单位,否则 Mozilla 将忽略该命令。
在 Mozilla 和 Internet Explorer 中查询一个值,比如说 .style.width,返回值也包含单位,就是说是一个字符串。可用 parseFloat("40px") 将字符串转换成数字。
CSS 增加了溢出的概念,允许定义如何处理溢出;比如,如果指定高度的 div 的实际高度超出的时候。 height.CSS 标准规定如果这种情况下没有定义溢出行为,则 div 内容就会溢出。但是,Internet Explorer 没有遵循这一点,而是扩展 div 的高度以便容纳其内容。下面的例子说明了这种差异:
<div style="height:100px; border: 1px solid black;">
<div style="height:150px; border: 1px solid red;
margin:10px;">
a
</div>
</div>
|
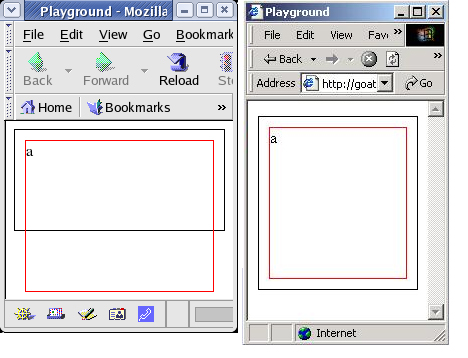
从图 4 可以看出,Mozilla 是按照标准规定处理的。标准规定,这种情况下内层的 div 溢出到底线,因为内层的内容比外层元素还高。如果愿意采用 Internet Explorer 的方式,只要不指定外层元素的高度即可。
图 4. DIV 溢出
Internet Explorer 的非标准 CSS 悬停行为出现在很多 IBM 网站上。Mozilla 中悬停的时候一般通过改变文本样式来表明自身,但是 Internet Explorer 没有这种行为。这是因为 a:hover CSS 选择器在 Internet Explorer 中和 <a href="" /> 匹配,但是与 <a name="" /> 不匹配,后者在 HTML 用于建立锚链接元素。文本变化是因为作者用锚设置标记包围了该区域:
CSS:
a:hover {color:green;}
HTML:
<a href="foo.com">This should turn green when you hover over it.</a>
<a name="anchor-name">
This should change color when hovered over, but doesn't
in Internet Explorer.
</a>
|
Mozilla 正确地遵循了 CSS 规范,该例中文本的颜色变成绿色。有两种方法可以让 Mozilla 的行为和 Internet Explorer 一样,即悬停的时候不改变文本颜色:
- 首先将 CSS 规则改为
a:link:hover {color:green;},这样只有链接(带有href属性)才会改变颜色。 - 或者修改标记在文本开始之前加入
<a />,修改后锚仍然能正常工作。
|
老的浏览器如 Internet Explorer 4 在特定情况下会以所谓的特殊模式呈现。虽然 Mozilla 的目标是成为符合标准的浏览器,但是提供了三种模式支持带有这些特异行为的较老的网页。页面的内容和交付决定了 Mozilla 使用哪种模式。Mozilla 在 View -> Page Info(或 Ctrl-i)中列出呈现模式。页面选择哪种模式取决于文档类型。
文档类型(doctypes,即文档类型声明的缩写)如下所示:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
蓝色部分称为公共标识符,绿色的部分称为系统标识符,是一个 URI。
标准模式是最严格的呈现模式,根据 W3C HTML 和 CSS 规范呈现页面,不支持任何特异情况。如果满足下列条件,Mozilla 使用该模式:
- 如果页面以
text/xmlmimetype 或者其他 XML 或 XHTML mimetype 发送 - IBM 文档类型之外的任何“DOCTYPE HTML SYSTEM”文档类型(比如
<!DOCTYPE HTML SYSTEM "http://www.w3.org/TR/REC-html40/strict.dtd">) - 没 DTD 的文档类型或未知的文档类型
Mozilla 引入准标准模式有一个原因:CSS 2 中的一部分破坏了基于小图片在表格中精确布局的设计。不是为用户组成一幅完整的图片,而是在每个小图片后面都带一段间隙。图 5 所示的旧的 IBM 主页给出了一个例子。
图 5. 图片间隙

除了图片间隙问题外,准标准模式基本上和标准模式完全相同。这个问题常常出现在符合标准的页面上,并造成不正确的显示。
Mozilla 在下列情况下使用准标准模式。
- 任何 “宽松” 文档类型(如
<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN">、<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">) - IBM 文档类型(
