一篇文章带你弄清楚Redis的精髓
京东云官方 人气:0一、Redis的特性
1.1 Redis为什么快?
- 基于内存操作,操作不需要跟磁盘交互,单次执行很快
- 命令执行是单线程,因为是基于内存操作,单次执行的时间快于线程切换时间,同时通信采用多路复用
- Redis本身就是一个k-v结构,类似于hashMap,所以查询性能接近于O(1)
- 同时redis自己底层数据结构支持,比如跳表、SDS
- lO多路复用,单个线程中通过记录跟踪每一个sock(I/O流)的状态来管理多个I/O流
1.2 Redis其他特性
- 更丰富的数据类型,虽然都是k、v结构,value可以存储很多的数据类型
- 完善的内存管理机制、保证数据一致性:持久化机制、过期策略
- 支持多种编程语言
- 高可用,集群、保证高可用
1.3 Redis高可用
- 很完善的内存管理机制,过期、淘汰、持久化
- 集群模式,主从、哨兵、cluster集群
二、Redis数据类型以及使用场景
Redis的数据类型有String、Hash、Set、List、Zset、bitMap(基于String类型)、 Hyperloglog(基于String类型)、Geo(地理位置)、Streams流。
2.1 String
2.1.1 基本指令
// 批量设置 > mset key1 value1 key2 value2 // 批量获取 > mget key1 key2 // 获取长度 > strlen key // 字符串追加内容 > append key xxx // 获取指定区间的字符 > getrange key 0 5 // 整数值递增 (递增指定的值) > incr intkey (incrby intkey 10) // 当key 存在时将覆盖 > SETEX key seconds value // 将 key 的值设为 value ,当且仅当 key 不存在。 > SETNX key value
2.1.2 应用场景
- 缓存相关场景 缓存、 token(跟过期属性完美契合)
- 线程安全的计数场景 (软限流、分布式ID等)
2.2 Hash
2.2.1 基本指令
// 将哈希表 key 中的域 field 的值设为 value 。 > HSET key field value // 返回哈希表 key 中给定域 field 的值。 > HGET key field // 返回哈希表 key 中的所有域。 > HKEYS key // 返回哈希表 key 中所有域的值。 > HVALS key // 为哈希表 key 中的域 field 的值加上增量 increment 。 > HINCRBY key field increment // 查看哈希表 key 中,给定域 field 是否存在。 > HEXISTS key field
2.2.2 应用场景
- 存储对象类的数据(官网说的)比如一个对象下有多个字段
- 统计类的数据,可以对单个统计数据进行单独操作
2.3 List
存储有序的字符串列表,元素可以重复。列表的最大长度为 2^32 - 1 个元素(4294967295,每个列表超过 40 亿个元素)。
2.3.1 基本指令
// 将一个或多个值 value 插入到列表 key 的表头 > LPUSH key value [value ...] // 将一个或多个值 value 插入到列表 key 的表尾(最右边)。 > RPUSH key value [value ...] // 移除并返回列表 key 的头元素。 > LPOP key // 移除并返回列表 key 的尾元素。 > RPOP key // BLPOP 是列表的阻塞式(blocking)弹出原语。 > BLPOP key [key ...] timeout // BRPOP 是列表的阻塞式(blocking)弹出原语。 > BRPOP key [key ...] timeout // 获取指点位置元素 > LINDEX key index
2.3.2 应用场景
- 用户消息时间线
因为list是有序的,所以我们可以先进先出,先进后出的列表都可以做
2.4 Set
2.4.1 基本指令
// 将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略。 > SADD key member [member ...] // 返回集合 key 中的所有成员。 > SMEMBERS key // 返回集合 key 的基数(集合中元素的数量)。 > SCARD key // 如果命令执行时,只提供了 key 参数,那么返回集合中的一个随机元素。 > SRANDMEMBER key [count] // 移除并返回集合中的一个随机元素。 > SPOP key // 移除集合 key 中的一个或多个 member 元素,不存在的 member 元素会被忽略。 > SREM key member [member ...] // 判断 member 元素是否集合 key 的成员。 > SISMEMBER key member // 获取前一个集合有而后面1个集合没有的 > sdiff huihuiset huihuiset1 // 获取交集 > sinter huihuiset huihuiset1 // 获取并集 > sunion huihuiset huihuiset1
2.4.2 应用场景
- 抽奖 spop跟srandmember随机弹出或者获取元素
- 点赞、签到等,sadd集合存储
- 交集并集 关注等场景
2.5 ZSet(SortedSet)
sorted set,有序的set,每个元素有个score。
score相同时,按照key的ASCII码排序。
2.5.1 基本指令
//将一个或多个 member 元素及其 score 值加入到有序集 key 当中。 > ZADD key score member [[score member] [score member] ...] // 返回有序集 key 中,指定区间内的成员。其中成员的位置按 score 值递增(从小到大)来排序 > ZRANGE key start stop [WITHSCORES] // 返回有序集 key 中,指定区间内的成员。其中成员的位置按 score 值递减(从大到小)来排列。 > ZREVRANGE key start stop [WITHSCORES] // 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。 > ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] // 移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。 > ZREM key member [member ...] // 返回有序集 key 的基数。 > ZCARD key // 为有序集 key 的成员 member 的 score 值加上增量 increment 。 > ZINCRBY key increment member // 返回有序集 key 中, score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max )的成员的数量。 > ZCOUNT key min max // 返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递增(从小到大)顺序排列。 > ZRANK key member
