Python中jieba库的介绍与使用
Algorithm-007 人气:0前言:
jieba是优秀的中文分词第三方库,由于中文文本之间每个汉字都是连续书写的,我们需要通过特定的手段来获得其中的每个词组,这种手段叫做分词,我们可以通过jieba库来完成这个过程。
目录:
一、jieba库基本介绍
(1)jieba库概述
① jieba是优秀的中文分词第三方库
②中文文本需要通过分词获得单个的词语③ jieba是优秀的中文分词第三方库,需要额外安装
④jieba库提供三种分词模式,最简单只需掌握一个函数
(2)jieba分词的原理
①分词依靠中文词库
② 利用一个中文词库,确定汉字之间的关联概率
③ 汉字间概率大的组成词组,形成分词结果
④ 除了分词,用户还可以添加自定义的词组
二、jieba库使用说明
(1)jieba分词的三种模式
精确模式、全模式、搜索引擎模式
① jieba.cut(s) 精确模式:把文本精确的切分开,不存在冗余单词:
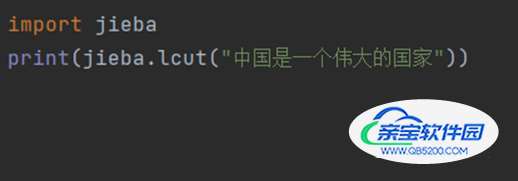

② jieba.lcut(s,cut_all=True) 全模式:把文本中所有可能的词语都扫描出来,有冗余:


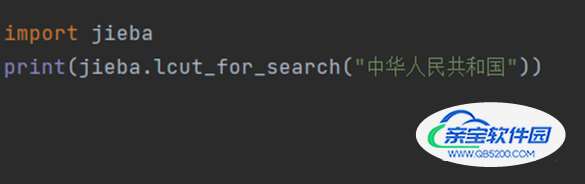
③jieba.lcut_for_search(s) 搜索引擎模式:在精确模式基础上,对长词再次切分:

三:jieba库的安装
因为 jieba 是一个第三方库,所有需要我们在本地进行安装:
ⅠIDLE中jieba库的安装:
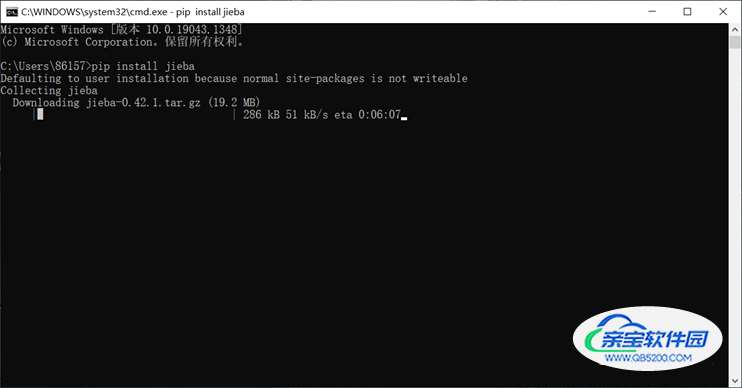
Windows 下使用命令安装:在联网状态下,在命令行下输入 pip
install jieba 进行安装,安装完成后会提示安装成功。具体过程如图:
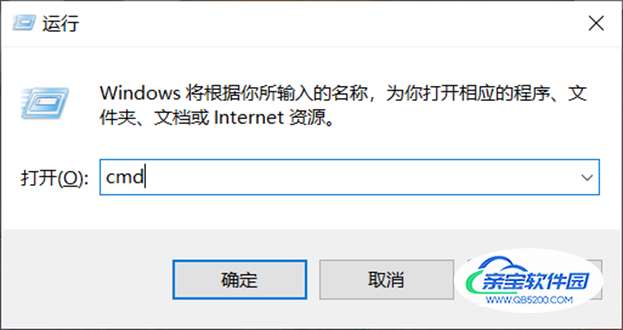
① Win + r 打开运行框并输入cmd打开指令框:
②在指令框输入“pip install jieba”并按下回车等待下载:
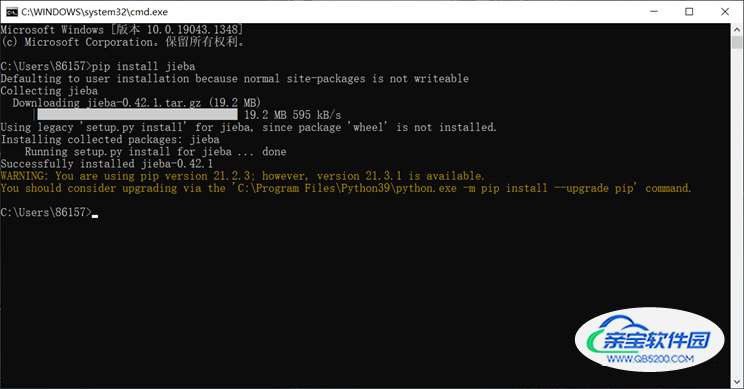
③ 当出现“Successfully instll”,则表示安装成功!
