源码剖析Golang中map扩容底层的实现
劲仔Go 人气:0前言
之前的文章详细介绍过Go切片和map的基本使用,以及切片的扩容机制。本文针对map的扩容,会从源码的角度全面的剖析一下map扩容的底层实现。
map底层结构
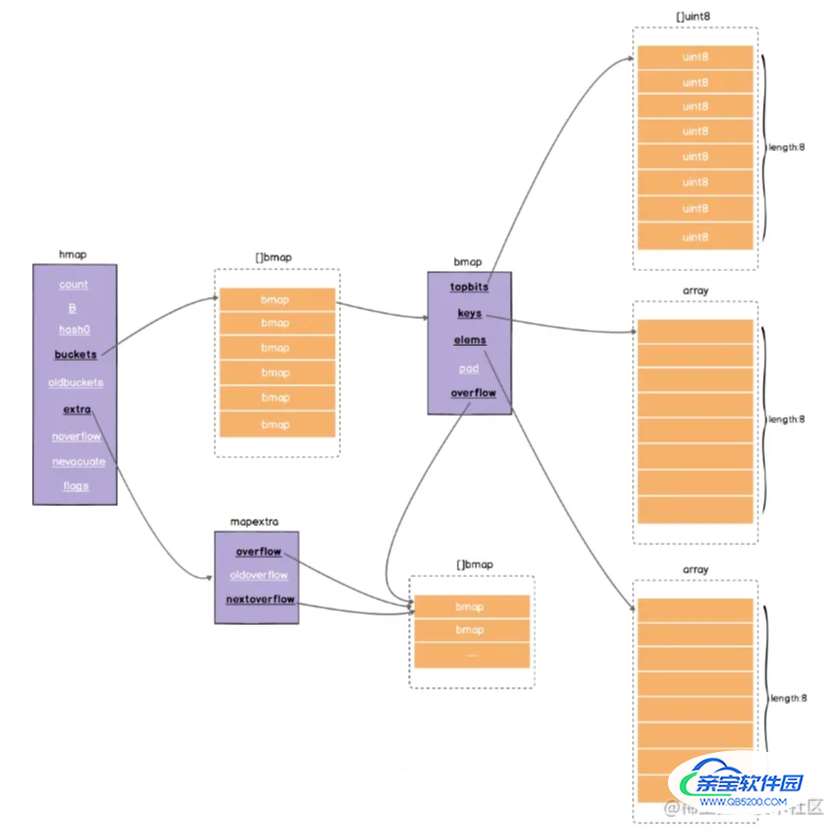
主要包含两个核心结构体hmap和bmap
数据会先存储在正常桶hmap.buckets指向的bmap数组中,一个bmap只能存储8组键值对数据,超过则会将数据存储到溢出桶hmap.extra.overflow指向的bmap数组中
那么,当溢出桶也存储不下了,会怎么办呢,数据得存储到哪去呢?答案,肯定是扩容,那么扩容怎么实现的呢?接着往下看
扩容时机
在向 map 插入新 key 的时候,会进行条件检测,符合下面这 2 个条件,就会触发扩容
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
// growing reports whether h is growing. The growth may be to the same size or bigger.
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}条件1:超过负载
map元素个数 > 6.5 * 桶个数
// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}其中
- bucketCnt = 8,一个桶可以装的最大元素个数
- loadFactor = 6.5,负载因子,平均每个桶的元素个数
- bucketShift(B): 桶的个数
条件2:溢出桶太多
当桶总数 < 2 ^ 15 时,如果溢出桶总数 >= 桶总数,则认为溢出桶过多。
当桶总数 >= 2 ^ 15 时,直接与 2 ^ 15 比较,当溢出桶总数 >= 2 ^ 15 时,即认为溢出桶太多了。
// tooManyOverflowBuckets reports whether noverflow buckets is too many for a map with 1<<B buckets.
// Note that most of these overflow buckets must be in sparse use;
// if use was dense, then we'd have already triggered regular map growth.
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
// If the threshold is too low, we do extraneous work.
// If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory.
// "too many" means (approximately) as many overflow buckets as regular buckets.
// See incrnoverflow for more details.
if B > 15 {
B = 15
}
// The compiler doesn't see here that B < 16; mask B to generate shorter shift code.
return noverflow >= uint16(1)<<(B&15)
}对于条件2,其实算是对条件1的补充。因为在负载因子比较小的情况下,有可能 map 的查找和插入效率也很低,而第 1 点识别不出来这种情况。
表面现象就是负载因子比较小,即 map 里元素总数少,但是桶数量多(真实分配的桶数量多,包括大量的溢出桶)。比如不断的增删,这样会造成overflow的bucket数量增多,但负载因子又不高,达不到第 1 点的临界值,就不能触发扩容来缓解这种情况。这样会造成桶的使用率不高,值存储得比较稀疏,查找插入效率会变得非常低,因此有了第 2 扩容条件。
扩容方式
双倍扩容
针对条件1,新建一个buckets数组,新的buckets大小是原来的2倍,然后旧buckets数据搬迁到新的buckets,该方法我们称之为双倍扩容
等量扩容
针对条件2,并不扩大容量,buckets数量维持不变,重新做一遍类似双倍扩容的搬迁动作,把松散的键值对重新排列一次,使得同一个 bucket 中的 key 排列地更紧密,节省空间,提高 bucket 利用率,进而保证更快的存取,该方法我们称之为等量扩容
扩容函数
上面说的 hashGrow() 函数实际上并没有真正地“搬迁”,它只是分配好了新的 buckets,并将老的 buckets 挂到了 oldbuckets 字段上。
真正搬迁 buckets 的动作在 growWork() 函数中,而调用 growWork() 函数的动作是在 mapassign 和 mapdelete 函数中。也就是插入或修改、删除 key 的时候,都会尝试进行搬迁 buckets 的工作。先检查 oldbuckets 是否搬迁完毕,具体来说就是检查 oldbuckets 是否为 nil
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// commit the grow (atomic wrt gc)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}由于 map 扩容需要将原有的 key/value 重新搬迁到新的内存地址,如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,因此 Go map 的扩容采取了一种称为“渐进式”的方式,原有的 key 并不会一次性搬迁完毕,每次最多只会搬迁 2 个 bucket。
func growWork(t *maptype, h *hmap, bucket uintptr) {
// make sure we evacuate the oldbucket corresponding
// to the bucket we're about to use
evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}总结
要想掌握Go map扩容的底层实现,必须先掌握map的底层结构设计。基于底层结构,再从底层实现的源码,一步步分析。
加载全部内容