ElasticSearch不停机重建索引延伸思考及优化详解
云雨雪 人气:0前言
距离我第一次上手ES过去了一年半多了吧,当时我是从零开始花了大半年时间搭建了一整套Filebeat+Kafka+数据处理服务+Elasticsearch+Kibana+Skywalking日志收集系统。感觉还是很刺激的,毕竟同时去深度学习和运用多个刚上手的中间件对我来说是个极大的磨练。日志收集系统的数据处理服务切换到了Flink,这个后面总结完毕后我会出一篇单独的文章讲讲Flink和改造过程。但是始终有一个问题困扰着我,团队内部对于ES的应用尚浅,仅仅用来做日志收集,导致我对ES的认识一直不算深刻,所以我之前也没有写一篇优秀的文章来阐述我的认知。当然现在我依旧算个小白,但是因为一两个需求重新深刻认识了ES,算是一段不错的经历,因此分享给大家,有问题的话请各位大佬指正。
需求
同事提给我的,说是需要对过去半年时间做一个系统应用的用户使用情况统计,很急。具体是需要按照系统分组统计每个用户的使用情况,很好,之前完全没有单独设计过相关的统计入口,因此只能根据日志内容硬写查询语句了。因为需求比较麻烦,所以注定是个复杂聚合查询,不巧的是我对于ES的查询API有点忘了,只能现学现卖了。为啥不熟呢?我自己总结的原因一是日志场景单一,JavaAPI只需要布尔查询拼条件即可,不会很复杂,后面改成Kibana后索引模式用上就不存在什么API调用了。原因二是由于工作繁忙,没有别的技术场景,因此没有太关注ES的API部分,重点都是在性能优化和日志收集系统的完善上面。
除了上面的复杂查询让我稍微感到难度之外,在聚合查询的时候还发现了历史遗留的问题,新索引优化了映射并没有修改老索引,因此新老索引映射是有一点区别的,需要重建索引。重建索引自然要上真实场景,不停机重建索引。
查询本体
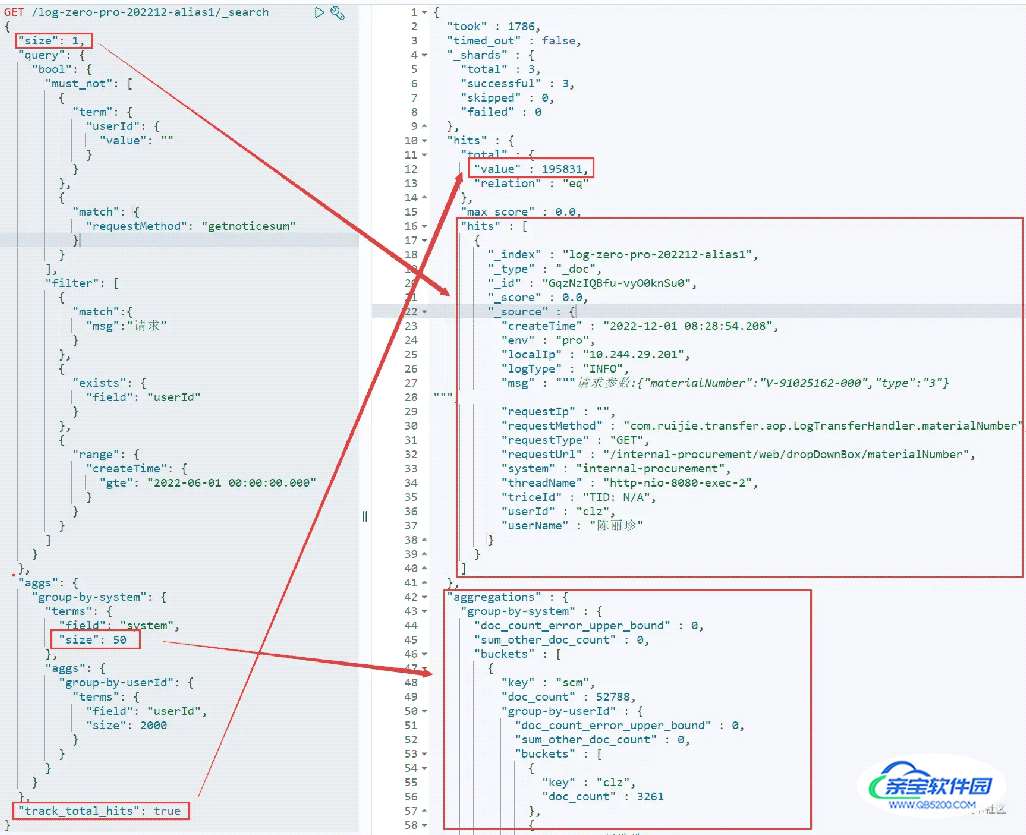
对应查询语句和执行结果如上图,简要提几点限制打开的方法和一些优化的手段。
查询限制
1.查询总数默认限制10000条
查询时带上"track_total_hits": true,打开限制,返回真实条数
2.聚合查询时使用term,默认限制10条
聚合查询参数中加上"size": 50,配置展示最多50条
聚合查询优化
聚合查询为了尽量返回少的数据量,提升查询效率,通常设置size为0,体现为查询结果中hits不返回具体文档数据。
遇到问题
1.text类型不支持聚合
报错内容:
Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [userId] in order to load field data by uninverting the inverted index. Note that this can use significant memory(文本字段未针对需要每个文档字段数据的操作(如聚合和排序)进行优化,因此默认情况下禁用这些操作。请改用关键字字段。或者,在 [userId] 上设置 fielddata=true,以便通过反转倒排索引来加载字段数据。请注意,这可能会占用大量内存)