<!DOCTYPE html SYSTEM "http://www.ibm.comhttps://img.qb5200.com/download-x/datahttps://img.qb5200.com/download-x/dtd/v11/ibmxhtml1-transitional.dtd">)
请阅读相关资料进一步了解 图片间隙问题。
目前 Web 上到处充斥着不合法的 HTML 标记以及依靠浏览器的缺陷工作的标记。早在老的 Netscape 浏览器当还是市场领先者的时候就有这方面缺陷。Internet Explorer 出现时,为适应当时的内容而模仿了这些缺陷。随着新的浏览器进入市场,原来的这些缺陷,通常称为特异情况(quirks),为保持向后兼容大部分保留了下来。Mozilla 在特殊呈现模式中支持很多这样的特异情况。要注意,由于这些特异情况,页面与完全符合标准的情形相比呈现速度更慢。多数网页都用这种模式呈现。
Mozilla 在下面情况下使用特殊模式:
- 没有指定文档类型
- 文档类型没有系统标识符(比如
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">)
如果希望进一步了解相关内容,请阅读 List of Quirks 和 List of Doctypes and What Modes They Cause。
|
在事件方面,Mozilla 和 Internet Explorer 几乎完全不同。Mozilla 事件模型按照 W3C 和 Netscape 模型。在 Internet Explorer 中,如果从事件中调用一个函数,可以通过 window.event 访问 event 对象。Mozilla 把 event 对象传递给事件处理程序。必须通过参数把该对象明确传递给调用的函数。下面是一个跨浏览器事件处理的例子:
<div onclick="handleEvent(event)">Click me!</div> <script> function handleEvent(aEvent){ // if aEvent is null, means the Internet Explorer event model, // so get window.event. var myEvent = aEvent ? aEvent : window.event; } </script> |
事件对象公开的属性和函数的名称在 Mozilla 和 Internet Explorer 中也常常不同,如表 4 所示。
表 4. Mozilla 和 Internet Explorer 中的事件属性
| Internet Explorer 名称 | Mozilla 名称 | 说明 |
| altKey | altKey | 布尔属性,表示事件过程中是否按下了 alt 键。 |
| cancelBubble | stopPropagation() | 用于停止事件进一步沿树上行。 |
| clientX | clientX | 事件的 X 坐标,相对于客户机。 |
| clientY | clientY | 事件的 Y 坐标,相对于客户机。 |
| ctrlKey | ctrlKey | 布尔属性,表明事件过程中是否按下了 Ctrl 键。 |
| fromElement | relatedTarget | 对于鼠标事件来说,指的是鼠标从上移走的那个元素。 |
| keyCode | keyCode | 用于键盘事件,表示所按下的键的数字。对于鼠标事件,其值为 0。 |
| returnValue | preventDefault() | 用于防止执行事件的默认动作。 |
| screenX | screenX | 事件的 X 坐标,相对于屏幕。 |
| screenX | screenY | 事件的 Y 坐标,相对于屏幕。 |
| shiftKey | shiftKey | 布尔属性,表明事件过程中是否按下了 Shift 键。 |
| srcElement | target | 事件最初指派到的元素。 |
| toElement | currentTarget | 用于鼠标事件,鼠标移动到的当前元素。 |
| type | type | 返回事件名。 |
Mozilla 提供了两种方法通过 JavaScript 附加事件。第一种是所有浏览器都具备的,即直接在对象上设置 event 属性。要设置 click 事件处理程序,可以向该对象的 onclick 属性传递一个函数引用:
<div id="myDiv">Click me!</div>
<script>
function handleEvent(aEvent){
// if aEvent is null, means the Internet Explorer event model,
// so get window.event.
