文件预览PDF.js使用技巧示例总结
Jiaynn 人气:0Pdf.js有两种使用方式
在这次的项目中用到了pdf文件的预览功能,选择了pdf.js去预览pdf文件,实现滑动展示所有的pdf
- 通过 npm 下载
- 直接下载 pdf.js 库,当作静态资源使用
把pdf.js当作静态资源使用
最开始我采取的是把pdf.js当作静态资源使用,使用方法如下:
- 官网下载后解压项目得到 pdf.js
- 放到项目文件夹 /public/static/ 下
- 直接将 web/viewer.html 后面的 file 跟上自己自己的 pdf 文件即可
contentUrl.current = content.includes("pdf")
? `/static/pdfjs-3.1.81-dist/web/viewer.html?file=${content}`
: content;
<iframe src={contentUrl.current}></iframe>
使用静态资源时,如果需要更改他的默认样式需要自己手动改源代码
同时可能我们遇到了跨域问题,我们需要在源码中的判断跨域代码注释掉

使用静态资源的问题是在移动端不能手势放大缩小,需要我们自己编写代码然后修改源代码强制放大缩小
这种方式不细讲,网上很多使用方式都是通过使用静态资源,可以自行去查看,这里只讲一个大概。
npm下载,通过import使用
方法如下:
npm install pdfjs-dist
const contentRef = useRef<HTMLDivElement | null>(null);
useEffect(() => {
//content就是 iframe 请求的url,这里是因为我的项目里面需要判断下他url是否涵盖了pdf
//如果涵盖了才使用pdf.js
content.includes('pdf')
//重点是 loadPdf() 这个函数,就是我们使用 pdf.js 的函数
? loadPdf(contentRef.current, content, loadingRef.current)
: null;
}, [content]);
<div className="content-wrapper" ref={contentRef}>
{content.includes('pdf') ? null : <iframe src={content}></iframe>}
<div className="loading" ref={loadingRef} style={{ display: 'none' }}></div>
</div>
import * as pdf from 'pdfjs-dist';
import pdfWorker from 'pdfjs-dist/build/pdf.worker.js?url';
pdf.GlobalWorkerOptions.workerSrc = pdfWorker;
/**
* @desc 使用pdf.js加载pdf
* @param contentDom
* @param url
*/
export const loadPdf = async (
contentDom: HTMLDivElement | null,
url: string,
loadingDom: HTMLDivElement | null
) => {
//得到请求的 pdf 文件
const loadingTask = pdf.getDocument({
url: url,
disableRange: true
});
//loading效果,下载pdf过程中展示loading
loadingTask.onProgress = () => {
if (loadingDom) {
loadingDom.style.display = 'block';
}
};
loadingTask.promise.then((pdfDoc) => {
//下载完成时,loading消失
if (loadingDom) {
loadingDom.style.display = 'none';
}
//得到 pdf 总页数
const totalPages = pdfDoc.numPages;
for (let i = 1; i <= totalPages; i++) {
pdfDoc.getPage(i).then((page) => {
const canvas = document.createElement('canvas');
canvas.setAttribute('id', `the-canvas${i}`);
const ctx = canvas.getContext('2d') as CanvasRenderingContext2D;
const dpr = window.devicePixelRatio || 1;
const scaledViewport = page.getViewport({ scale: 1 });
canvas.height = Math.floor(scaledViewport.height * dpr);
