Python常见类型转换的小结
ftzchina 人气:0近期在工作中常常接触到各种转换,如字符串转byte,byte转字符串,还有byte数组转成报文能接纳的格式(bin格式的十六进制)。故有必要系统的总结一下Python中常见的类型转换。
一:常见类型的概念
| 类型 | 举例 | 说明 |
| 二进制 | a = 0b1010 | 二进制以0b打头 |
| 八进制 | b = 0o2345 | 八进制以0o打头(注意是字母的o) |
| 十进制 | c = 500 | 十进制没有前缀 |
| 十六进制 | d = 0x12ff | 十六进制以0x打头 |
| 字符串 | e = "ftz" | 字符串的内容用引号或双引号括住 |
| 字节 | f = b'f12345' | 字节以b修饰,内容用引号或双引号括住 |
| bin十六进制 | g = b'\x18\x17\x25' | 报文中的码流存在形式 |
二:类型转换
1,二进制,八进制,十进制,十六进制转换
>>> var = 100 >>> bin(var) #其他进制转二进制 '0b1100100' >>> oct(var) #其他进制转八进制 '0o144' >>> int(var) #其他进制转十进制 100 >>> hex(var) #其他进制转十六进制 '0x64' >>>
2,数值字符串转换
>>> var = 100 >>> >>> strNum = str(var) #数值转字符串 >>> strNum '100' >>> >>> intNum = int(strNum) #字符串转数值 >>> intNum 100 >>>
注意:字符串转数值常见,转换成功的前提是被转换的对象只有全是数字字符才可以,不然会报错如下所示,此场景的转换一般在转换前要对对象进行判断用字符串的方法isdigit()
>>> int('abc')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: 'abc'
>>> 'abc'.isdigit()
False
>>> '124'.isdigit()
True
>>>3,字符串和字节byte转换
解码的本质是选择二进制对应的图形,编码的本质是把字符图形转成相应编码的二进制。这只是一种显示的变化,在内存上并不一定有变化
>>> byteMyName = b'ftz' >>> strMyName = 'ftz' >>> >>> strMyName.encode() #字符串转byte b'ftz' >>> byteMyName.decode() #byte转字符串 'ftz'
下面具体看下两个转换方法
decode方法有两个参数,encoding默认是用'utf-8'进行解码,errors默认用'strict'模式,如果需要一定的容错,则用'ignore'
| decode(self, /, encoding='utf-8', errors='strict') | Decode the bytes using the codec registered for encoding. | | encoding | The encoding with which to decode the bytes. | errors | The error handling scheme to use for the handling of decoding errors. | The default is 'strict' meaning that decoding errors raise a | UnicodeDecodeError. Other possible values are 'ignore' and 'replace' | as well as any other name registered with codecs.register_error that | can handle UnicodeDecodeErrors.
decode() 方法的语法格式如下:
bytes.decode([encoding="utf-8"][,errors="strict"])
decode() 方法用于将 bytes 类型的二进制数据转换为 str 类型,这个过程也称为“解码”
decode()参数及含义
| 参数 | 含义 |
|---|---|
| bytes | 表示要进行转换的二进制数据。 |
| encoding="utf-8" | 指定解码时采用的字符编码,默认采用 utf-8 格式。当方法中只使用这一个参数时,可以省略“encoding=”,直接写编码方式即可。 注意,对 bytes 类型数据解码,要选择和当初编码时一样的格式。 |
| errors = "strict" | 指定错误处理方式,其可选择值可以是:
|
encode方法同样有两个参数,encoding默认是用'utf-8'编码进行转换
| encode(...) | S.encode(encoding='utf-8', errors='strict') -> bytes | | Encode S using the codec registered for encoding. Default encoding | is 'utf-8'. errors may be given to set a different error | handling scheme. Default is 'strict' meaning that encoding errors raise | a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and | 'xmlcharrefreplace' as well as any other name registered with | codecs.register_error that can handle UnicodeEncodeErrors.
encode() 方法的语法格式如下:
str.encode([encoding="utf-8"][,errors="strict"])
注意,格式中用 [] 括起来的参数为可选参数,也就是说,在使用此方法时,可以使用 [] 中的参数,也可以不使用。
encode()参数及含义
| 参数 | 含义 |
|---|---|
| str | 表示要进行转换的字符串。 |
| encoding = "utf-8" | 指定进行编码时采用的字符编码,该选项默认采用 utf-8 编码。例如,如果想使用简体中文,可以设置 gb2312。 当方法中只使用这一个参数时,可以省略前边的“encoding=”,直接写编码格式,例如 str.encode("UTF-8")。 |
| errors = "strict" | 指定错误处理方式,其可选择值可以是:
|
4,报文数据包和其他类型的互转
上面的都是铺垫,本节将是要重点介绍的内容。在用scapy构造报文或者编辑报文的过程中,常常需要从报文中提取我们感兴趣的内容或者将我们改造的数据插入到报文中。这里面就需要用到各种转换。最基本的操作就是将bin十六进制(报文中的数据,也称为码流)转int、转byte、转str。相反插入一段数据或者构造的数据到报文中,则是将int、byte、str类型转成bin十六进制。