2.5.2 应用场景
- 排行榜
三、Redis的事务
3.1 事务基本操作
// 1. multi命令开启事务,exec命令提交事务 127.0.0.1:6379> multi OK 127.0.0.1:6379(TX)> set k1 v1 QUEUED 127.0.0.1:6379(TX)> set k2 v2 QUEUED 127.0.0.1:6379(TX)> exec 1) OK 2) OK // 2. 组队的过程中可以通过discard来放弃组队。 127.0.0.1:6379> multi OK 127.0.0.1:6379(TX)> set k3 v3 QUEUED 127.0.0.1:6379(TX)> set k4 v4 QUEUED 127.0.0.1:6379(TX)> discard OK
3.2 Redis事务特性
- 单独的隔离操作
事务中的所有命令都会序列化、按顺序地执行。
事务在执行过程中,不会被其他客户端发送来的命令请求所打断。
- 没有隔离级别的概念
队列中的命令没有提交之前,都不会被实际地执行,因为事务提交之前任何指令都不会被实际执行,也就不存在“事务内的查询要看到事务里的更新,在事务外查询不能看到”这个让人万分头疼的问题。
- 不保证原子性
Redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚。
四、Redis 分布式锁
4.1 Lua 实现分布式锁
local lockSet = redis.call('exists', KEYS[1])
if lockSet == 0
then
redis.call('set', KEYS[1], ARG[1])
redis.call('expire', KEYS[1], ARG[2])
end
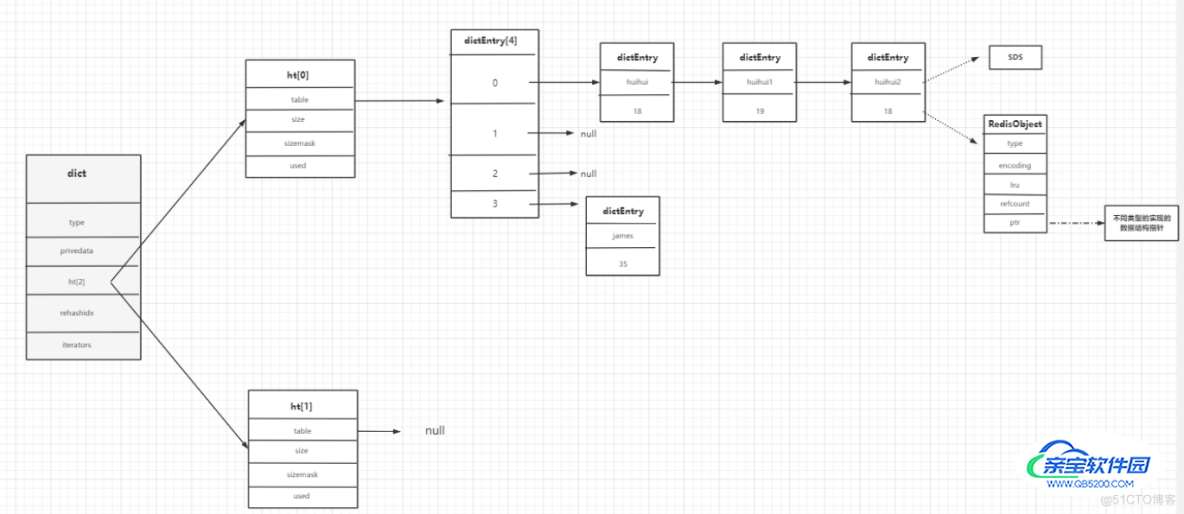
return lockSet5.1 Redis dict字典
5.1.1 RedisDb数据接口(server.h文件)
数据最外层的结构为RedisDb
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */ //数据库的键
dict *expires; /* Timeout of keys with a timeout set */ //设置了超时时间的键
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/ //客户端等待的keys
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */ //所在数 据库ID
long long avg_ttl; /* Average TTL, just for tats */ //平均TTL,仅用于统计
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;5.1.2 dict数据结构(dict.h文件)
我们发现数据存储在dict中
typedef struct dict {
dictType *type; //理解为面向对象思想,为支持不同的数据类型对应dictType抽象方法,不同的数据类型可以不同实现
void *privdata; //也可不同的数据类型相关,不同类型特定函数的可选参数。
dictht ht[2]; //2个hash表,用来数据存储 2个dictht
long rehashidx; /* rehashing not in progress if rehashidx == -1 */ // rehash标记 -1代表不再rehash
unsigned long iterators; /* number of iterators currently running */
} dict;5.1.3 dictht结构(dict.h文件)
typedef struct dictht {
dictEntry **table; //dictEntry 数组
unsigned long size; //数组大小 默认为4 #define DICT_HT_INITIAL_SIZE 4
unsigned long sizemask; //size-1 用来取模得到数据的下标值
unsigned long used; //改hash表中已有的节点数据
} dictht;5.1.4 dictEntry节点结构(dict.h文件)
typedef struct dictEntry {
void *key; //key
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; //value
struct dictEntry *next; //指向下一个节点
} dictEntry;/* Objects encoding. Some kind of objects like Strings and
Hashes can be
* internally represented in multiple ways. The 'encoding'
field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old
list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string
encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list
of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree
of listpacks */
#define LRU_BITS 24
#define LRU_CLOCK_MAX ((1<<LRU_BITS)-1) /* Max value of
obj->lru */
#define LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution
in ms */
#define OBJ_SHARED_REFCOUNT INT_MAX /* Global object
never destroyed. */
#define OBJ_STATIC_REFCOUNT (INT_MAX-1) /* Object
allocated in the stack. */
#define OBJ_FIRST_SPECIAL_REFCOUNT OBJ_STATIC_REFCOUNT
typedef struct redisObject {
