go开源Hugo站点渲染之模板词法解析
GitAction 人气:0正文
Deps在准备好NewPathSpec,NewSpec,NewContentSpec,NewSourceSpec后,调用onCreate正式创建HugoSites,并在最后一步,加载模板执行器。
模板执行器只是提前将模板信息转换成了模板执行器,如何使用并没有涉及到。
为了让我们对模板生命周期有更全面的了解,让我们以robots.txt为例,来看看是如何通过模板执行器生成最终文件的。
了然于胸 - newTemplateExec时序图

从时序图中,可以了解到创建执行器,主要分两步。
先创建包含了各种功能函数的executor。 其中的功能函数由两部分组成,一部分来自hugo,像htmlEscape等。 另一部分来自于golang的内置函数,如fmt.Sprint等等。 正是因为有这些功能函数的支持,才得以让模板的action块 - ‘{{}}‘功能如此强大。
执行器创建好后,接下来就要创建模板的handler了。 处理器提供了模板加载、查询等相关的服务,以方便使用。 因为查询服务依赖于加载服务,所以在处理器实例后,紧接着就是加载模板了。 而模板又分两部分,一部分是由hugo提供的默认模板,像robot.txt等。 另一部分就是由用户所提供的layouts文件,有来于主题的,也有来于用户自定义的layout。
加载的是磁盘文件,得到的是解析过后的模板实例。
templ, err := prototype.New(info.name).Parse(info.template)