var myEvent = aEvent ? aEvent : window.event;
}
function onPageLoad(){
document.getElementById("myDiv").onclick = handleEvent;
}
</script>
|
Mozilla 完全支持向 DOM 节点附加监听器的 W3C 标准方式。使用 addEventListener() 和 removeEventListener() 方法的好处是能够对同一个事件类型添加多个监听器。两种方法都需要三个参数:事件类型、函数引用以及监听器是否能够在捕获阶段捕获事件的布尔值。如果这个布尔参数设为 false,则只捕获上行的事件。W3C 事件有三个阶段:捕获、到达目标和上行。每个事件对象都有一个 eventPhase 属性用数字表示所处的阶段(从 0 开始)。每当触发一个事件时,事件都从 DOM 的最外层元素即 DOM 树最顶端的元素开始。然后沿着到目标最近的路径在 DOM 中下行,称为捕获阶段。事件到达目标的时候称为目标抵达阶段。到达目标后,事件再沿着 DOM 树回到最外层的节点,称为上行(冒泡)。Internet Explorer 的事件模型只有上行阶段,因此,只要将第三个参数设置为 false 就能模仿 Internet Explorer 的行为:
<div id="myDiv">Click me!</div>
<script>
function handleEvent(aEvent) {
// if aEvent is null, it is the Internet Explorer event model,
// so get window.event.
var myEvent = aEvent ? aEvent : window.event;
}
function onPageLoad() {
var element = document.getElementById("myDiv");
element.addEventListener("click", handleEvent, false);
}
</script>
|
与设置属性相比,addEventListener() 和 removeEventListener() 的优点是可以为同一个事件设置多个监听器,调用不同的函数。因此,删除事件监听器要求传递的三个参数和添加时设定的三个参数完全相同。
Mozilla 不支持 Internet Explorer 将“script”标签转变成事件处理程序的方法,后者为“script”增加了 for 和 event 属性(如表 5 所示)。也不支持 attachEvent 和 detachEvent 方法。相反,应该使用 addEventListener 和 removeEventListener 方法。Internet Explorer 不支持 W3C 事件规范。
表 5. Mozilla 与 Internet Explorer 的事件方法差异
| Internet Explorer 方法 | Mozilla 方法 | 说明 |
| attachEvent(aEventType, aFunctionReference) | addEventListener(aEventType, aFunctionReference, aUseCapture) | 向 DOM 元素添加事件监听器。 |
| detachEvent(aEventType, aFunctionReference) | removeEventListener(aEventType, aFunctionReference, aUseCapture) | 从 DOM 元素删除事件监听器。 |
|
虽然 Mozilla 自诩为最符合 W3C 标准的浏览器,但是如果不存在相关的 W3C 标准,它也可以支持非标准的功能,如 innerHTML 和富文本编辑。
Mozilla 1.3 实现了 Internet Explorer 的 designMode 特性,将 HTML 文档变成了一个富文本编辑器字段。变成了编辑器之后,就可以通过 execCommand 在文档上执行命令。Mozilla 不支持 Internet Explorer 的 contentEditable 属性,后者允许编辑任何组件。可以使用 iframe 增加富文本编辑器。
Mozilla 支持通过 IFrameElm.contentDocument 访问 iframe 文档对象的 W3C 标准,而 Internet Explorer 要求通过 document.frames["name"] 访问它,然后再访问最终得到的 document:
function getIFrameDocument(aID){
var rv = null;
// if contentDocument exists, W3C compliant (Mozilla)
if (document.getElementById(aID).contentDocument){
rv = document.getElementById(aID).contentDocument;
} else {
// IE
?rv = document.frames[aID].document;
}
return rv;
}
|
Mozilla 和 Internet Explorer 的另一个区别是富文本编辑器所创建的 HTML。Mozilla 默认对生成的标记使用 CSS。但是,Mozilla 允许使用 useCSS execCommand 分别改为 true 和 false 来在 HTML 和 CSS 之间切换。Internet Explorer 总是使用 HTML 标记。
Mozilla (CSS): <span style="color: blue;">Big Blue</span> Mozilla (HTML): <font color="blue">Big Blue</font> Internet Explorer: <FONT color="blue">Big Blue</FONT> |
下面列出了 Mozilla 支持的 execCommand 命令:
表 6. 富文本编辑命令
