Python分析特征数据类别与预处理方法速学
fanstuck 人气:0前言
当我们开始准备数据建模、构建机器学习模型的时候,第一时间考虑的不应该是就考虑到选择模型的种类和方法。而是首先拿到特征数据和标签数据进行研究,挖掘特征数据包含的信息以及思考如何更好的处理这些特征数据。那么数据类型本身代表的含义就需要我们进行思考,究竟是定量计算还是进行定类分析更好呢?这就是这篇文章将要详解的一个问题。
一、特征类型判别
特征类型判断以及处理是前期特征工程重要的一环,也是决定特征质量好坏和权衡信息丢失最重要的一环。其中涉及到的数据有数值类型的数据,例如:年龄、体重、身高这类特征数据。也有字符类型特征数据,例如性别、社会阶层、血型、国家归属等数据。
按照数据存储的数据格式可以归纳为两类:
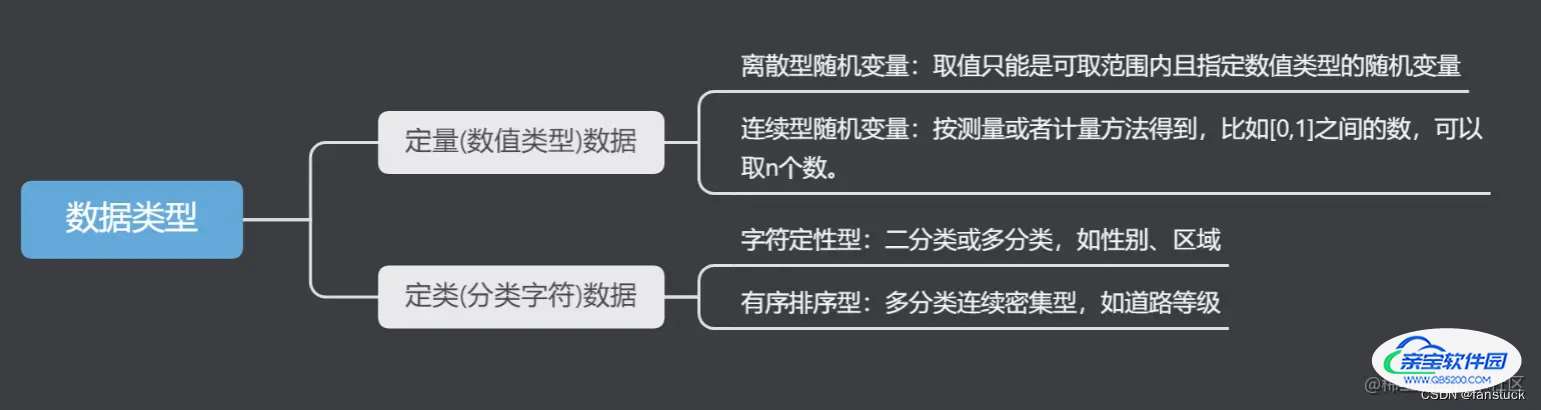
按照特征数据含义又可分为:
- 离散型随机变量:取值只能是可取范围内的指定数值类型的随机变量,比如年龄、车流量此类数据。
- 连续随机变量:按照测量或者计算方法得到,在某个范围内连取n个值,此类数据可化为定类数据。
- 二分类数据:此类数据仅只有两类:例如是与否、成功与失败。
- 多分类数据:此类数据有多类:例如天气出太阳、下雨、阴天。
- 周期型数据:此类数据存在一个周期循环:例如周数月数。
二、定量数据特征处理
拿到获取的原始特征,必须对每一特征分别进行归一化,比如,特征A的取值范围是[-1000,1000],特征B的取值范围是[-1,1].如果使用logistic回归,w1x1+w2x2,因为x1的取值太大了,所以x2基本起不了作用。所以,必须进行特征的归一化,每个特征都单独进行归一化。
关于处理定量数据我已经在:数据预处理归一化详细解释这篇文章里面讲述的很详细了,这里进行前后关联,共有min-max标准化、Z-score标准化、Sigmoid函数标准化三种方法:
根据特征数据含义类型来选择处理方法:
- 离散型随机变量处理方法:min-max标准化、Z-score标准化、Sigmoid函数标准
- 连续随机变量处理:Z-score标准化,Sigmoid函数标准
三.定类数据特征处理
我的上篇文章[数据预处理归一化详细解释]并没有介绍关于定类数据我们如何去处理,在本篇文章详细介绍一些常用的处理方法:
1.LabelEncoding
直接替换方法适用于原始数据集中只存在少量数据需要人工进行调整的情况。如果需要调整的数据量非常大且数据格式不统一,直接替换的方法也可以实现我们的目的,但是这种方法需要的工作量会非常大。因此, 我们需要能够快速对整列变量的所有取值进行编码的方法。
LabelEncoding,即标签编码,作用是为变量的 n 个唯一取值分配一个[0, n-1]之间的编码,将该变量转换成连续的数值型变量。
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() le.fit(['拥堵','缓行','畅行']) le.transform(['拥堵','拥堵','畅行','缓行'])
array([0, 0, 1, 2])
2.OneHotcoding
对于处理定类数据我们很容易想到将该类别的数据全部替换为数值:比如车辆拥堵情况,我们把拥堵标为1,缓行为2,畅行为3.那么这样是实现了标签编码的,但同时也给这些无量纲的数据转为了有量纲数据,我们本意是没有将它们比较之意的。机器可能会学习到“拥堵<缓行<畅行”,所以采用这个标签编码是不够的,需要进一步转换。因为有三种区间,所以有三个比特,即拥堵编码为100,缓行为010,畅行为001.如此一来每两个向量之间的距离都是根号2,在向量空间距离都相等,所以这样不会出现偏序性,基本不会影响基于向量空间度量算法的效果。
自然状态码为:000,001,010,011,100,101
独热编码为:000001,000010,000100,001000,010000,100000
我们可以使用sklearn的onehotencoder来实现:
from sklearn import preprocessing enc = preprocessing.OneHotEncoder() enc.fit([[0, 0, 1], [0, 1, 0], [1, 0, 0]]) # fit来学习编码 enc.transform([[0, 0, 1]]).toarray() # 进行编码
array([[1., 0., 1., 0., 0., 1.]])