解决方案:
text类型默认不支持聚合和排序,因此要么修改mapping增加属性fielddata=true,或者直接修改字段类型为keyword
2.分词查询时不知道写哪些词
查询文档分词结果--索引=log-zero-pro-202302-alias1,id=1xKdCoYBeajfMMIRdyre,字段=msg
GET /log-zero-pro-202302-alias1/_doc/1xKdCoYBeajfMMIRdyre/_termvectors?fields=msg
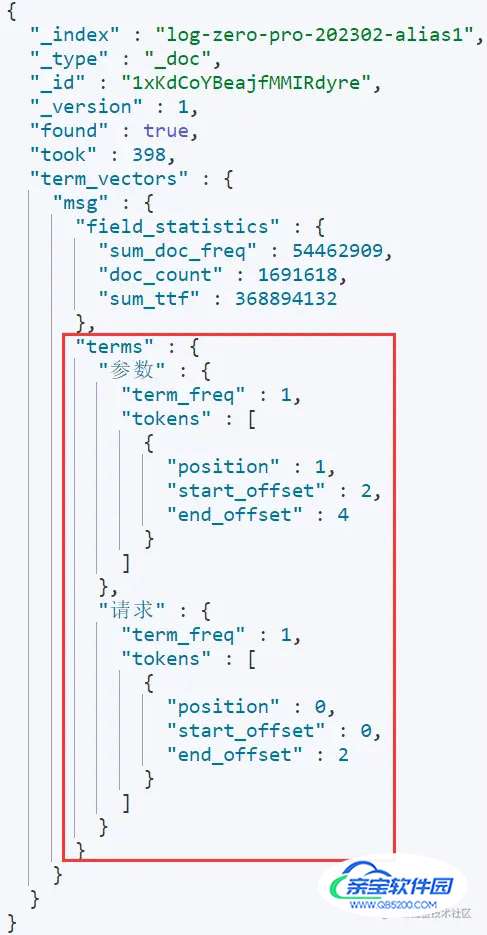
我想这是大多数新手遇到的问题,配了分词后,我就随便乱输发现匹配不了,开始懵逼,疑惑这分词怎么没有效果。但是我们把分词当作一个模糊查询去用了,两者还是有一定区别的,特别是粗分词的时候,不太熟练的情况下,还是先查一下分成啥样再去查询比较好。
不停机重建索引
为啥要重建索引呢?因为索引创建之后是不允许修改映射的,如果修改只能重建。不停机重建索引的步骤还是比较简单,就三步。
新建索引
新建索引正常建就行,因为重建索引用到了reIndex这个API,内部是由scroll+bulk实现,本质上就是先查询再批量插入。因此可以做一些写入优化,副本数可以先设置为0,刷新间隔禁用,落盘机制调整异步和延迟。
PUT /log-zero-pro-202206_re/_settings
{
"index" : {
"number_of_replicas" : 0,
"refresh_interval": "-1"
}
}
切换别名指向新索引
ES的索引设计时最好提前加上一个别名,用别名去管理索引,它就像一层代理,让我们不用在意底层索引,可以随时切换。我们建立一个新的索引后,将别名指向新的索引,这样新数据就会灌到新索引中,避免老索引在迁移中仍有数据进入,导致数据迁移不完整,需要二次迁移。
POST /_aliases
{
"actions" : [
{ "remove" : { "index" : "log-zero-pro-202207-alias1", "alias" : "log-zero-pro-202207" } },
{ "add" : { "index" : "log-zero-pro-202207_re", "alias" : "log-zero-pro-202207" } }
]
}
迁移数据
选择ES自带的reIndex进行迁移,这里尽量优化一下
- slices=auto&refresh,因为内部使用scroll查询,因此可以选择分片查询提升效率,auto意思是自动改成索引分片数
- wait_for_completion=false,为了避免迁移时间过长超时,所以选择异步执行
- size: 5000,也是提升单次查询数据,默认1000条,根据实际插入效率动态调整
POST _reindex?slices=auto&refresh&wait_for_completion=false
{
"conflicts": "proceed",
"source": {