| 命令名 | 说明 | 参数 |
| bold | 决定所选内容是否以粗体显示。 | --- |
| createlink | 从选中的文本创建 HTML 链接。 | 链接的 URL |
| delete | 删除所选内容。 | --- |
| fontname | 改变所选文本使用的字体。 | 使用的字体名(比如 Arial) |
| fontsize | 改变所选文本的字体大小。 | 使用的字体大小 |
| fontcolor | 改变所选文本使用的字体颜色。 | 使用的颜色 |
| indent | 缩进光标所在的块。 | --- |
| inserthorizontalrule | 在鼠标位置插入 <hr> 元素。 | --- |
| insertimage | 在鼠标位置插入图片。 | 图片的 URL |
| insertorderedlist | 在当前位置插入有序列表(<ol>)元素。 | --- |
| insertunorderedlist | 在光标位置插入无序列表(<ul>)元素。 | --- |
| italic | 切换所选内容的的斜体属性。 | --- |
| justifycenter | 当前行居中对齐。 | --- |
| justifyleft | 当前行左对齐。 | --- |
| justifyright | 当前行右对齐。 | --- |
| outdent | 减少光标所在块的缩进。 | --- |
| redo | 恢复撤销的上一个命令。 | --- |
| removeformat | 去掉所选内容的全部格式。 | --- |
| selectall | 选择富文本编辑器中的全部内容。 | --- |
| strikethrough | 切换所选文本的删除线。 | --- |
| subscript | 将当前选择的内容改为下标。 | --- |
| superscript | 当前所选内容转化为上标。 | --- |
| underline | 添加或删除所选文本的下划线。 | --- |
| undo | 撤销上一次执行的动作。 | --- |
| unlink | 删除所选内容的链接信息。 | --- |
| useCSS | 在生成的标记中使用/不使用 CSS。 | 布尔值 |
更多信息请访问 DevEdge。
|
Mozilla 对 XML 及 XML 相关技术提供了强大的支持,如 XSLT 和 Web 服务。也支持 Internet Explorer 的一些非标准扩展,如 XMLHttpRequest。
和标准 HTML 一样,Mozilla 也支持 W3C XML DOM 规范,允许执行 XML 文档大多数方面的操作。和 Internet Explorer XML DOM 的区别多数是由于 Internet Explorer 的非标准行为造成的。可能最常见的一个差别就是处理空白文本节点的方式。生成的 XML 通常在 XML 节点之间带有空白。Internet Explorer 在使用 XMLNode.childNodes[] 的时候不包含这些空白节点。但是在 Mozilla 中,这些节点也包含在数组中。
XML: <?xml version="1.0"?> <myXMLdoc xmlns:myns="http://myfoo.com"> <myns:foo>bar</myns:foo> </myXMLdoc> JavaScript: var myXMLDoc = getXMLDocument().documentElement; alert(myXMLDoc.childNodes.length); |
JavaScript 的第一行加载 XML 文档并通过检索 documentElement 访问根元素(myXMLDoc)。第二行仅仅告诉您子节点的个数。按照 W3C 规范,相连的空格和新行字符合并为一个文本节点。对于 Mozilla,myXMLdoc 节点有三个孩子:包含新行字符和两个空格的文本节点、myns:foo 节点和包含新行字符的另一个文本节点。但是 Internet Explorer 没有遵守这一点,上面的代码将返回“1”,即 myns:foo 节点。因此要遍历子节点和忽略文本节点,必须区分出这样的节点。
如前所述,每个节点都有 nodeType 属性表示节点类型。比如,元素节点类型是 1,而文档节点类型是 9。要丢掉文本节点,必须检查类型 3(文本节点)和 8(注释节点)。
XML:
<?xml version="1.0"?> ?
<myXMLdoc xmlns:myns="http://myfoo.com">
<myns:foo>bar</myns:foo>
</myXMLdoc> ?
JavaScript:
var myXMLDoc = getXMLDocument().documentElement;
var myChildren = myXMLDoc.childNodes;
for (var run = 0; run < myChildren.length; run++){
if ( (myChildren[run].nodeType != 3) &&
(myChildren[run].nodeType != 8) ){
// not a text or comment node
}
}
|
Internet Explorer 有一个非标准特性称为 XML 数据岛,它允许使用非标准 HTML 标签 <xml> 在 HTML 文档中嵌入 XML。Mozilla 不支持 XML 数据岛,将其作为未知的 HTML 标签处理。可以用 XHTML 来实现同样的功能,但是由于 Internet Explorer 对 XHTML 的支持很弱,这通常不是一个好办法。
一种跨浏览器的解决方法是使用 DOM 解析器,它解析包含序列化 XML 文档的字符串并为解析后的 XML 生成文档。Mozilla 使用 DOMParser 类,它接受序列化字符串并用它创建 XML 文档。在 Internet Explorer 可用 ActiveX 实现同样的功能。新增的 Microsoft.XMLDOM 生成 XML 文档,并且有一个 loadXML 方法可以接收字符串。比如下面的代码:
IE XML data island:
..
