python中如何实现径向基核函数
柳叶吴钩 人气:01、生成数据集(双月数据集)
class moon_data_class(object):
def __init__(self,N,d,r,w):
self.N=N
self.w=w
self.d=d
self.r=r
def sgn(self,x):
if(x>0):
return 1;
else:
return -1;
def sig(self,x):
return 1.0/(1+np.exp(x))
def dbmoon(self):
N1 = 10*self.N
N = self.N
r = self.r
w2 = self.w/2
d = self.d
done = True
data = np.empty(0)
while done:
#generate Rectangular data
tmp_x = 2*(r+w2)*(np.random.random([N1, 1])-0.5)
tmp_y = (r+w2)*np.random.random([N1, 1])
tmp = np.concatenate((tmp_x, tmp_y), axis=1)
tmp_ds = np.sqrt(tmp_x*tmp_x + tmp_y*tmp_y)
#generate double moon data ---upper
idx = np.logical_and(tmp_ds > (r-w2), tmp_ds < (r+w2))
idx = (idx.nonzero())[0]
if data.shape[0] == 0:
data = tmp.take(idx, axis=0)
else:
data = np.concatenate((data, tmp.take(idx, axis=0)), axis=0)
if data.shape[0] >= N:
done = False
#print (data)
db_moon = data[0:N, :]
#print (db_moon)
#generate double moon data ----down
data_t = np.empty([N, 2])
data_t[:, 0] = data[0:N, 0] + r
data_t[:, 1] = -data[0:N, 1] - d
db_moon = np.concatenate((db_moon, data_t), axis=0)
return db_moon2、k均值聚类
def k_means(input_cells, k_count):
count = len(input_cells) #点的个数
x = input_cells[0:count, 0]
y = input_cells[0:count, 1]
#随机选择K个点
k = rd.sample(range(count), k_count)
k_point = [[x[i], [y[i]]] for i in k] #保证有序
k_point.sort()
global frames
#global step
while True:
km = [[] for i in range(k_count)] #存储每个簇的索引
#遍历所有点
for i in range(count):
cp = [x[i], y[i]] #当前点
#计算cp点到所有质心的距离
_sse = [distance(k_point[j], cp) for j in range(k_count)]
#cp点到那个质心最近
min_index = _sse.index(min(_sse))
#把cp点并入第i簇
km[min_index].append(i)
#更换质心
k_new = []
for i in range(k_count):
_x = sum([x[j] for j in km[i]]) / len(km[i])
_y = sum([y[j] for j in km[i]]) / len(km[i])
k_new.append([_x, _y])
k_new.sort() #排序
if (k_new != k_point):#一直循环直到聚类中心没有变化
k_point = k_new
else:
return k_point,km
3、高斯核函数
高斯核函数,主要的作用是衡量两个对象的相似度,当两个对象越接近,即a与b的距离趋近于0,则高斯核函数的值趋近于1,反之则趋近于0,换言之:
两个对象越相似,高斯核函数值就越大
作用:
- 用于分类时,衡量各个类别的相似度,其中sigma参数用于调整过拟合的情况,sigma参数较小时,即要求分类器,加差距很小的类别也分类出来,因此会出现过拟合的问题;
- 用于模糊控制时,用于模糊集的隶属度。
def gaussian (a,b, sigma):
return np.exp(-norm(a-b)**2 / (2 * sigma**2))
4、求高斯核函数的方差
Sigma_Array = []
for j in range(k_count):
Sigma = []
for i in range(len(center_array[j][0])):
temp = Phi(np.array([center_array[j][0][i],center_array[j][1][i]]),np.array(center[j]))
Sigma.append(temp)
Sigma = np.array(Sigma)
Sigma_Array.append(np.cov(Sigma))
5、显示高斯核函数计算结果
gaussian_kernel_array = []
fig = plt.figure()
ax = Axes3D(fig)
for j in range(k_count):
gaussian_kernel = []
for i in range(len(center_array[j][0])):
temp = Phi(np.array([center_array[j][0][i],center_array[j][1][i]]),np.array(center[j]))
temp1 = gaussian(temp,Sigma_Array[0])
gaussian_kernel.append(temp1)
gaussian_kernel_array.append(gaussian_kernel)
ax.scatter(center_array[j][0], center_array[j][1], gaussian_kernel_array[j],s=20)
plt.show()
6、运行结果
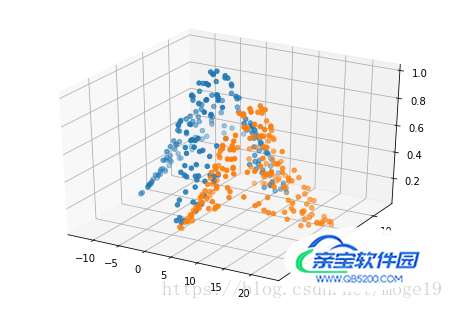
7、完整代码
# coding:utf-8
import numpy as np
import pylab as pl
import random as rd
import imageio
import math
import random
import matplotlib.pyplot as plt
import numpy as np
import mpl_toolkits.mplot3d
from mpl_toolkits.mplot3d import Axes3D
from scipy import *
from scipy.linalg import norm, pinv
from matplotlib import pyplot as plt
random.seed(0)
#定义sigmoid函数和它的导数
def sigmoid(x):
return 1.0/(1.0+np.exp(-x))
def sigmoid_derivate(x):
return x*(1-x) #sigmoid函数的导数
class moon_data_class(object):
def __init__(self,N,d,r,w):
self.N=N
self.w=w
self.d=d
self.r=r
def sgn(self,x):
if(x>0):
return 1;
else:
return -1;
def sig(self,x):
return 1.0/(1+np.exp(x))
def dbmoon(self):