canvas.width = Math.floor(scaledViewport.width * dpr);
canvas.style.width = document.body.clientWidth + 'px';
canvas.style.height =
document.body.clientWidth / (canvas.width / canvas.height) + 'px';
const transform = dpr !== 1 ? [dpr, 0, 0, dpr, 0, 0] : undefined;
const renderContext = {
canvasContext: ctx,
viewport: scaledViewport,
transform: transform
};
page.render(renderContext);
contentDom?.appendChild(canvas);
});
}
});
};
上面的代码展示了我使用pdf.js的整个使用过程,主要思路是先获取到pdf文件,然后得到总页数后通过生成响应页数的canvas,然后再渲染到页面上展示pdf
这里需要注意的是scaledViewport.height得到的是你的pdf文件本身的宽高,我们需要通过这个宽高进行适配我们自己的屏幕,同时需要保证他的清晰度,所以我们需要保证canvas两个宽高的尺寸是一致的。
canvas 本身有两个宽高,标签的 width 和 height 是绘画区域实际宽度和高度,绘制的图形都是在这个上面。而 style 的 width 和 height 是 canvas 在浏览器中被渲染的高度和宽度,如果 canvas 标签中没有定义 width 和 height 时,默认会给宽 300 高 150,所以就出现了拉伸的效果,不想用默认的宽高的话,尽量在标签中写上宽高的属性。
所以,如上面的代码一样,宽度就是整个屏幕的宽度,但是每个pdf页面的高度,需要保证和canvas.width/canvas.height的尺寸一致
canvas.style.height = document.body.clientWidth / (canvas.width / canvas.height) + 'px';
这样就能展示pdf文件了
这里又存在一个问题,文件过大,而pdf.js的渲染原理是需要将整个pdf文件下载下来后,再进行展示,这就导致了白屏的时间过长,用户体验感不好,然后我们就想到了分片下载
我们需要在 getDocument()这个api上增加一些配置
const loadingTask = pdf.getDocument({
url: url,
//disableRange: true,
rangeChunkSize: 65536 * 16,
disableAutoFetch: true
});
分片下载还有一个很重要的点,就是需要判断下你访问的pdf是否支持分片下载,使用了分片下载的请求是后续会通过你的分片大小发送206请求
HTTP206状态码代表的意思是 请求已成功处理,但仅返回了部分内容,即 HTTP 206 Partial Content 响应状态。
HTTP 206 (Http Status Code 206) 状态是HTTP协议的一种响应码,是我们请求访问网站时,服务器端返回的2xx 成功状态系列响应码之一。
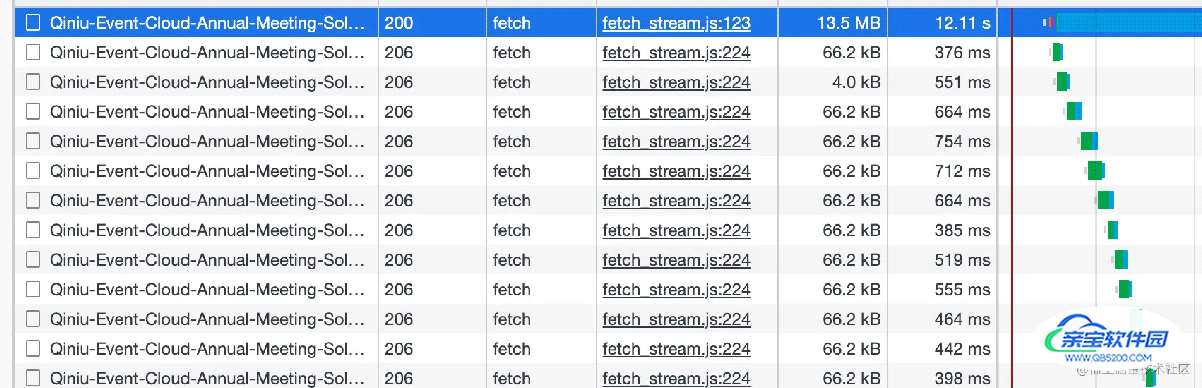
查看是否支持分片下载
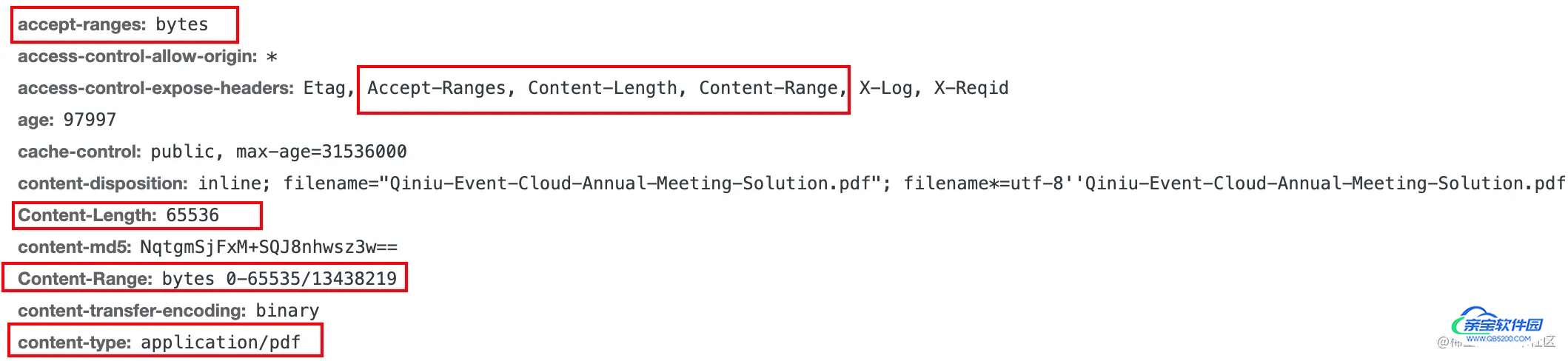
需要有这个响应头才是支持分片下载 accept-range:bytes
但后面我们遇到一个问题:我们的pdf链接存在这个响应头,但却不支持分片下载,后面通过对比发现是这个响应头 access-control-expose-headers 的问题
响应标头 Access-Control-Expose-Headers 允许服务器指示哪些响应标头应该对浏览器中运行的脚本可用,以响应跨源请求。
我们最开始这个响应头里面的内容没有Access-Control-Expose-Headers,意味着就算存在 accept-range 这个响应头,浏览器也不可用,所以在后面我们添加上这个响应头的内容后就可以使用分片下载了。
API(记录一下,防止忘记)
这个api来源于掘金的某位大佬
| 属性 | 说明 | 类型 | 默认值 |
|---|---|---|---|
| 属性 | 说明 | 类型 | 默认值 |
| worker | 用于加载和解析 PDF 数据的工作器 | PDFWorker | - |
| withCredentials | 指示是否应使用 cookie 或授权标头等凭据发出跨站点访问控制请求。 | Boolean | false |
| verbosity | 控制日志记录级别;应该使用 VerbosityLevel 中的常量 | Number | - |
| useWorkerFetch | 在读取 CMap 和标准字体文件时启用在工作线程中使用 Fetch API。当为“true”时,会忽略“CMapReaderFactory”和“StandardFontDataFactory”选项。 Web 环境中的默认值为 true,Node.js 中的默认值为 false | Boolean | - |