unsigned type:4; //数据类型 string hash list
unsigned encoding:4; //底层的数据结构 跳表
unsigned lru:LRU_BITS; /* LRU time (relative to global
lru_clock) or
* LFU data (least significant
8 bits frequency
* and most significant 16 bits
access time). */
int refcount; //用于回收,引用计数法
void *ptr; //指向具体的数据结构的内存地址 比如 跳表、压缩列表
} robj;5.2 Redis数据结构图
5.3 Redis扩容机制
因为我们的dictEntry数组默认大小是4,如果不进行扩容,那么我们所有的数据都会以链表的形式添加至数组下标 随着数据量越来越大,之前只需要hash取模就能得到下标位置,现在得去循环我下标的链表,所以性能会越来越慢,当我们的数据量达到一定程度后,我们就得去触发扩容操作。
5.3.1 什么时候扩容
5.3.1.1 扩容机制
- 当没有fork子进程在进行RDB或AOF持久化时,ht[0]的used大于size时,触发扩容
- 如果有子进程在进行RDB或者AOF时,ht[0]的used大于等于size的5倍的时候,会触发扩容
5.3.1.2 源码验证
扩容,肯定是在添加数据的时候才会扩容,所以我们找一个添加数据的入口。
- 入口,添加或替换dictReplace (dict.c文件)
int dictReplace(dict *d, void *key, void *val) {
dictEntry *entry, *existing, auxentry;
/* Try to add the element. If the key
* does not exists dictAdd will succeed. */
entry = dictAddRaw(d,key,&existing);
if (entry) {
dictSetVal(d, entry, val);
return 1;
}
/* Set the new value and free the old one. Note that
it is important
* to do that in this order, as the value may just be
exactly the same
* as the previous one. In this context, think to
reference counting,
* you want to increment (set), and then decrement
(free), and not the
* reverse. */
auxentry = *existing;
dictSetVal(d, existing, val);
dictFreeVal(d, &auxentry);
return 0;
}- 进入dictAddRaw方法 (dict.c文件)
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing){
long index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); //如果正在Rehash 进行渐进式hash 按步rehash
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key),existing)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that
in a database
* system it is more likely that recently added
entries are accessed
* more frequently. */
//如果在hash 放在ht[1] 否则放在ht[0]
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
//采用头插法插入hash桶
entry->next = ht->table[index];
ht->table[index] = entry;
//已使用++
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}static long _dictKeyIndex(dict *d, const void *key,uint64_t hash, dictEntry **existing){
unsigned long idx, table;
dictEntry *he;
if (existing) *existing = NULL;
/* Expand the hash table if needed */
//扩容如果需要
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
//比较是否存在这个值
for (table = 0; table <= 1; table++) {
idx = hash & d->ht[table].sizemask;
/* Search if this slot does not already contain
the given key */
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key,he->key)) {
if (existing) *existing = he;
return -1;
}
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return idx;
}/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d){
/* Incremental rehashing already in progress. Return.*/
if (dictIsRehashing(d)) return DICT_OK; //正在rehash,返回
/* If the hash table is empty expand it to the initialsize. */
//如果ht[0]的长度为0,设置默认长度4 dictExpand为扩容的关键方法
if (d->ht[0].size == 0)
return dictExpand(d,DICT_HT_INITIAL_SIZE);
//扩容条件 hash表中已使用的数量大于等于 hash表的大小
//并且dict_can_resize为1 或者 已使用的大小大于hash表大小的 5倍,大于等于1倍的时候,下面2个满足一个条件即可
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize || d->ht[0].used/d->ht[0].size >dict_force_resize_ratio)){