<xml id="xmldataisland">
<foo>bar</foo>
</xml>
Cross-browser solution:
var xmlString = "<xml
id=\"xmldataisland\"><foo>bar</foo></xml>";
var myDocument;
if (document.implementation.createDocument){
// Mozilla, create a new DOMParser
var parser = new DOMParser();
myDocument = parser.parseFromString(xmlString, "text/xml");
} else if (window.ActiveXObject){
// Internet Explorer, create a new XML document using ActiveX
// and use loadXML as a DOM parser.
myDocument = new ActiveXObject("Microsoft.XMLDOM")
myDocument.async="false";
myDocument.loadXML(xmlString);
}
|
Internet Explorer 允许使用 MSXML 的 XMLHTTP 类发送和检索 XML 文件,该类通过 ActiveX 使用 new ActiveXObject("Msxml2.XMLHTTP") 或者 new ActiveXObject("Microsoft.XMLHTTP") 进行实例化。由于不存在完成这一任务的标准方法,Mozilla 在 JavaScript 全局对象 XMLHttpRequest 中提供了同等的功能。该对象默认生成异步请求。
使用 new XMLHttpRequest() 实例化该对象后,可用 open 方法指定使用的请求类型(GET 或 POST)、加载的文件以及是否异步执行。如果采用异步调用,则为 onload 成员提供一个函数引用,请求完成的时候调用它。
Synchronous request: var myXMLHTTPRequest = new XMLHttpRequest(); myXMLHTTPRequest.open("GET", "data.xml", false); myXMLHTTPRequest.send(null); var myXMLDocument = myXMLHTTPRequest.responseXML; Asynchronous request: var myXMLHTTPRequest; function xmlLoaded () { var myXMLDocument = myXMLHTTPRequest.responseXML; } function loadXML(){ myXMLHTTPRequest = new XMLHttpRequest(); myXMLHTTPRequest.open("GET", "data.xml", true); myXMLHTTPRequest.onload = function xmlLoaded () { var myXMLDocument = myXMLHTTPRequest.responseXML; } function loadXML(){ myXMLHTTPRequest = new XMLHttpRequest(); myXMLHTTPRequest.open("GET", "data.xml", true); myXMLHTTPRequest.onload = xmlLoaded ; myXMLHTTPRequest.send(null); } |
表 7 列出了 Mozilla XMLHttpRequest 提供的方法和属性。
表 7. XMLHttpRequest 方法和属性
| 名称 | 说明 | ||||||||||
| void abort() | 如果请求依然在运行则停止它。 | ||||||||||
| string getAllResponseHeaders() | 用一个字符串返回所有的请求头。 | ||||||||||
| string getResponseHeader(string headerName) | 返回指定头的值。 | ||||||||||
| functionRef onerror | 射之后,请求中发生错误时将调用指定的函数。 | ||||||||||
| functionRef onload | 射之后,请求成功完成并收到响应后将调用引用的函数。用于异步请求。 | ||||||||||
| void open (string HTTP_Method, string URL) void open (string HTTP_Method, string URL, boolean async, string userName, string password) |
初始化对指定 URL 的请求,使用 GET 或 POST HTTP 方法。要发送请求需要在初始化之后调用 send() 方法。如果 async 是 false,则请求是同步的,否则默认使用异步请求。如果需要,可以为给定的 URL 指定用户名和口令。 | ||||||||||
| int readyState | 请求的状态。可能值包括:
| ||||||||||
| string responseText | 包含响应字符串。 | ||||||||||
| DOMDocument responseXML | 包含响应 DOM Document。 | ||||||||||
| void send(variant body) | 发起请求。如果定义了 body,则作为 POST 请求体发送。body 可以是 XML 文档或者序列化 XML 文档的字符串。 | ||||||||||
| void setRequestHeader (string headerName, string headerValue) | 设置 HTTP 请求头以便在 HTTP 请求中使用。必须在 open() 之后调用。 | ||||||||||
| string status | HTTP 请求的状态码。 |