N1 = 10*self.N
N = self.N
r = self.r
w2 = self.w/2
d = self.d
done = True
data = np.empty(0)
while done:
#generate Rectangular data
tmp_x = 2*(r+w2)*(np.random.random([N1, 1])-0.5)
tmp_y = (r+w2)*np.random.random([N1, 1])
tmp = np.concatenate((tmp_x, tmp_y), axis=1)
tmp_ds = np.sqrt(tmp_x*tmp_x + tmp_y*tmp_y)
#generate double moon data ---upper
idx = np.logical_and(tmp_ds > (r-w2), tmp_ds < (r+w2))
idx = (idx.nonzero())[0]
if data.shape[0] == 0:
data = tmp.take(idx, axis=0)
else:
data = np.concatenate((data, tmp.take(idx, axis=0)), axis=0)
if data.shape[0] >= N:
done = False
#print (data)
db_moon = data[0:N, :]
#print (db_moon)
#generate double moon data ----down
data_t = np.empty([N, 2])
data_t[:, 0] = data[0:N, 0] + r
data_t[:, 1] = -data[0:N, 1] - d
db_moon = np.concatenate((db_moon, data_t), axis=0)
return db_moon
def distance(a, b):
return (a[0]- b[0]) ** 2 + (a[1] - b[1]) ** 2
#K均值算法
def k_means(input_cells, k_count):
count = len(input_cells) #点的个数
x = input_cells[0:count, 0]
y = input_cells[0:count, 1]
#随机选择K个点
k = rd.sample(range(count), k_count)
k_point = [[x[i], [y[i]]] for i in k] #保证有序
k_point.sort()
global frames
#global step
while True:
km = [[] for i in range(k_count)] #存储每个簇的索引
#遍历所有点
for i in range(count):
cp = [x[i], y[i]] #当前点
#计算cp点到所有质心的距离
_sse = [distance(k_point[j], cp) for j in range(k_count)]
#cp点到那个质心最近
min_index = _sse.index(min(_sse))
#把cp点并入第i簇
km[min_index].append(i)
#更换质心
k_new = []
for i in range(k_count):
_x = sum([x[j] for j in km[i]]) / len(km[i])
_y = sum([y[j] for j in km[i]]) / len(km[i])
k_new.append([_x, _y])
k_new.sort() #排序
if (k_new != k_point):#一直循环直到聚类中心没有变化
k_point = k_new
else:
pl.figure()
pl.title("N=%d,k=%d iteration"%(count,k_count))
for j in range(k_count):
pl.plot([x[i] for i in km[j]], [y[i] for i in km[j]], color[j%4])
pl.plot(k_point[j][0], k_point[j][1], dcolor[j%4])
return k_point,km
def Phi(a,b):
return norm(a-b)
def gaussian (x, sigma):
return np.exp(-x**2 / (2 * sigma**2))
if __name__ == '__main__':
#计算平面两点的欧氏距离
step=0
color=['.r','.g','.b','.y']#颜色种类
dcolor=['*r','*g','*b','*y']#颜色种类
frames = []
N = 200
d = -4
r = 10
width = 6
data_source = moon_data_class(N, d, r, width)
data = data_source.dbmoon()
# x0 = [1 for x in range(1,401)]
input_cells = np.array([np.reshape(data[0:2*N, 0], len(data)), np.reshape(data[0:2*N, 1], len(data))]).transpose()
labels_pre = [[1] for y in range(1, 201)]
labels_pos = [[0] for y in range(1, 201)]
labels=labels_pre+labels_pos
k_count = 2
center,km = k_means(input_cells, k_count)
test = Phi(input_cells[1],np.array(center[0]))
print(test)
test = distance(input_cells[1],np.array(center[0]))
print(np.sqrt(test))
count = len(input_cells)
x = input_cells[0:count, 0]
y = input_cells[0:count, 1]
center_array = []
for j in range(k_count):
center_array.append([[x[i] for i in km[j]], [y[i] for i in km[j]]])
Sigma_Array = []
for j in range(k_count):
Sigma = []
for i in range(len(center_array[j][0])):
temp = Phi(np.array([center_array[j][0][i],center_array[j][1][i]]),np.array(center[j]))
Sigma.append(temp)
Sigma = np.array(Sigma)
Sigma_Array.append(np.cov(Sigma))
gaussian_kernel_array = []
fig = plt.figure()
ax = Axes3D(fig)
for j in range(k_count):
gaussian_kernel = []
for i in range(len(center_array[j][0])):
temp = Phi(np.array([center_array[j][0][i],center_array[j][1][i]]),np.array(center[j]))
temp1 = gaussian(temp,Sigma_Array[0])
gaussian_kernel.append(temp1)
gaussian_kernel_array.append(gaussian_kernel)
ax.scatter(center_array[j][0], center_array[j][1], gaussian_kernel_array[j],s=20)
plt.show()
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容