面试官问订单ID是如何生成的?难道不是MySQL自增主键
一灯架构 人气:0一个美女面试官坐到我的对面,发光logo的MacBook也挡不住她那圆润可爱的脸庞。
程序媛本就稀有,美女面试官更是难寻。
这么温柔可爱的面试官,应该不会为难我吧。嗯,应该是的,毕竟我这么帅气,面试可能就是走个过场。美女面试官是不是单身?毕竟程序员都不善交流,因为我也是单身,难道我的姻缘就在此注定。孩子的名字我都想好了。一冰!好名字。
面试官: 小伙子,你低着头笑什么呐。开始面试了,你知道订单ID是怎么生成的吗?
啥?订单ID怎么生成?美女怎么不按套路出牌!HashMap实现原理,我已经倒背如流,你不问。瞎问什么订单ID。
我: 还能咋生成?用数据库主键自增呗。
面试官: 这样不行啊。数据库主键顺序自增,每天有多少订单量被竞争对手看的一清二楚,商业机密都暴露了。
况且单机MySQL只能支持几百量级的并发,我们公司每天千万订单量,hold不住啊。
我: 嗯,那就用用数据库集群,自增ID起始值按机器编号,步长等于机器数量。
比如有两台机器,第一台机器生成的ID是1、3、5、7,第二台机器生成的ID是2、4、6、8。性能不行就加机器,这并发量der一下就上去了。
面试官: 小伙子,你想得倒是挺好。你有没有想过实现百万级的并发,大概就需要2000台机器,你这还只是用来生成订单ID,公司再有钱也经不起这么造。
我: 既然MySQL的并发量不行,我们是不是可以提前从MySQL获取一批自增ID,加载到本地内存中,然后从内存中并发取,这并发性能岂不是杠杠滴。
面试官: 你还挺上道,这种叫号段模式。并发量是上去了,但是自增ID还是不能作为订单ID的。
我: 用Java自带UUID怎么样?
import java.util.UUID;
/**
* @author yideng
* @apiNote UUID示例
*/
public class UUIDTest {
public static void main(String[] args) {
String orderId = UUID.randomUUID().toString().replace("-", "");
System.out.println(orderId);
}
}输出结果:
58e93ecab9c64295b15f7f4661edcbc1
面试官: 也不行。32位字符串会占用更大的空间,无序的字符串作数据库主键,每次插入数据库的时候,MySQL为了维护B+树结构,需要频繁调整节点顺序,影响性能。况且字符串太长,也没有任何业务含义,pass。
小伙子,你可能是没参与过电商系统,我先跟说一下生成订单ID要满足哪些条件:
全局唯一:如果订单ID重复了,肯定要完蛋。
高性能:要做到高并发、低延迟。生成订单ID都成为瓶颈了,那还得了。
高可用:至少要做到4个9,别动不动就宕机了。
易用性:如果为了满足上述要求,搞了几百台服务器,复杂且难以维护,也不行。
数值且有序递增:数值占用的空间更小,有序递增能保证插入MySQL的时候更高性能。
嵌入业务含义:如果订单ID里面能嵌入业务含义,就能通过订单ID知道是哪个业务线生成的,便于排查问题。
我擦,生成一个小小的订单ID,搞出这么多规则,还能玩下去吗?难道今天的面试要跪,怎么可能。一灯的文章我一直订阅,这个还能难得住我,陪美女程序员玩玩还当真了。
我: 我听说圈内有一种流传已久的分布式、高性能、高可用的订单ID生成算法—雪花算法,完全能满足你的上述要求。雪花算法生成ID是Long类型,长度64位。
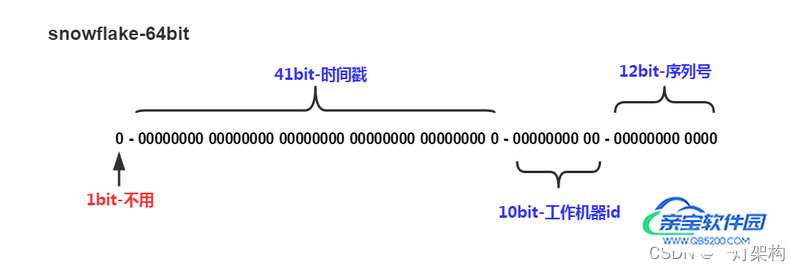
第 1 位: 符号位,暂时不用。
第 2~42 位: 共41位,时间戳,单位是毫秒,可以支撑大约69年
第 43~52 位: 共10位,机器ID,最多可容纳1024台机器
第 53~64 位: 共12位,序列号,是自增值,表示同一毫秒内产生的ID,单台机器每毫秒最多可生成4096个订单ID
代码实现:
/**
* @author 一灯架构
* @apiNote 雪花算法
**/
public class SnowFlake {
/**
* 起始时间戳,从2021-12-01开始生成
*/
private final static long START_STAMP = 1638288000000L;
/**
* 序列号占用的位数 12
*/
private final static long SEQUENCE_BIT = 12;
/**
* 机器标识占用的位数
*/
private final static long MACHINE_BIT = 10;