"index": "log-zero-pro-202207-alias1",
"size": 5000
},
"dest": {
"index": "log-zero-pro-202207_re"
}
}
结果
{
"task" : "iDnr1JBPRjyPVqwl2TcqqA:889565588"
}
查询异步迁移任务详情
有两个API可以调用,上面是查询所有reindex任务,下面是查询某个任务的详情,一般用下面的查看任务是否完成
GET _tasks?detailed=true&actions=*reindex GET /_tasks/iDnr1JBPRjyPVqwl2TcqqA:889578807
调整正常索引配置
把之前的副本和刷新禁用重新打开
PUT /log-zero-pro-202206_re/_settings
{
"index" : {
"number_of_replicas" : 1,
"refresh_interval": "1s"
}
}
莫名想到了MySQL扩容,就顺道来聊聊,扩容和重建索引不是一回事哈,不能直接对比。
MySQL扩容
当前已存在n台数据库,并且通过id取模。一般是m*n扩容m倍,这样做元素迁移时比较方便,当然更建议一开始给足数据库,尽量不要扩容,增加操作风险。扩容通常分为停机和不停机两种,各有优劣。
停机扩容
最简单的方案,找个没人的深夜停机,写个程序读取老的n台数据库,按照id重新取模输入到新的m*n台数据库上,修改应用配置再重新上线。
回滚也方便,发现出问题,把配置修改为之前的,继续用老数据库,啥时候新的弄对了再迁过去。
优点就是简单明了,缺点就是费人,而且万一运行了一段时间后发现搞错了,只能回退到扩容前,会丢失部分数据。
不停机扩容
这个就相对复杂,假设现在有两台数据库A和B,选择两倍扩容,也就是增加到四台ABCD。
- A和C,B和D分别配置双主同步,等待数据同步完成。
- 修改应用路由配置同时写入ABCD四台数据库,取模规则变成四等分
- 删除双主同步,同时删除四台数据库里的冗余数据(不属于当前取模规则的数据)
优点很多啊,最重要的就是不停机,而且占用资源也少,原来两台数据库也用上了。回滚也简单,只要不删除冗余数据,随时都能切回来,直接修改取模规则即可。缺点就是比较复杂,双主同步、双写,而且老数据库较大的时候,扩容相当费时费力。
随便聊聊
其实在做ES不停机重建索引的时候,我一开始是没想到这么简单的,居然几条命令就搞定了,WTF。但是事实就是这样,分布式架构面对单体架构的优势是碾压式的,这也是我最近在看分布式数据库TiDB的原因,迟早会迁移过去的。啥也不说,运维成本相对就低了,几条命令就完成了,细节不用管还更有保障,排除了单体架构时人为原因,这可太爽了。
最后
最近有个问题难住我了,flink往es写数据放在服务器上跑老是报错,我这菜的还解决不了,少年痛苦祈祷中。回到ES,本次也算是再次加深了我对ES的认识,还可以,有所收获。下一篇绝对是口语化系列了,这篇属于临时小插曲,大约2个晚上写完,还算不错。鸭梨很大,日子难过啊,啊啊啊啊啊,我一定要让这痛苦压抑的世界绽放幸福快乐之花。
加载全部内容