pytorch中关于backward的几个要点说明
老李今天学习了吗 人气:0pytorch中backward的2个要点
1. requires_grad
用pytorch定义一个网络层,如果数据中加入requires_grad=True,那么对于这个变量而言,就有了属于自己的导数(grad),如果这个数据是矩阵,那么他的grad是同样大小的一个矩阵。
我们将requires_grad视为该变量的一个属性,我们知道,我们在现实生活中,或者说在神经网络中,大部分的函数都是一阶连续可微的,也就是说,他的梯度具有唯一性。requires_grad的存在非常合理。
2. scale才能有backward
scale是标量的意思。
首先我们可用用如下语句查看等式中某个自变量的梯度。
print(x.grad, y.grad)
但是有个前提,我们必须要先对他的结果使用.backward()才能去查看,不然的话,他的梯度会显示为none。
非常需要注意的一点是,能够使用.backward()的必须是标量(scale),不然程序会报错。
结合实际的情况,我们看任何一个网络,使用backward的地方几乎只有一个,那就是loss.backward()。
首先loss肯定是一个标量,无论是MSE还是交叉熵,也无论是否加上了正则项,那都是求和之后的结果,也就是一个数值。这一点非常重要。
以下是我随意写的一个网络层,可以感受一下
import torch import torch.nn as nn class Linear(nn.Module): def __init__(self, inc, mult): super(Linear, self).__init__() self.intc = inc self.mult = mult def forward(self, input0): return torch.sum(torch.abs(input0*self.mult+self.intc)) def main(): x = torch.tensor(1.0, requires_grad=True) y = torch.tensor(2.0,requires_grad=True) z = x**2+y p = z*2+x p.backward() print(z, x.grad, y.grad) A = torch.ones([3,3],requires_grad=True) print(A.requires_grad) f = Linear(1, -2) b = f(A) print(b) b.backward() print(A.grad) if __name__ == '__main__': main()
pytorch中backward参数含义
1.标量与矢量问题
backward参数是否必须取决于因变量的个数,从数据中表现为标量和矢量;
- 例如标量时
- y=一个明确的值
- 矢量时
y=[y1,y2]
2.backward 参数计算公式
当因变量公式不是一个标量时,需要显式添加一个参数进行计算,以pytorch文档示例说明:
import torch a = torch.tensor([2., 3.], requires_grad=True) b = torch.tensor([6., 4.], requires_grad=True) Q = 3*a**3 - b**2
例如求解公式

external_grad = torch.tensor([1., 1.]) Q.backward(gradient=external_grad)
可以看到backward参数为[1,1],具体计算的含义,我们把Q公式拆分为标量形式即:

backward参数为[1,1],计算公式为

3.autograd
torch.autograd是计算向量和雅可比公式的乘积的引擎:
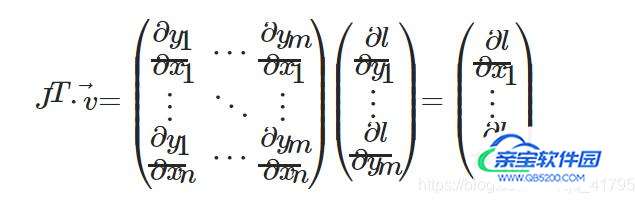
其中J就是因变量与自变量的雅可比公式,v即backward中的参数;类比于第二节的例子可对应;
前向传播得到数值后,利用此形式计算直接后向传播计算出损失函数对应各权值的梯度下降值
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容
 爱之家商城
爱之家商城 氢松练
氢松练 Face甜美相机
Face甜美相机 花汇通
花汇通 走路宝正式版
走路宝正式版 天天运动有宝
天天运动有宝 深圳plus
深圳plus 热门免费小说
热门免费小说