Ⅱ Pycharm中jieba库的安装:
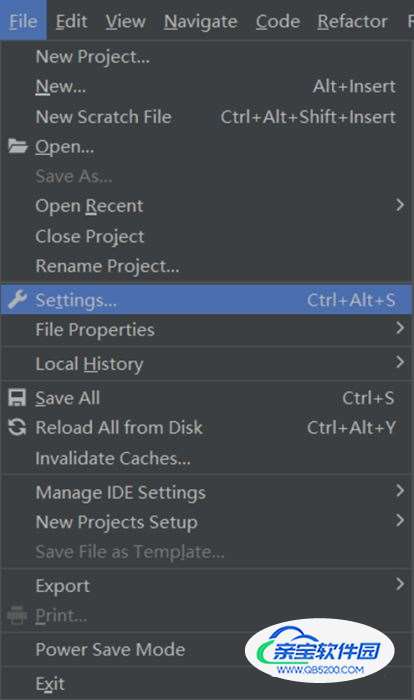
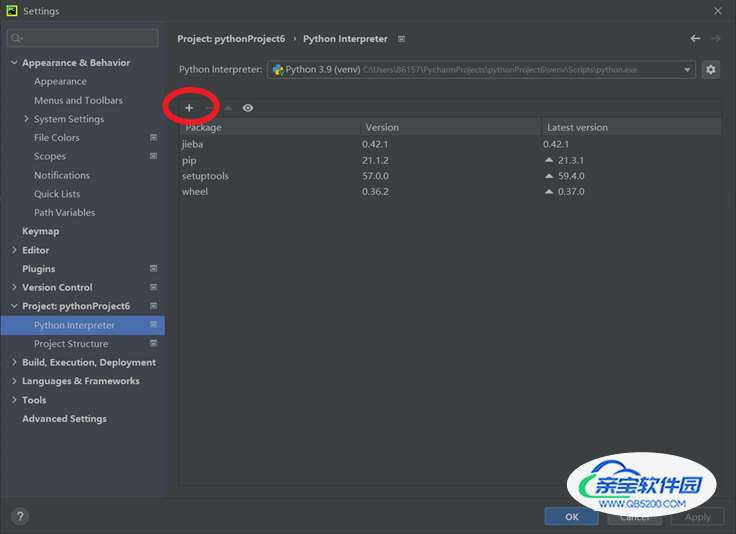
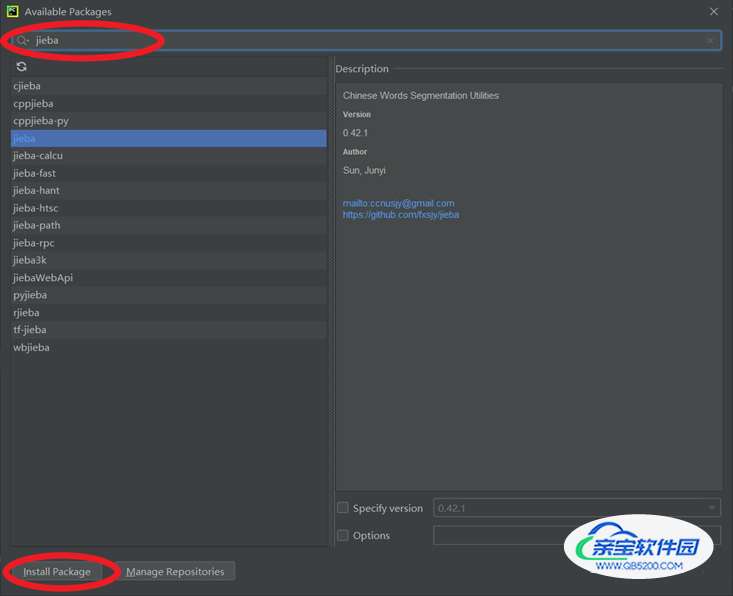
打开 settings,搜索 Project Interpreter,在右边的窗口选择 + 号,点击后在搜索框搜索 jieba,点击安装即可。具体过程如图:
① 点击左上角Files中的Settings:
② [endif]找到“Project”中的“python interpreter”,并点击其中的“+”:
③在搜索栏中搜索“jieba”,并点击左下角Install Package:
④ 当出现“Successfully instll
jieba”,则表示jieba库安装成功!