Mozilla 支持 XSL Transformations(XSLT)1.0。还允许 JavaScript 执行 XSLT 转换和对文档运行 XPATH。
Mozilla 要求使用 XML mimetype(text/xml 或 application/xml)发送 XML 和包含样式表的 XSLT 文件。这也是 XSLT 不能在 Mozilla 而能在 Internet Explorer 中运行的主要原因之一。Mozilla 在这方面很严格。
Internet Explorer 5.0 和 5.5 支持 XSLT 工作草案,后者与最终的 1.0 推荐标准存在根本的区别。判断 XSLT 使用哪一个版本的最简单办法就是查看名称空间。1.0 推荐标准的名称空间是 http://www.w3.org/1999/XSL/Transform,而工作草案的名称空间是 http://www.w3.org/TR/WD-xsl。Internet Explorer 6 为保持向后兼容而支持工作草案,但是 Mozilla 不支持工作草案,仅支持最终推荐标准。
如果 XSLT 需要判断浏览器,可以查询 “xsl:vendor” 系统属性。Mozilla 的 XSLT 引擎将报告 “Transformiix”,Internet Explorer 则返回 “Microsoft”。
<xsl:if test="system-property('xsl:vendor') = 'Transformiix'">
<!-- Mozilla specific markup -->
</xsl:if>
<xsl:if test="system-property('xsl:vendor') = 'Microsoft'">
<!-- Internet Explorer specific markup -->
</xsl:if>
|
Mozilla 还为 XSLT 提供了 JavaScript 接口,Web 站点可以在内存中完成 XSLT 转换。可以使用 XSLTProcessor JavaScript 全局对象完成这项工作。XSLTProcessor 需要加载 XML 和 XSLT 文件,因为需要它们的 DOM 文档。XSLTProcessor 导入的 XSLT 文档允许修改 XSLT 参数。XSLTProcessor 可以使用 transformToDocument() 创建标准文档,或者使用 transformToFragment() 生成文档片断,您可轻松地将其添加到其他 DOM 文档中。下面是一个例子:
var xslStylesheet;
var xsltProcessor = new XSLTProcessor();
// load the xslt file, example1.xsl
var myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "example1.xsl", false);
myXMLHTTPRequest.send(null);
// get the XML document and import it
xslStylesheet = myXMLHTTPRequest.responseXML;
xsltProcessor.importStylesheet(xslStylesheet);
// load the xml file, example1.xml
myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "example1.xml", false);
myXMLHTTPRequest.send(null);
var xmlSource = myXMLHTTPRequest.responseXML;
var resultDocument = xsltProcessor.transformToDocument(xmlSource);
|
创建 XSLTProcessor 后使用 XMLHttpRequest 加载 XSLT 文件。XMLHttpRequest 的 responseXML 成员包含 XSLT 的文件的 XML 文档,传递给 importStylesheet。然后再使用 XMLHttpRequest 打开需要转换的源 XML 文档,将该文档传递给 XSLTProcessor 的 transformToDocument 方法。表 8 列出了 XSLTProcessor 的方法。
表 8. XSLTProcessor 方法
| 方法 | 说明 |
| void importStylesheet(Node styleSheet) | 导入 XSLT 样式表。styleSheet 参数是 XSLT 样式表 DOM 文档的根节点。 |
| DocumentFragment transformToFragment(Node source, Document owner) | 应用通过 importStylesheet 方法导入的样式表,并生成 DocumentFragment,通过这种方法来转换节点 source。owner 指定了 DocumentFragment 属于哪个 DOM 文档,以便添加到相应的 DOM 文档中。 |
| Document transformToDocument(Node source) | 应用通过 importStylesheet 导入的样式表,并返回一个独立的 DOM 文档,通过这种方法来转换节点 source。 |
| void setParameter(String namespaceURI, String localName, Variant value) | 设置导入的 XSLT 样式表中的参数。 |
| Variant getParameter(String namespaceURI, String localName) | 获得导入 XSLT 样式表的参数值。 |
| void removeParameter(String namespaceURI, String localName) | 从导入的 XSLT 样式表中删除所有已设置的参数,使用 XSLT 定义的默认值。 |
| void clearParameters() | 删除所有已设置的参数并将其设置为 XSLT 样式表的默认参数。 |
| void reset() | 删除所有的参数和样式表。 |