源码里用的是prototype,而不是直接用的html。 这是因为我们的模板有两种后缀,一种是txt,另一种是html,需要找到相应的原型来对模板进行解析。
不管是什么模板,都是文本,HTML也不例外,也是文本。 HTML模板的源码也应证了这一点 - 直接调用文本模板的方法。 那这种关系是如何用代码实现的呢?
拿到模板字节信息后,用词法分析器对模板字节流进行解析,得到分析好的词义结构。 对于HTML模板而言,为了安全,需要对词义结构进行检查和必要地修改。 因为我们可以从不同渠道,获得不同的主题,这些主题中又包含了很多模板,并且主题中可以嵌套主题,为了保证安全,避免执行恶意代码。 最后就是执行解析好的模板。
为了方便理解,我们来举个例子 - robot.txt模板使用流程:
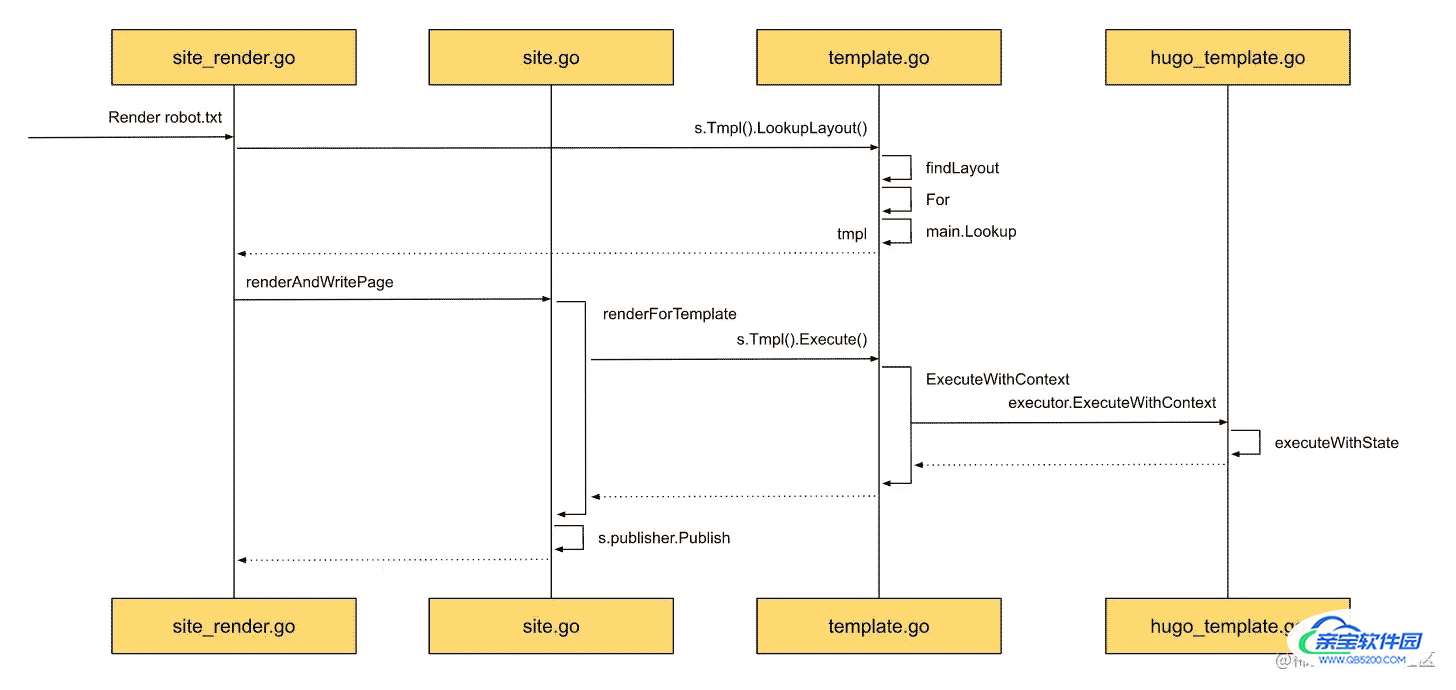
- 查找:通过名字查找,调用templateExec中的handler查询方法LookupLayout进行查询。
- 执行:准备执行模板所需要的信息,调用templateExec中的executor执行方法ExecuteWithContext开始执行。 这里的执行方法实际上也是由text template提供的,前面咱们也提到了,不管是什么类型的模板,都是以text为基础的。
知道了工作流程后,让我们从源码层面,更深入的对Template进行理解。
我们先来看第一步: 模板解析。
词法解析 - parse