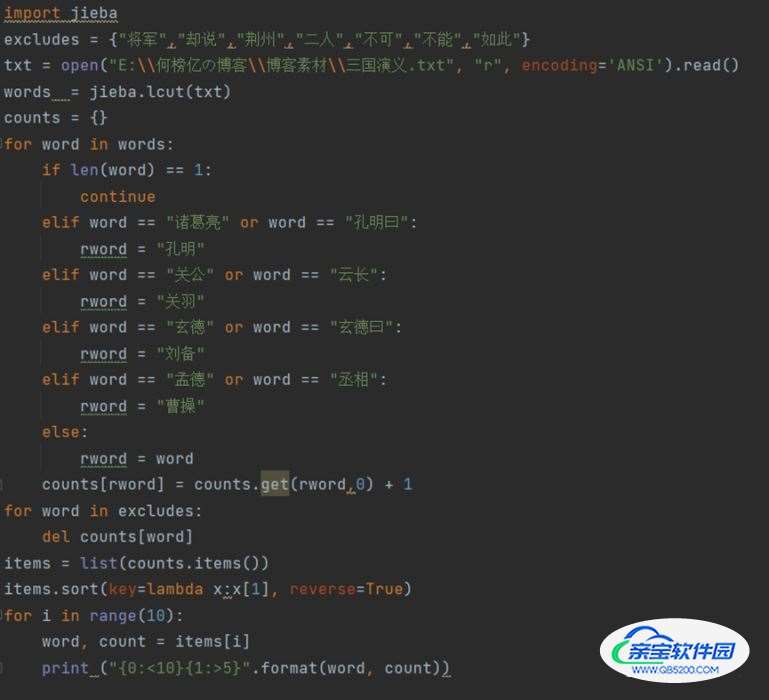
四:实例-文本词频统计
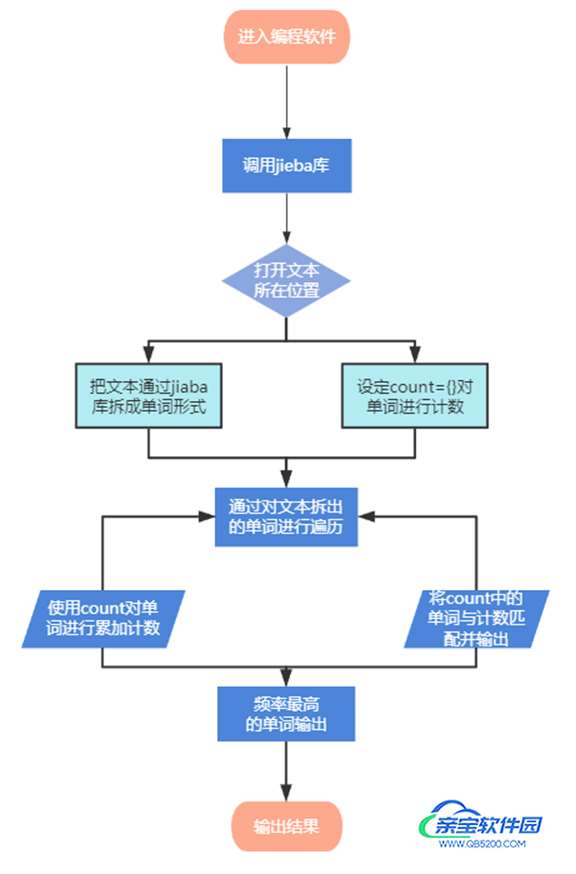
Jieba库最强大的功能之一就是对文章出现的词汇进行计数统计,即计算词频,对于一篇文章或者一部著作,我们可以通过以下步骤对出现的单词进行统计:
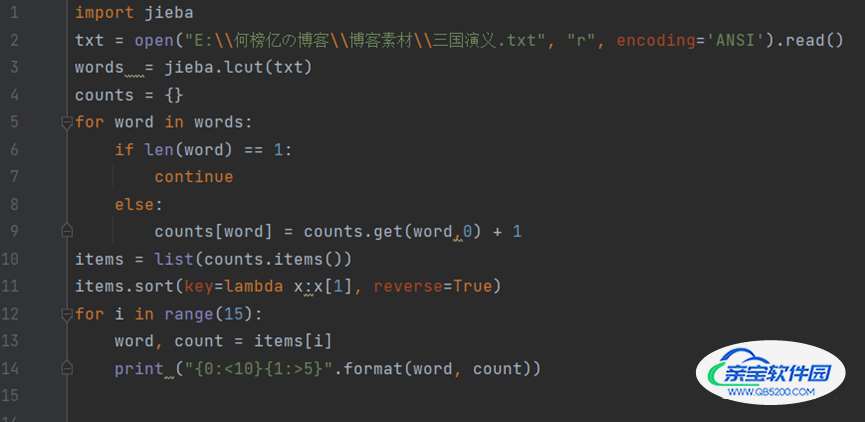
源代码:
注:
① encoding=’ANSI’:将打开的文本格式设为ANSI形式
② read(size):方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,它范围为字符串对象。
③items
= list(counts.items):将counts中的元素存入items表格中。
④ key = lambda x:x[1]:等价于 def func(x):
return x[1]
⑤ reverse = True:列表反转排序,不写reverse = True 就是列表升序排列,括号里面加上reverse =True 就是降序排列!