|
本文介绍了 Web 应用程序开发人员尝试使其应用程序在基于 Mozilla 的浏览器中工作时面临的常见问题。开发 Web 应用程序时,一定要考虑到可能存在的浏览器差异并牢记在心。参考资料 中提供了两篇很好的参考资料,深入探讨了跨浏览器开发问题。根据这些原则开发的 Web 应用程序可以在其他浏览器乃至其他平台上工作。
- 您可以参阅本文在 developerWorks 全球站点上的 英文原文 。
- Dynamic HTML: The Definitive Reference (2nd Edition) 详细讨论了跨浏览器 DHTML 开发的方方面面(O'Reilly & Associates. Inc.,2002 年)。
- JavaScript: The Definitive Guide (4th Edition) 介绍了 JavaScript 的最新版本(1.5),讨论了浏览器的细微差别(O'Reilly & Associates, Inc.,2002 年)。
- Netscape Devedge 讨论了开发人员在使用基于 Mozilla 的浏览器的时候遇到的一些问题。糟糕的是,AOL 去年把它从在线书架上拿了下来,不过已经存档。
- Mozilla.org 上的 Web 开发文档为 Web 开发人员提供了关于 Mozilla 的很好的信息。
- developerWorks Web 开发专区 专门发表各种基于 Web 的解决方案的文章。
- 通过参与 developerWorks blogs 加入 developerWorks 社区。
|
Doron Rosenberg 在加入 IBM Browser Development Center 之前效力于 Netscape。他为 Mozilla 项目工作了五年多。可以通过 doronr@us.ibm.com 联系 Doron。 | ||
表 7 列出了 Mozilla XMLHttpRequest 提供的方法和属性。
表 7. XMLHttpRequest 方法和属性
| 名称 | 说明 | ||||||||||
| void abort() | 如果请求依然在运行则停止它。 | ||||||||||
| string getAllResponseHeaders() | 用一个字符串返回所有的请求头。 | ||||||||||
| string getResponseHeader(string headerName) | 返回指定头的值。 | ||||||||||
| functionRef onerror | 射之后,请求中发生错误时将调用指定的函数。 | ||||||||||
| functionRef onload | 射之后,请求成功完成并收到响应后将调用引用的函数。用于异步请求。 | ||||||||||
| void open (string HTTP_Method, string URL) void open (string HTTP_Method, string URL, boolean async, string userName, string password) |
初始化对指定 URL 的请求,使用 GET 或 POST HTTP 方法。要发送请求需要在初始化之后调用 send() 方法。如果 async 是 false,则请求是同步的,否则默认使用异步请求。如果需要,可以为给定的 URL 指定用户名和口令。 | ||||||||||
| int readyState | 请求的状态。可能值包括:
| ||||||||||
| string responseText | 包含响应字符串。 | ||||||||||
| DOMDocument responseXML | 包含响应 DOM Document。 | ||||||||||
| void send(variant body) | 发起请求。如果定义了 body,则作为 POST 请求体发送。body 可以是 XML 文档或者序列化 XML 文档的字符串。 | ||||||||||
| void setRequestHeader (string headerName, string headerValue) | 设置 HTTP 请求头以便在 HTTP 请求中使用。必须在 open() 之后调用。 | ||||||||||
| string status | HTTP 请求的状态码。 |
Mozilla 支持 XSL Transformations(XSLT)1.0。还允许 JavaScript 执行 XSLT 转换和对文档运行 XPATH。
Mozilla 要求使用 XML mimetype(text/xml 或 application/xml)发送 XML 和包含样式表的 XSLT 文件。这也是 XSLT 不能在 Mozilla 而能在 Internet Explorer 中运行的主要原因之一。Mozilla 在这方面很严格。
Internet Explorer 5.0 和 5.5 支持 XSLT 工作草案,后者与最终的 1.0 推荐标准存在根本的区别。判断 XSLT 使用哪一个版本的最简单办法就是查看名称空间。1.0 推荐标准的名称空间是 http://www.w3.org/1999/XSL/Transform,而工作草案的名称空间是 http://www.w3.org/TR/WD-xsl。Internet Explorer 6 为保持向后兼容而支持工作草案,但是 Mozilla 不支持工作草案,仅支持最终推荐标准。
如果 XSLT 需要判断浏览器,可以查询 “xsl:vendor” 系统属性。Mozilla 的 XSLT 引擎将报告 “Transformiix”,Internet Explorer 则返回 “Microsoft”。
<xsl:if test="system-property('xsl:vendor') = 'Transformiix'">
<!-- Mozilla specific markup -->
</xsl:if>
<xsl:if test="system-property('xsl:vendor') = 'Microsoft'">
<!-- Internet Explorer specific markup -->
</xsl:if>
|