//扩容成原来的2倍
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}5.3.2.1 扩容步骤
- 当满足我扩容条件,触发扩容时,判断是否在扩容,如果在扩容,或者 扩容的大小跟我现在的ht[0].size一样,这次扩容不做
- new一个新的dictht,大小为ht[0].used * 2(但是必须向上2的幂,比 如6 ,那么大小为8) ,并且ht[1]=新创建的dictht
- 我们有个更大的table了,但是需要把数据迁移到ht[1].table ,所以将 dict的rehashidx(数据迁移的偏移量)赋值为0 ,代表可以进行数据迁 移了,也就是可以rehash了
- 等待数据迁移完成,数据不会马上迁移,而是采用渐进式rehash,慢慢的把数据迁移到ht[1]
- 当数据迁移完成,ht[0].table=ht[1] ,ht[1] .table = NULL、ht[1] .size = 0、ht[1] .sizemask = 0、 ht[1] .used = 0
- 把dict的rehashidex=-1
5.3.2.2 源码验证
- dictExpand方法在_dictExpandIfNeeded 方法中调用 (dict.c文件),为扩容的关键方法
int dictExpand(dict *d, unsigned long size){
/* the size is invalid if it is smaller than the
number of
* elements already inside the hash table */
//正在扩容,不允许第二次扩容,或者ht[0]的数据量大于扩容后的数量,没有意义,这次不扩容
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n; /* the new hash table */
//得到最接近2的幂 跟hashMap思想一样
unsigned long realsize = _dictNextPower(size);
/* Rehashing to the same table size is not useful. */
//如果跟ht[0]的大小一致 直接返回错误
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all
pointers to NULL */
//为新的dictht赋值
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not
really a rehashing
* we just set the first hash table so that it can
accept keys. */
//ht[0].table为空,代表是初始化
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
//将扩容后的dictht赋值给ht[1]
d->ht[1] = n;
//标记为0,代表可以开始rehash
d->rehashidx = 0;
return DICT_OK;
}5.3.3.1 迁移方式
假如一次性把数据全部迁移会很耗时间,会让单条指令等待很久,会形成阻塞。
所以,redis采用渐进式Rehash,所谓渐进式,就是慢慢的,不会一次性把所有数据迁移。
那什么时候会进行渐进式数据迁移?
- 每次进行key的crud操作都会进行一个hash桶的数据迁移
- 定时任务,进行部分数据迁移
5.3.3.2 源码验证
CRUD触发都会触发_dictRehashStep(渐进式hash)
- 每次增删改的时候都会调用_dictRehashStep方法
if (dictIsRehashing(d)) _dictRehashStep(d); //这个代码在增删改查的方法中都会调用
- _dictRehashStep方法
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty
buckets to visit. */ //要访问的最大的空桶数 防止此次耗时过长
if (!dictIsRehashing(d)) return 0; //如果没有在rehash返回0
//循环,最多1次,并且ht[0]的数据没有迁移完 进入循环
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are
sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
//rehashidx rehash的索引,默认0 如果hash桶为空 进入自旋 并且判断是否到了最大的访问空桶数
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx]; //得到ht[0]的下标为rehashidx桶
/* Move all the keys in this bucket from the old
to the new hash HT */
while(de) { //循环hash桶的链表 并且转移到ht[1]
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d-
>ht[1].sizemask;
de->next = d->ht[1].table[h]; //头插
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
//转移完后 将ht[0]相对的hash桶设置为null
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
//ht[0].used=0 代表rehash全部完成
if (d->ht[0].used == 0) {
//清空ht[0]table
zfree(d->ht[0].table);
//将ht[0] 重新指向已经完成rehash的ht[1]
d->ht[0] = d->ht[1];
//将ht[1]所有数据重新设置
_dictReset(&d->ht[1]);
//设置-1,代表rehash完成
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
//将ht[1]的属性复位
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}再讲定时任务之前,我们要知道Redis中有个时间事件驱动,在 server.c文件下有个serverCron 方法。
serverCron 每隔多久会执行一次,执行频率根据redis.conf中的hz配置,serverCorn中有个方法databasesCron()
- 定时方法serverCron
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
//.......