⑥ {0:<10}{1:>5}:<表示左对齐,>表示右对齐,数字表示宽度,<10表示左对齐,并占10个位置,>5表示右对齐,占5个位置。
运行结果:
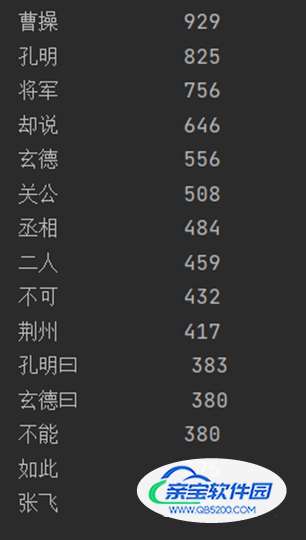
如上运行结果有两个不足之处,一是词汇中出现了“却说”、“丞相”、“二人”等人名以外的单词,我们需要把这些单词去除;二是“孔明”与“孔明说”、“曹操”与“丞相”等的是同一人,我们需要把它们合并同类项,将代码进行优化后,我们得到:
运行结果:
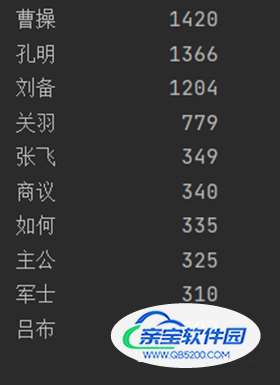
相对于第一个程序,这个程序更为严谨与完整,已经得到了大致得到所需结果,但它还没有完全解决排除非人名这一问题,所以在该基础之上继续使用排除人名的方法去完善这一程序……
总结:
使用jieba库对一段文本进行词频的统计是一件非常有意思的事,我们只需要使用这第三方库,就可以在不阅读文本的情况下,得到该文本的高频率词汇。但jieba库的作用远远不止于此,它更多的作用等着我们去挖掘。总的来说,jieba库是一个优秀的中文分词第三方库,它在我们的程序中正大放光芒!
加载全部内容