下面将对十六进制码流和int、byte、str互转进行定义
| bin十六进制转int | 将二进制文件中的b“\x01\x79”转为“377”的过程。本质上讲,就是把一个byte型十六进制数,转成十进制数的过程。(注意区别:int(0x178)时参数0x179是16进制整型而b’\x01\x79’是byte数组) |
| int转bin十六进制 | 将“377”转为二进制文件中的b“\x01\x79”的过程。本质上讲,就是把一个十进制数,转成byte型十六进制数的过程。(注意区别:hex(377)得到的0x179是16进制整型而b’\x01\x79’是byte数组) |
| bin十六进制转byte | 将二进制文件中的b“\x04\xf9\x38\xad\x13\x26”取为b‘04f9381326’的过程。本质上讲,就是将每个十六进制数(4bit),转成一个采用ascii编码的byte(8bit)的过程 |
| byte转bin十六进制 | 将b‘04f9381326’取为二进制文件中的b“\x04\xf9\x38\xad\x13\x26”的过程。本质上讲,就是将每个采用ascii编码的byte(8bit),转成一个十六进制数(4bit)的过程 |
| bin十六进制转str | 将二进制文件中b’\x48\x54\x54\x50’取为字符串‘HTTP’的过程。本质上讲,就是将ascii编码转成对应字符的过程。 |
| str转bin十六进制 | 将字符串‘HTTP’取为二进制文件中b’\x48\x54\x54\x50’的过程。本质上讲,字符转成就是对应的ascii编码的过程 |
4.1 bin十六进制与int互转实现
bin十六进制转int主要在分析二进制文件、数据包头时获取长度等值时使用;相反,int转bin十六进制就是在构造二进制文件、数据包头时写入长度等值时使用。
另外注意把bin十六进制当数值时有大端和小端两种模式,大端意思是开头(低地址)权重大,小端为开头(低地址)权重小。文件系统一般用小端模式,网络传输一般用大端模式。
| 转换 | 方法 | 说明 |
| int转bin十六进制 | to_bytes(lenght,byteorder) | lenght表示转成的多少个字节;byteorder可为big或little分别表示转bin十六进制时使用大端模式还是小端模式 |
| bin十六进制转int | int.from_bytes(byte_var,byteorder) | byte_var是要转成数值的变bin十六进制变量,byteorder还是一样可为big或little,分别表示从bin十六进制转为数值时把bin十六进制当大端模式还是小端模式处理 |
举例:

将端口的对应的码流\xdc\x39转成56377
>>> int.from_bytes(b'\xdc\x39','big') 56377 >>>
将56377转成码流\xdc\x39
>>> port = 56377 >>> byteFromInt = port.to_bytes(2,'big') >>> byteFromInt b'\xdc9' >>> byteFromInt == b'\xdc\x39' True
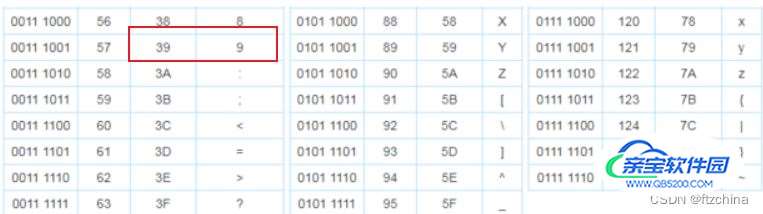
转出来为什么是\xdc9,我们查一下ascii码表,9对应的十六进制就是\x39
4.2 bin十六进制和byte互转实现
bin十六进制转byte主要在分析二进制文件、数据包头时获取mac地址、密钥等平时就以十六进制表示的值时使用;相反,byte转bin十六进制就是在构造二进制文件、数据包头时写入mac地址、密钥等平时就以十六进制表示的值时使用。这在用scapy构造数据包或者转换数据包时会经常用到,这里要用到第三方库binascii,使用时需要先导入
| 转换 | 方法 | 说明 |
| bin十六进制转byte | binascii.b2a_hex(bin_var) | bin_var为byte变量常从二进制文件中读出; 如binascii.b2a_hex(b’\x04\xf9\x38\xad\x13\x26’)结果为b’04f9381326‘ |
| byte转bin十六进制 | binascii.a2b_hex(hex_byte_var) | hex_byte_var为十六进制字节串; 如binascii.a2b_hex(b’04f9381326’)结果为b’\x04\xf98\x13&’(8对应的ascii编码是38,&对应的ascii编码是26) |
举例:
>>> import binascii >>> binascii.b2a_hex(b'\x48\x6f\x73\x74\x3a\x20\x63') #bin十六进制转byte b'486f73743a2063' >>> >>> binascii.a2b_hex(b'486f73743a2063') #byte转bin十六进制 b'Host: c' >>>
实际使用中我们经常会构造十六进制码流,然后将码流格式化成byte型,最后将byte转成bin十六进制
4.3 bin十六进制与str互转
bin十六进制转主要在分析二进制文件、数据包头时获取其量的字符串时使用;相反,byte转bin十六进制就是在构造二进制文件、数据包头时写入字符串时使用。
bin十六进制与str互转其实就是字符串和byte互转;此处的bin十六进制就是byte的本质。(b’\x48\x54\x54\x50’和b’HTTP’在内存中是一模一样的)
| 转换 | 方法 | 说明 |
| bin十六进制转str | decode | 在第3节中有详细介绍 |
| str转bin十六进制 | encode | 在第3节中有详细介绍 |
举例:

>>> byteHost = b'\x48\x6f\x73\x74' >>> >>> byteHost.decode() 'Host' >>> >>> str = 'Host' >>> str.encode() b'Host' >>>
加载全部内容