/* We need to do a few operations on clients
asynchronously. */
clientsCron();
/* Handle background operations on Redis databases. */
databasesCron(); //处理Redis数据库上的后台操作。
//.......
}- databasesCron方法
void databasesCron(void) {
/* Expire keys by random sampling. Not required for
slaves
* as master will synthesize DELs for us. */
if (server.active_expire_enabled) {
if (iAmMaster()) {
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
} else {
expireSlaveKeys();
}
}
/* Defrag keys gradually. */
activeDefragCycle();
/* Perform hash tables rehashing if needed, but only
if there are no
* other processes saving the DB on disk. Otherwise
rehashing is bad
* as will cause a lot of copy-on-write of memory
pages. */
if (!hasActiveChildProcess()) {
/* We use global counters so if we stop the
computation at a given
* DB we'll be able to start from the successive
in the next
* cron loop iteration. */
static unsigned int resize_db = 0;
static unsigned int rehash_db = 0;
int dbs_per_call = CRON_DBS_PER_CALL;
int j;
/* Don't test more DBs than we have. */
if (dbs_per_call > server.dbnum)
dbs_per_call = server.dbnum;
/* Resize */
for (j = 0; j < dbs_per_call; j++) {
tryResizeHashTables(resize_db % server.dbnum);
resize_db++;
}
/* Rehash */ //Rehash逻辑
if (server.activerehashing) {
for (j = 0; j < dbs_per_call; j++) {
//进入incrementallyRehash
int work_done = incrementallyRehash(rehash_db);
if (work_done) {
/* If the function did some work, stop
here, we'll do
* more at the next cron loop. */
break;
} else {
/* If this db didn't need rehash,
we'll try the next one. */
rehash_db++;
rehash_db %= server.dbnum;
}
}
}
}
}int incrementallyRehash(int dbid) {
/* Keys dictionary */
if (dictIsRehashing(server.db[dbid].dict)) {
dictRehashMilliseconds(server.db[dbid].dict,1);
return 1;
/* already used our millisecond for this
loop... */
}
/* Expires */
if (dictIsRehashing(server.db[dbid].expires)) {
dictRehashMilliseconds(server.db[dbid].expires,1);
return 1; /* already used our millisecond for this
loop... */
}
return 0;
}- 进入dictRehashMilliseconds(dict.c)
int dictRehashMilliseconds(dict *d, int ms) {
long long start = timeInMilliseconds();
int rehashes = 0;
//进入rehash方法 dictRehash 去完成渐进时HASH
while(dictRehash(d,100)) {
rehashes += 100;
//判断是否超时
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}5.4 String类型数据结构
Redis中String的底层没有用c的char来实现,而是采用了SDS(simple Dynamic String)的数据结构来实现。并且提供了5种不同的类型
5.4.1 SDS数据结构定义(sds.h文件)
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags
byte directly.