| useSystemFonts | 是否使用系统字体 | Boolean | false |
| url | PDF的url地址 | String | URL |
| stopAtErrors | 拒绝某些方法,例如getOperatorList、getTextContent 和 RenderTask,当相关的 PDF 数据无法成功解析时,而不是尝试恢复任何可能的数据 | Boolean | false |
| standardFontDataUrl | 标准字体文件所在的地址。包括尾部斜杠 | String | - |
| StandardFontDataFactory | 读取标准字体文件时将使用的工厂。提供自定义工厂对于没有 Fetch API 或 XMLHttpRequest 支持的环境很有用,例如 Node.js | Object | {DOMStandardFontDataFactory} |
| rangeChunkSize | 指定每个范围请求获取的最大字节数 | Number | DEFAULT_RANGE_CHUNK_SIZE |
| range | 允许使用自定义范围 | PDFDataRangeTransport | - |
| pdfBug | 启用用于调试 PDF.js 的特殊钩子(请参阅web / debugger.js) | Object | false |
| password | 用于解密受密码保护的 PDF | String | - |
| ownerDocument | 指定一个显式的文档上下文来创建元素并将资源(例如字体)加载到其中 | HTMLDocument | - |
| maxImageSize | 总像素中允许的最大图像大小,即宽 * 高。不会呈现高于此值的图像。使用 -1 表示没有限制,这也是默认值 | Number | - |
| length | PDF 文件长度。它用于进度报告和范围请求操作 | Number | - |
| isEvalSupported | 确定我们是否可以将字符串评估为 JavaScript。主要用于提高字体渲染的性能,以及解析 PDF 函数时 | Boolean | true |
| initialData | 带有第一部分或全部 pdf 数据的类型化数组。由扩展使用,因为在切换到范围请求之前已经加载了一些数据。 | TypedArray | - |
| httpHeaders | 基本身份验证请求头 | Object | - |
| fontExtraProperties | 从工作线程导出解析的字体数据时,包括在渲染 PDF 文档期间未使用的其他属性,这对于调试目的(和向后兼容性)可能很有用,但请注意,它会导致内存使用量增加 | Boolean | false |
| enableXfa | 渲染 Xfa 表格 | Boolean | false |
| docBaseUrl | 文档的基本 URL,在尝试恢复注释和大纲项的有效绝对 URL 时使用,(错误地)仅指定了相对 URL | string | - |
| disableStream | 禁用 PDF 文件数据的流式传输。默认情况下,PDF.js 尝试分块加载 PDF 文件 | Object | false |
| disableRange | 禁用 PDF 文件的范围请求加载。启用后,如果服务器支持部分内容请求,则 PDF 将分块获取 | Boolean | false |
| disableFontFace | 默认情况下,字体会转换为 OpenType 字体并通过字体加载 API 或@font-face 规则加载。如果禁用,字体将使用内置字体渲染器渲染,该渲染器使用原始路径命令构建字形。 | Boolean | - |
| disableAutoFetch | 禁用预取 PDF 文件数据。启用范围请求后,即使不需要显示当前页面,PDF.js 也会自动继续获取更多数据 | Object | false |
| data | 二进制 PDF 数据。使用类型化数组 (Uint8Array) 来提高内存使用率。如果 PDF 数据是 BASE64 编码的,请先使用 atob() 将其转换为二进制字符串。 | TypedArray、Array、String | - |
| cMapUrl | 预定义 Adobe CMap 所在的 URL。包括尾部斜杠 | String | - |
| CMapReaderFactory | 自定义工厂对于没有 Fetch API 或 XMLHttpRequest 支持的环境很有用,例如 Node.js | Object | {DOMCMapReaderFactory} |
| cMapPacked | 指定 Adobe CMap 是否是二进制打包 | Boolean | - |
最后,发现可能是这个库的问题还是什么,目前不太清楚,他总是从13M以上才开始快速渲染,而我们当时的文件大小差不多也是13M,所以采用了分片下载后,还是存在一段比较长的白屏时间,所以最后还是选用了将pdf转成图片再显示的形式。
加载全部内容