/**
* 机器数量最大值
*/
private final static long MAX_MACHINE_NUM = ~(-1L << MACHINE_BIT);
/**
* 序列号最大值
*/
private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long TIMESTAMP_LEFT = SEQUENCE_BIT + MACHINE_BIT;
/**
* 机器标识
*/
private long machineId;
/**
* 序列号
*/
private long sequence = 0L;
/**
* 上一次时间戳
*/
private long lastStamp = -1L;
/**
* 构造方法
* @param machineId 机器ID
*/
public SnowFlake(long machineId) {
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new RuntimeException("机器超过最大数量");
}
this.machineId = machineId;
}
/**
* 产生下一个ID
*/
public synchronized long nextId() {
long currStamp = getNewStamp();
if (currStamp < lastStamp) {
throw new RuntimeException("时钟后移,拒绝生成ID!");
}
if (currStamp == lastStamp) {
// 相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
// 同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStamp = getNextMill();
}
} else {
// 不同毫秒内,序列号置为0
sequence = 0L;
}
lastStamp = currStamp;
return (currStamp - START_STAMP) << TIMESTAMP_LEFT // 时间戳部分
| machineId << MACHINE_LEFT // 机器标识部分
| sequence; // 序列号部分
}
private long getNextMill() {
long mill = getNewStamp();
while (mill <= lastStamp) {
mill = getNewStamp();
}
return mill;
}
private long getNewStamp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
// 订单ID生成测试,机器ID指定第0台
SnowFlake snowFlake = new SnowFlake(0);
System.out.println(snowFlake.nextId());
}
}
输出结果:
6836348333850624
接入非常简单,不需要搭建服务集群,。代码逻辑非常简单,,同一毫秒内,订单ID的序列号自增。同步锁只作用于本机,机器之间互不影响,每毫秒可以生成四百万个订单ID,非常强悍。
生成规则不是固定的,可以根据自身的业务需求调整。如果你不需要那么大的并发量,可以把机器标识位拆出一部分,当作业务标识位,标识是哪个业务线生成的订单ID。
面试官: 小伙子,有点东西,深藏不漏啊。再问个更难的问题,你觉得雪花算法还有改进的空间吗?
你真是打破砂锅问到底,不把我问趴下不结束。幸亏来之前我瞥了一眼一灯的文章。
我: 有的,雪花算法严重依赖系统时钟。如果时钟回拨,就会生成重复ID。
面试官: 有什么解决办法吗?
我: 有问题就会有答案。比如美团的Leaf(美团自研一种分布式ID生成系统),为了解决时钟回拨,引入了zookeeper,原理也很简单,就是比较当前系统时间跟生成节点的时间。

有的对并发要求更高的系统,比如双十一秒杀,每毫秒4百万并发还不能满足要求,就可以使用雪花算法和号段模式相结合,比如百度的UidGenerator、滴滴的TinyId。想想也是,号段模式的预先生成ID肯定是高性能分布式订单ID的最终解决方案。
面试官: 小伙子,我看你简历上写着已经离职了。明天就来上班吧,薪资double,就这样了。
总结
加载全部内容