* However is here to document the layout of type 5 SDS
strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of
string length */
char buf[];
}
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */ //已使用的长度
uint8_t alloc; /* excluding the header and null terminator */ //分配的总容量 不包含头和空终止符
unsigned char flags; /* 3 lsb of type, 5 unused bits */ //低三位类型 高5bit未使用
char buf[]; //数据buf 存储字符串数组
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null
terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits
*/
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null
terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits
*/
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null
terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits
*/
char buf[];
};- char字符串不记录自身长度,所以获取一个字符串长度的复杂度是O(n),但是SDS记录分配的长度alloc,已使用的长度len,获取长度为 O(1)
- 减少修改字符串带来的内存重分配次数
- 空间预分配,SDS长度如果小于1MB,预分配跟长度一样的,大于1M,每次跟len的大小多1M
- 惰性空间释放,截取的时候不马上释放空间,供下次使用!同时提供相应的释放SDS未使用空间的API
- 二进制安全
5.5 Hash类型数据结构
Redis的字典相当于Java语言中的HashMap,他是无序字典。内部结构上同样是数组 + 链表二维结构。第一维hash的数组位置碰撞时,就会将碰撞的元素使用链表串起来。
5.5.1 Hash数据结构图
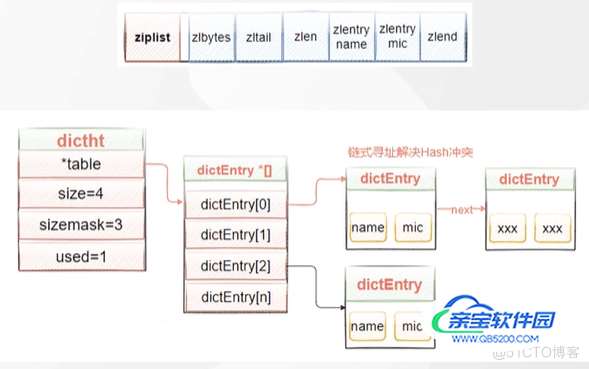
5.5.2 Hash的压缩列表
压缩列表会根据存入的数据的不同类型以及不同大小,分配不同大小的空间。所以是为了节省内存而采用的。
因为是一块完整的内存空间,当里面的元素发生变更时,会产生连锁更新,严重影响我们的访问性能。所以,只适用于数据量比较小的场景。
所以,Redis会有相关配置,Hashes只有小数据量的时候才会用到ziplist,当hash对象同时满足以下两个条件的时候,使用ziplist编码:
- 哈希对象保存的键值对数量<512个
- 所有的键值对的键和值的字符串长度都<64byte(一个英文字母一个字节)
hash-max-ziplist-value 64 // ziplist中最大能存放的值长度 hash-max-ziplist-entries 512 // ziplist中最多能存放的entry节点数量
5.6 List类型数据结构
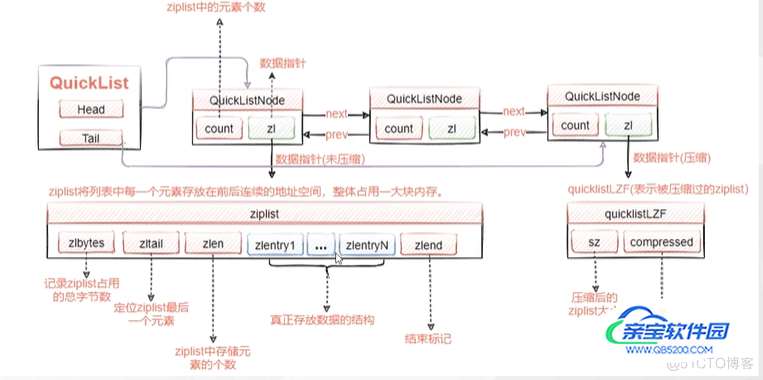
5.6.1 quickList快速列表
兼顾了ziplist的节省内存,并且一定程度上解决了连锁更新的问题,我们的 quicklistNode节点里面是个ziplist,每个节点是分开的。那么就算发生了连锁更新,也只会发生在一个quicklistNode节点。
quicklist.h文件
typedef struct{
struct quicklistNode *prev; //前指针
struct quicklistNode *next; //后指针
unsigned char *zl; //数据指针 指向ziplist结果
unsigned int sz; //ziplist大小 /* ziplist
size in bytes */
unsigned int count : 16; /* count of items in ziplist */ //ziplist的元素
unsigned int encoding : 2; /* RAW==1 or LZF==2 */ //
是否压缩, 1没有压缩 2 lzf压缩
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */ //预留容器字段
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */ //预留字段
} quicklistNode;5.6.2 list数据结构图
5.7 Set类型数据结构
Redis用intset或hashtable存储set。满足下面条件,就用inset存储。
- 如果不是整数类型,就用dictht hash表(数组+链表)
- 如果元素个数超过512个,也会用hashtable存储。跟一个配置有关:
set-max-intset-entries 512
不满足上述条件的,都使用hash表存储,value存null。
5.8 ZSet数据结构
5.8.1 ZipList
默认使用ziplist编码。
在ziplist的内部,按照score排序递增来存储。插入的时候要移动之后的数据。
如果元素数量大于等于128个,或者任一member长度大于等于64字节使用 skiplist+dict存储。
zset-max-ziplist-entries 128 zset-max-ziplist-value 64
如果不满足条件,采用跳表。
5.8.2 跳表(skiplist)
结构定义(servier.h)
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele; //sds数据
double score; //score
struct zskiplistNode *backward; //后退指针
//层级数组
struct zskiplistLevel {
struct zskiplistNode *forward; //前进指针
unsigned long span; //跨度
} level[];
} zskiplistNode;
//跳表列表
typedef struct zskiplist {
struct zskiplistNode *header, *tail; //头尾节点
unsigned long length; //节点数量
int level; //最大的节点层级
} zskiplist;zslInsert 添加节点方法 (t_zset.c)
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds
ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert
position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
咕泡出品 必属精品精品属精品 咕泡出品 必属精品 咕泡出品 必属精品 咕泡咕泡
(x->level[i].forward->score == score
&&
sdscmp(x->level[i].forward->ele,ele) <
0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since
we allow duplicated
* scores, reinserting the same element should never
happen since the
* caller of zslInsert() should test in the hash table
if the element is
* already inside or not. */
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
//不同层级建立链表联系
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is
inserted here */
x->level[i].span = update[i]->level[i].span -
(rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) +
1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL :
update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
六、Redis过期策略
6.1 惰性过期
所谓惰性过期,就是在每次访问操作key的时候,判断这个key是不是过期了,过期了就删除。
6.1.1 源码验证
- expireIfNeeded方法(db.c文件)
int expireIfNeeded(redisDb *db, robj *key) {
if (!keyIsExpired(db,key)) return 0;
/* If we are running in the context of a slave,
instead of
* evicting the expired key from the database, we
return ASAP:
* the slave key expiration is controlled by the
master that will
* send us synthesized DEL operations for expired
keys.