数据矩阵是3*3的,那么原理是怎么来的呢?我们仔细观察:
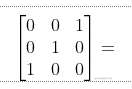
第一列的第一个特征维度有两种取值0/1,所以对应的编码方式为10、01.
第二列的第二个特征也是一样的,类比第三列的第三个特征。固001的独热编码就是101001了。
因为大部分算法是基于向量空间中的度量来进行计算的,为了使非偏序关系的变量取值不具有偏序性,并且到圆点是等距的。使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。将离散型特征使用one-hot编码,会让特征之间的距离计算更加合理。离散特征进行one-hot编码后,编码后的特征,其实每一维度的特征都可以看做是连续的特征。就可以跟对连续型特征的归一化方法一样,对每一维特征进行归一化。比如归一化到[-1,1]或归一化到均值为0,方差为1。
将离散特征通过one-hot编码映射到欧式空间,是因为,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。
优点:
独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
缺点:
当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA来减少维度。而且one hot encoding+PCA这种组合在实际中也非常有用。
应用场景:
独热编码用来解决类别型数据的离散值问题。
无用场景:
将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码。有些基于树的算法在处理变量时,并不是基于向量空间度量,数值只是个类别符号,即没有偏序关系,所以不用进行独热编码。 Tree Model不太需要one-hot编码: 对于决策树来说,one-hot的本质是增加树的深度。
代码实现
方法一: 实现one-hot编码有两种方法:sklearn库中的 OneHotEncoder() 方法只能处理数值型变量如果是字符型数据,需要先对其使用 LabelEncoder() 转换为数值数据,再使用 OneHotEncoder() 进行独热编码处理,并且需要自行在原数据集中删去进行独热编码处理的原变量。
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
lE = LabelEncoder()
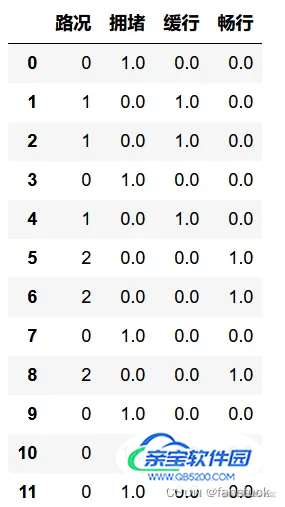
df=pd.DataFrame({'路况':['拥堵','畅行','畅行','拥堵','畅行','缓行','缓行','拥堵','缓行','拥堵','拥堵','拥堵']})
df['路况']=lE.fit_transform(df['路况'])
OHE = OneHotEncoder()
X = OHE.fit_transform(df).toarray()
df = pd.concat([df, pd.DataFrame(X, columns=['拥堵', '缓行','畅行'])],axis=1)
df
方法二:
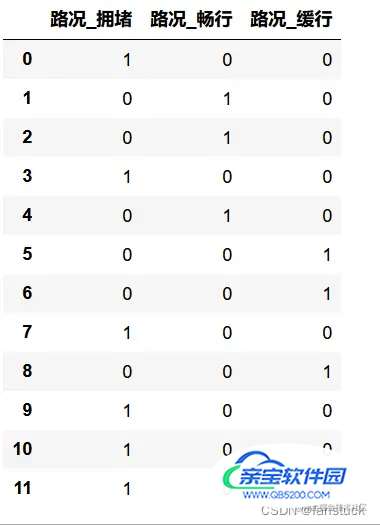
pandas自带get_dummies()方法
get_dummies() 方法可以对数值数据和字符数据进行处理,直接在原数据集上应用该方法即可。该方法产生一个新的Dataframe,列名由原变量延伸而成。将其合并入原数据集时,需要自行在原数据集中删去进行虚拟变量处理的原变量。
import pandas as pd
df=pd.DataFrame({'路况':['拥堵','畅行','畅行','拥堵','畅行','缓行','缓行','拥堵','缓行','拥堵','拥堵','拥堵']})
pd.get_dummies(df,drop_first=False)
加载全部内容