java之CSV大批量数据入库的实现
邱可爱 人气:0需求
读200+的CSV/EXCEL文件,按文件名称存到不同数据库
前期准备
环境
maven + jdk8 + mysql
代码展示
pom文件
<dependencies>
<!--https://mvnrepository.com/artifact/com.opencsv/opencsv -->
<dependency> //读取csv文件
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>${opencsv.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--mybatis-plus 持久层-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!-- velocity 模板引擎, Mybatis Plus 代码生成器需要 -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>${velocity.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
关键代码及思路
多线程处理数据,否则8k万数据太慢了
创建线程池,个数的大小一般取决于自己电脑配置,以及I/O还是CPU密集型。
- I/O密集型:CPU*2 + 1
- CPU密集型:CPU + 1
- Java查看CPU数目
public static final Integer N_Thread = Runtime.getRuntime().availableProcessors() * 2 + 1;
ExecutorService service = Executors.newFixedThreadPool(N_Thread ); List<CompletableFuture<Void>> futureList = new ArrayList<>();
数据进行分批处理,如果数据一次过大,可能导致sql拼接失败或者程序连接超时的问题。
List<AirStationHourEntity> records = new ArrayList<>(table.values());
int basic = 0, total = records.size();
do{
int finalBasic = basic;
String finalTableName = tableName;
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> {
List<AirStationHourEntity> subRecords = records.subList(finalBasic * 6000, Math.min((1 + finalBasic) * 6000, total));
airStationHourMapper.saveOrUpdateBatch(finalTableName, subRecords);
}, service);
// 加入线程集合,方便后续阻塞主线程,防止线程没跑就提前结束
futureList.add(completableFuture);
basic++;
}while (basic * 6000 < total);
获取文件数据
String url = dataConfig.getStation();
List<String> stationFiles = FileUtils.findFiles(url);
//遍历文件
for (String fileName : stationFiles) {
try {
// 读取文件数据
String path = url.concat(fileName);
CSVReader reader = new CSVReader(new InputStreamReader(new FileInputStream(path), StandardCharsets.UTF_8));
List<String[]> lines = reader.readAll();
根据文件名创建相应数据库
tableName = fileName.substring(fileName.lastIndexOf("_") + 1, fileName.indexOf(".") - 2);
tableName = TABLE_PREFIX.STATION_PREFIX.value.concat(tableName);
if (airStationHourMapper.findTableByName(tableName) == 0) {
airStationHourMapper.createNewTable(tableName);
}
注意:如果在主线程完成之后,没有对主线程进行阻塞,会导致线程池中的线程没跑完就直接结束了,需要遍历线程集合来阻塞主线程
for (CompletableFuture<Void> future : futureList) {
future.join();
}
关键的SQL语句
saveOrUpdateBatch
这里选用Mysql提供的ON DUPLICATE KEY UPDATE来实现更新或者插入,如果primary key 或者 unique key不存在就插入,否则就更新。注意:primary key 和 unique key都存在的时候可能会导致数据的更新的异常,这里建议选其中一个最为键,否则容易死锁!见方案选型
<update id="saveOrUpdateBatch">
insert into ${tableName}
(
<include refid="Base_Column_List"/>
)
values
<foreach collection="records" item="record" separator=",">
(
#{record.dataId,jdbcType=VARCHAR},
#{record.stationId,jdbcType=VARCHAR},
#{record.dataTime,jdbcType=TIMESTAMP},
#{record.aqi,jdbcType=INTEGER},
#{record.priPol,jdbcType=VARCHAR},
#{record.co,jdbcType=DOUBLE},
#{record.co24,jdbcType=DOUBLE},
#{record.no2,jdbcType=INTEGER},
#{record.no224,jdbcType=INTEGER},
#{record.so2,jdbcType=INTEGER},
#{record.so224,jdbcType=INTEGER},
#{record.o3,jdbcType=INTEGER},
#{record.o324,jdbcType=INTEGER},
#{record.o38,jdbcType=INTEGER},
#{record.o3824,jdbcType=INTEGER},
#{record.pm10,jdbcType=INTEGER},
#{record.pm1024,jdbcType=INTEGER},
#{record.pm25,jdbcType=INTEGER},
#{record.pm2524,jdbcType=INTEGER}
)
</foreach>
ON DUPLICATE KEY UPDATE
AQI = VALUES(AQI),pri_pol = VALUES(pri_pol),
CO = VALUES(CO),CO_24 = VALUES(CO_24),
NO2 = VALUES(NO2),NO2_24 = VALUES(NO2_24),
SO2 = VALUES(SO2),SO2_24 = VALUES(SO2_24),
O3 = VALUES(O3),O3_8 = VALUES(O3_8),O3_8_24 = VALUES(O3_8_24),
PM10 = VALUES(PM10),PM10_24 = VALUES(PM10_24),
PM2_5 = VALUES(PM2_5),PM2_5_24 =VALUES(PM2_5_24);
</update>
方案选型
此方案时间过久,10多个小时大概能完成100w+的数据;
在程序中查询数据库中现存的数据,然后对这些数据进行更新,其余的进行插入
此方案程序代码看起来较繁琐。
选用 ON DUPLICATE KEY UPDATE & 多线程来实现批量处理。 问题 在处理最后一些数据时,报异常:获取不到数据库连接,连接超时

解决方案
修改application.yml的sql配置
hikari:
connection-timeout: 600000 //时间设的长一些
当即存在primary key 以及 unique key时,出现了死锁
如果一个表定义有多个唯一键(包括唯一索引、主键)时,是不安全的。
当mysql执行INSERT ON DUPLICATE KEY的INSERT时,存储引擎会检查插入的行为是否产生重复错误。
org.springframework.dao.DeadlockLoserDataAccessException: ### Error updating database. Cause: com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction ### The error may exist in class path resource [mapper/PersonGroupRefMapper.xml] ### The error may involve com.order.addOrder-Inline ### The error occurred while setting parameters ### SQL: insert into t_***(XX,XX,XX,XX,XX,XX) values (?, ?, ?, ?, ?, ?) ON DUPLICATE KEY UPDATE XX= VALUES(XX), XX= VALUES(XX), XX= VALUES(XX) ### Cause: com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction Deadlock found when trying to get lock; try restarting transaction; nested exception is com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transactio
解决方案
见上面关键SQL,删除了primary key 留下了unique key重新建表。
见上面关键SQL,删除了primary key 留下了unique key重新建表。
批量数据入库,当SQL语句拼接过长,超过了设置的最大的限制。

解决方案
批量数据入库时,稍微减少数据量再进行插入,如6000条数据减为4000数据之后再批量入库。
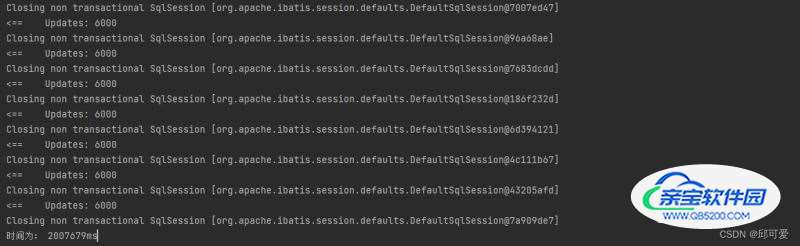
运行结果
相比之前一天200W+数据有了质的提升,半小时完成了所有数据的预处理以及入库。
到此这篇关于java之CSV大批量数据入库的实现的文章就介绍到这了,更多相关java CSV大批量入库内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
加载全部内容