*
* Still we try to return the right information to the
caller,
* that is, 0 if we think the key should be still
valid, 1 if
* we think the key is expired at this time. */
// 如果配置有masterhost,说明是从节点,那么不操作删除
if (server.masterhost != NULL) return 1;
/* Delete the key */
server.stat_expiredkeys++;
propagateExpire(db,key,server.lazyfree_lazy_expire);
notifyKeyspaceEvent(NOTIFY_EXPIRED,
"expired",key,db->id);
//是否是异步删除 防止单个Key的数据量很大 阻塞主线程 是4.0之后添加的新功能,默认关闭
int retval = server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) : dbSyncDelete(db,key);
if (retval) signalModifiedKey(NULL,db,key);
return retval;
}该策略可以最大化的节省CPU资源。
但是却对内存非常不友好。因为如果没有再次访问,就可能一直堆积再内存中。占用内存
所以就需要另一种策略来配合使用,就是定期过期
6.2 定期过期
那么多久去清除一次,我们在讲Rehash的时候,有个方法是serverCron,执行频率根据redis.conf中的hz配置。
这方法除了做Rehash以外,还会做很多其他的事情,比如:
- 清理数据库中的过期键值对
- 更新服务器的各类统计信息,比如时间、内存占用、数据库占用情况等
- 关闭和清理连接失效的客户端
- 尝试进行持久化操作
6.2.1 实现流程
- 定时serverCron方法去执行清理,执行频率根据redis.cong中的hz配置的值(默认是10,也就是1s执行10次,100ms执行一次)
- 执行清理的时候,不是去扫描所有的key,而是去扫描所有设置了过期时间的key redisDB.expires
- 如果每次去把所有的key都拿出来,那么假如过期的key很多,就会很慢,所以也不是一次性拿出所有的key
- 根据hash桶的维度去扫描key,扫到20(可配置)个key为止。假如第一个桶是15个key没有满足20,继续扫描第二个桶,第二个桶20个key,由于是以hash桶的维度扫描的,所以第二个扫到了就会全扫,总共扫描35个key
- 找到扫描的key里面过期的key,并进行删除
- 如果取了400个空桶(最多拿400个桶),或者扫描的删除比例跟扫描的总数超过10%,继续执行4、5步
- 也不能无限的循环,循环16次后回去检测时间,超过指定时间会跳出
6.2.2 源码验证
- 入口serverCrom
// serverCron方法调用databasesCron方法(server.c)
/* Handle background operations on Redis databases. */
databasesCron();
void databasesCron(void) {
/* Expire keys by random sampling. Not required for
slaves
* as master will synthesize DELs for us. */
if (server.active_expire_enabled) {
if (iAmMaster()) {
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
//过期删除方法
} else {
expireSlaveKeys();
}
}
}由于Redis内存是有大小的,并且我可能里面的数据都没有过期,当快满的时候,我又没有过期的数据进行淘汰,那么这个时候内存也会满。内存满了,Redis也会不能放入新的数据。所以,我们不得已需要一些策略来解决这个问题来保证可用性。
7.1 淘汰策略
7.1.1 noeviction
New values aren’t saved when memory limit is reached. When a database uses replication, this applies to the primary database.
默认,不淘汰 能读不能写
7.1.2 allkeys-lru
Keeps most recently used keys; removes least recently used (LRU) keys
基于伪LRU算法,在所有的key中去淘汰
7.1.3 allkeys-lfu
Keeps frequently used keys; removes least frequently used (LFU) keys.
基于伪LFU算法,在所有的key中去淘汰
7.1.4 volatile-lru
Removes least recently used keys with the expire field set to true.