Mozilla 还为 XSLT 提供了 JavaScript 接口,Web 站点可以在内存中完成 XSLT 转换。可以使用 XSLTProcessor JavaScript 全局对象完成这项工作。XSLTProcessor 需要加载 XML 和 XSLT 文件,因为需要它们的 DOM 文档。XSLTProcessor 导入的 XSLT 文档允许修改 XSLT 参数。XSLTProcessor 可以使用 transformToDocument() 创建标准文档,或者使用 transformToFragment() 生成文档片断,您可轻松地将其添加到其他 DOM 文档中。下面是一个例子:
var xslStylesheet;
var xsltProcessor = new XSLTProcessor();
// load the xslt file, example1.xsl
var myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "example1.xsl", false);
myXMLHTTPRequest.send(null);
// get the XML document and import it
xslStylesheet = myXMLHTTPRequest.responseXML;
xsltProcessor.importStylesheet(xslStylesheet);
// load the xml file, example1.xml
myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "example1.xml", false);
myXMLHTTPRequest.send(null);
var xmlSource = myXMLHTTPRequest.responseXML;
var resultDocument = xsltProcessor.transformToDocument(xmlSource);
|
创建 XSLTProcessor 后使用 XMLHttpRequest 加载 XSLT 文件。XMLHttpRequest 的 responseXML 成员包含 XSLT 的文件的 XML 文档,传递给 importStylesheet。然后再使用 XMLHttpRequest 打开需要转换的源 XML 文档,将该文档传递给 XSLTProcessor 的 transformToDocument 方法。表 8 列出了 XSLTProcessor 的方法。
表 8. XSLTProcessor 方法
| 方法 | 说明 |
| void importStylesheet(Node styleSheet) | 导入 XSLT 样式表。styleSheet 参数是 XSLT 样式表 DOM 文档的根节点。 |
| DocumentFragment transformToFragment(Node source, Document owner) | 应用通过 importStylesheet 方法导入的样式表,并生成 DocumentFragment,通过这种方法来转换节点 source。owner 指定了 DocumentFragment 属于哪个 DOM 文档,以便添加到相应的 DOM 文档中。 |
| Document transformToDocument(Node source) | 应用通过 importStylesheet 导入的样式表,并返回一个独立的 DOM 文档,通过这种方法来转换节点 source。 |
| void setParameter(String namespaceURI, String localName, Variant value) | 设置导入的 XSLT 样式表中的参数。 |
| Variant getParameter(String namespaceURI, String localName) | 获得导入 XSLT 样式表的参数值。 |
| void removeParameter(String namespaceURI, String localName) | 从导入的 XSLT 样式表中删除所有已设置的参数,使用 XSLT 定义的默认值。 |
| void clearParameters() | 删除所有已设置的参数并将其设置为 XSLT 样式表的默认参数。 |
| void reset() | 删除所有的参数和样式表。 |
|
本文介绍了 Web 应用程序开发人员尝试使其应用程序在基于 Mozilla 的浏览器中工作时面临的常见问题。开发 Web 应用程序时,一定要考虑到可能存在的浏览器差异并牢记在心。参考资料 中提供了两篇很好的参考资料,深入探讨了跨浏览器开发问题。根据这些原则开发的 Web 应用程序可以在其他浏览器乃至其他平台上工作。
- 您可以参阅本文在 developerWorks 全球站点上的 英文原文 。
- Dynamic HTML: The Definitive Reference (2nd Edition) 详细讨论了跨浏览器 DHTML 开发的方方面面(O'Reilly & Associates. Inc.,2002 年)。
- JavaScript: The Definitive Guide (4th Edition) 介绍了 JavaScript 的最新版本(1.5),讨论了浏览器的细微差别(O'Reilly & Associates, Inc.,2002 年)。
- Netscape Devedge 讨论了开发人员在使用基于 Mozilla 的浏览器的时候遇到的一些问题。糟糕的是,AOL 去年把它从在线书架上拿了下来,不过已经存档。
- Mozilla.org 上的 Web 开发文档为 Web 开发人员提供了关于 Mozilla 的很好的信息。
- developerWorks Web 开发专区 专门发表各种基于 Web 的解决方案的文章。
- 通过参与 developerWorks blogs 加入 developerWorks 社区。
|
Doron Rosenberg 在加入 IBM Browser Development Center 之前效力于 Netscape。他为 Mozilla 项目工作了五年多。可以通过 doronr@us.ibm.com 联系 Doron。 | ||
加载全部内容