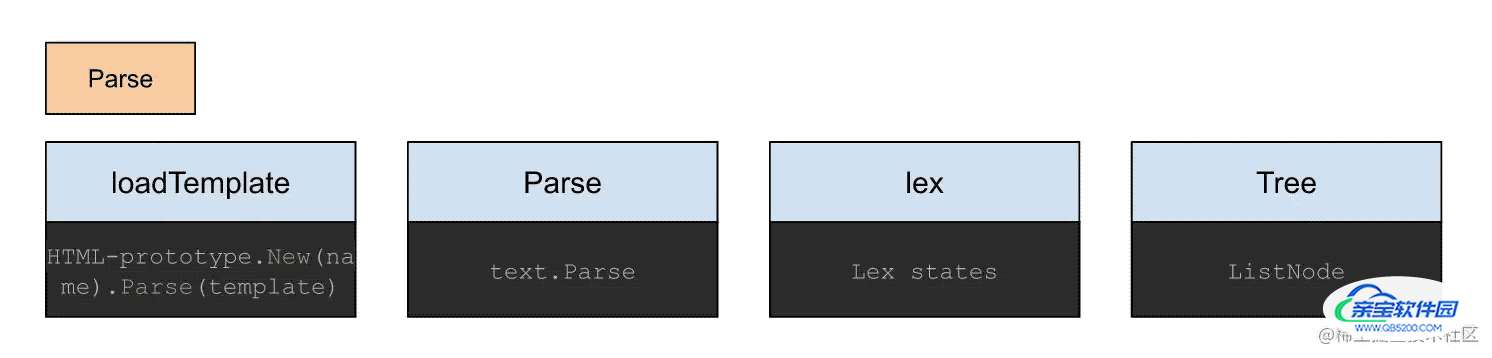
创建Deps的最后一步是loadResources,其中主要指的是Template资源。 在创建templateExec实例的过程中,就需要加载hugo默认和用户创建的模板。 加载模板后,获取了模板的字节信息,要想为我们所有,首先要读懂这些字节,这时,我们就用到了解析Parse,而且是由text模板提供的。 Parse为什么可以读懂这些字符信息呢,她依靠的是内部了词法分析器lex - lexer,分析器需要对action block的语义有充分的理解。 读懂后转换为方便后续操作的数据结构tree,在hugo中实际载体是listNode类型。
我们拿一段模板举个例子:
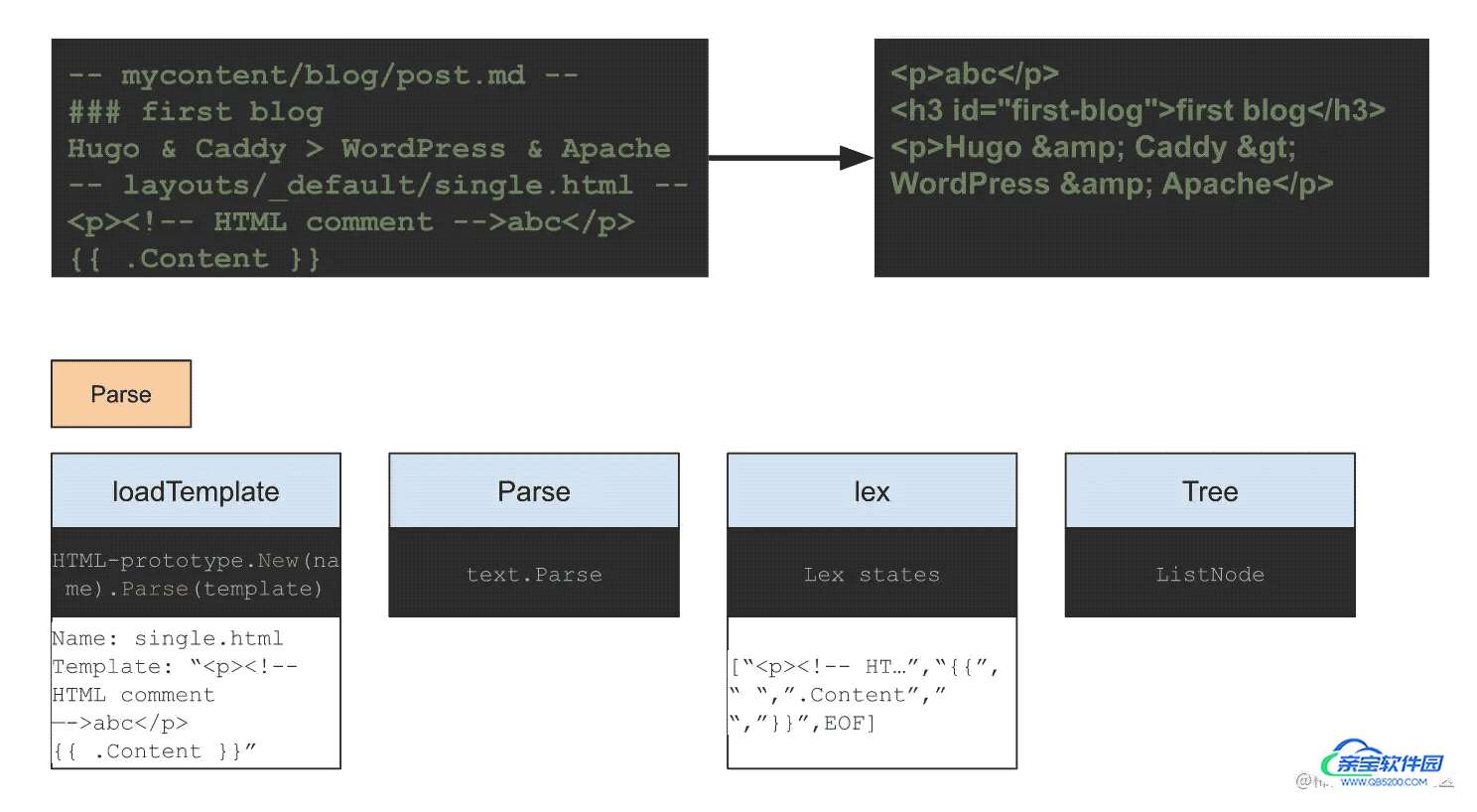
从上例中,我们可以看到,左上方是输入的信息。 包含一篇博客 - post.md,和一个模板 - single.html。 通过转换会得到最右边的输出网页内容。 其中,包含在模板中第一行的信息,剩下的是由博客提供的信息,其中的特殊字符,还被进行了转义。
在左下方第一步中,创建templateExec过程中,读取到了模板single.html。 通过解析,利用词法分析器,会得到如下状态:
[“<p><!-- HT…”, “{{”, “ “, ”.Content”, ” “, ”}}”, EOF]
为了理解其中的工作原理,让我们在下一章节中一起来看一下action block的词法分析器是如何工作的。
加载全部内容