python数据处理之如何修改索引和行列
B.Bz 人气:0python如何修改索引和行列
修改索引
修改索引之前是自动生成的索引:
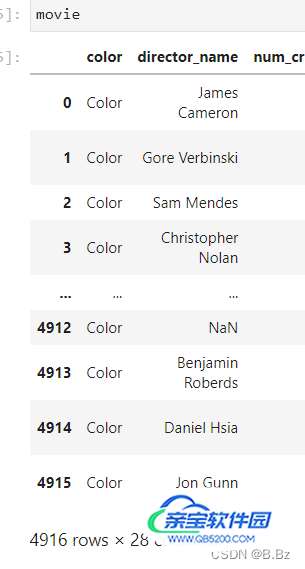
使用set_index('以xx字段为索引',inplace=True)设置索引:
inplace为True不用给新变量赋值,使用旧的变量名发现索引就已经被改变
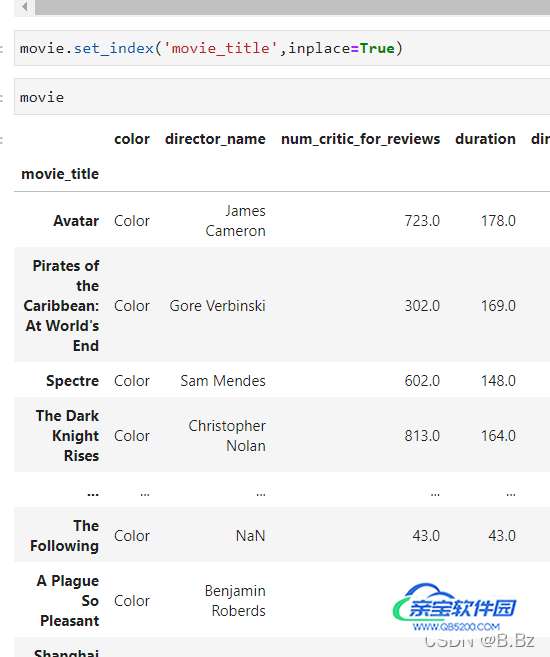
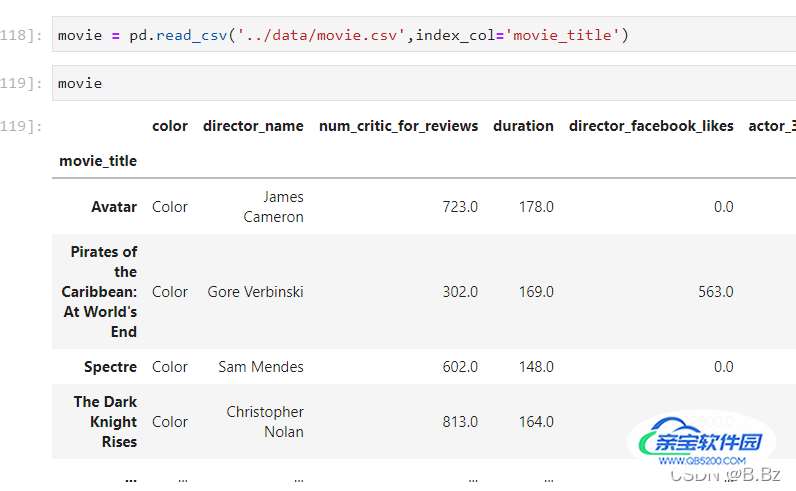
打开文件时就生成索引:
index_col='以xx字段为索引'
重置索引:
reset_index()

DataFrame修改行名和列名
通过rename方法修改:
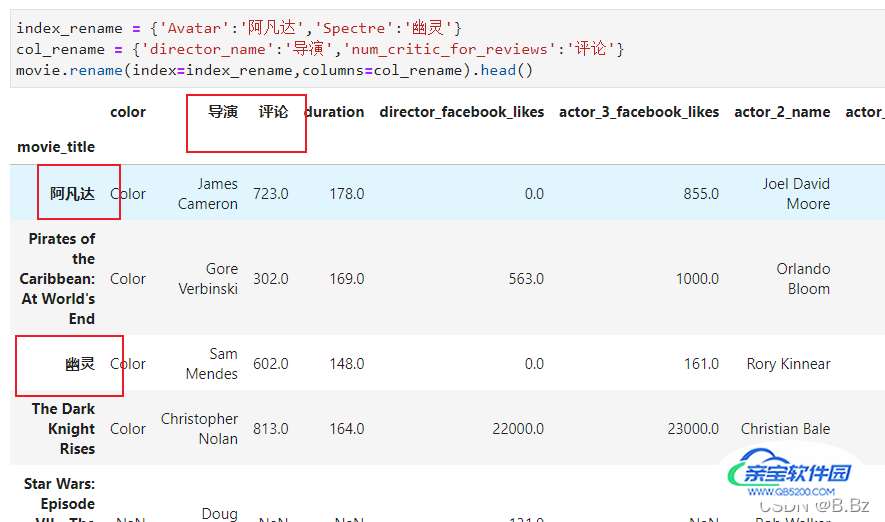
提取index和columns属性修改再赋值:
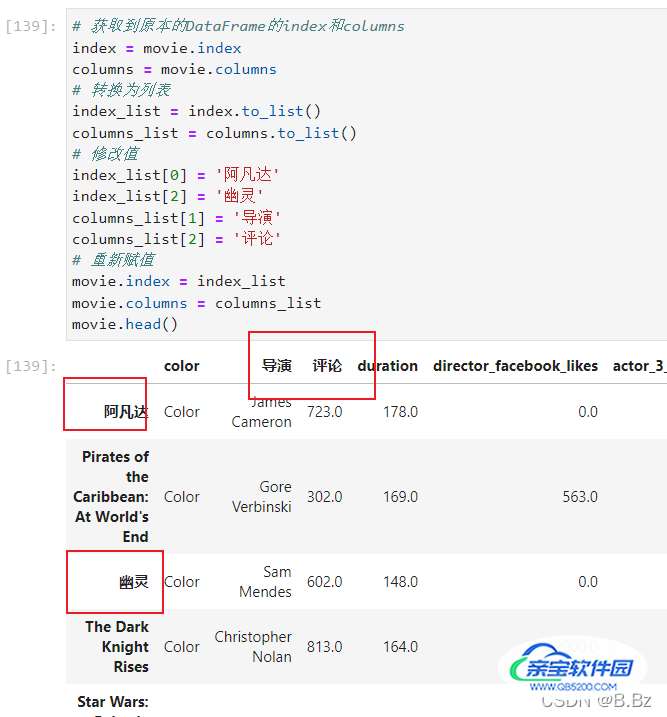
DataFrame添加、删除和插入队列
添加:
movie = pd.read_csv('../data/movie.csv')
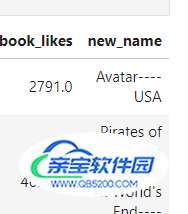
# 添加新列,并赋值 DataFrame['新列名'] = (值)
movie['new_name'] = (movie['movie_title'] + '----'+ movie['country'])
删除:
# 删除列
movie = movie.drop('new_name',axis='columns')
# 删除行
movie = movie.drop('索引',axis='index')
插入:
DataFrame.insert(loc='下标',column='列名',value='值')

python索引设置
在Python中如果没有原始索引,会默认从0开始的自然数作为索引。
给df表传入索引
#传入列宿索引 df.columns = ["name","age","grade","height","time"] #传入行索引 df.inex = [1,2,3,4,5,6] #传入的行列索引必须与行列数相同,否则报错
df中重置行索引
df.set_index("age")
#讲age列当做行索引,可传入多列,形成层次化索引
reset_index(level = None,drop = False,inplace = False) #将层次化索引重置
level:指定要讲层次化索引的第几级别转化为columns,默认全部转化
drop:指定是否阐述原索引,默认为False
inplace:指定是否修改原数据表,默认为False
#reset_index常用于数据分组及透视表中重命名索引
#重命名列索引,以字典的形式传入原列名和新列名
df.rename(columns = {"old":"new","age":"new_age"})
#重命名行索引,与上同
df.rename(index = {})
#行列索引同时修改
df.rename(columns = {},index = {})总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容