基于伪LRU算法,在设置了过期时间的key中去淘汰
7.1.5 volatile-lfu
Removes least frequently used keys with the expire field set to true.
基于伪LFU算法 在设置了过期时间的key中去淘汰
7.1.6 allkeys-random
Randomly removes keys to make space for the new data added.
基于随机算法,在所有的key中去淘汰
7.1.7 volatile-random
Randomly removes keys with expire field set to true.
基于随机算法 在设置了过期时间的key中去淘汰
7.1.8 volatile-ttl
Removes least frequently used keys with expire field set to true and the shortest remaining time-to-live (TTL) value.
根据过期时间来,淘汰即将过期的
7.2 淘汰流程
- 首先,我们会有个淘汰池,默认大小是16,并且里面的数据是末尾淘汰制
- 每次指令操作的时候,自旋会判断当前内存是否满足指令所需要的内存
- 如果当前不满足,会从淘汰池的尾部拿一个最适合淘汰的数据
- 会取样(配置 maxmemory-samples),从Redis中获取随机获取到取样的数据,解决一次性读取所有的数据慢的问题
- 在取样的数据中,根据淘汰算法找到最适合淘汰的数据
- 将最合适的那个数据跟淘汰池中的数据进行比较,是否比淘汰池的数据更适合淘汰,如果更适合,放入淘汰池
- 按照适合的程度进行排序,最适合淘汰的放入尾部
- 将需要淘汰的数据从Redis删除,并且从淘汰池移除
7.3 LRU算法
Lru,Least Recently Used 翻译过来是最久未使用,根据时间轴来走,仍很久没用的数据。只要最近有用过,我就默认是有效的。
那么它的一个衡量标准是啥?时间!根据使用时间,从近到远,越远的越容易淘汰。
7.3.1 实现原理
需求:得到对象隔多久没访问,隔的时间越久,越容易被淘汰
- 首先,LRU是根据这个对象的访问操作时间来进行淘汰的,那么我们需要知道这个对象最后操作的访问时间
- 知道了对象的最后操作访问时间后,我们只需要跟当前系统时间来进行对比,就能算出对象多久没访问了
7.3.2 源码验证
redis中,对象都会被redisObject对象包装,其中有个字段叫lru。
redisObject对象 (server.h文件)
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global
lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;看LRU的字段的说明,那么我们大概能猜出来,redis去实现lru淘汰算法肯定跟我们这个对象的lru相关
并且这个字段的大小为24bit,那么这个字段记录的是对象操作访问时候的秒单位时间的后24bit
相当于:
long timeMillis=System.currentTimeMillis(); System.out.println(timeMillis/1000); //获取当前秒 System.out.println(timeMillis/1000 & ((1<<24)-1)); //获取秒的后24位
我们知道了这个对象的最后操作访问的时间。如果我们要得到这个对象多久没访问了,我们是不是就很简单,用我当前的时间-这个对象的访问时间就可以了!但是这个访问时间是秒单位时间的后24bit 所以,也是用当前的时间的秒单位的后24bit去减。
estimateObjectIdleTime方法(evict.c)
unsigned long long estimateObjectIdleTime(robj *o) {
//获取秒单位时间的最后24位
unsigned long long lruclock = LRU_CLOCK();
//因为只有24位,所有最大的值为2的24次方-1
//超过最大值从0开始,所以需要判断lruclock(当前系统时间)跟缓存对象的lru字段的大小
if (lruclock >= o->lru) {
//如果lruclock>=robj.lru,返回lruclock-o->lru,再转换单位
return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;
} else {
//否则采用lruclock + (LRU_CLOCK_MAX - o->lru),得到对
象的值越小,返回的值越大,越大越容易被淘汰
return (lruclock + (LRU_CLOCK_MAX - o->lru)) *
LRU_CLOCK_RESOLUTION;
}
}7.3.3 LRU总结
用lruclock与 redisObject.lru进行比较,因为lruclock只获取了当前秒单位时间的后24位,所以肯定有个轮询。
所以,我们会用lruclock跟 redisObject.lru进行比较,如果lruclock>redisObject.lru,那么我们用lruclock- redisObject.lru,否则lruclock+(24bit的最大值-redisObject.lru),得到lru越小,那么返回的数据越大,相差越大的越优先会被淘汰!
<https://www.processon.com/view/link/5fbe0541e401fd2d6ed8fc38>
7.4 LFU算法
LFU,英文 Least Frequently Used,翻译成中文就是最不常用的优先淘汰。
不常用,它的衡量标准就是次数,次数越少的越容易被淘汰。
这个实现起来应该也很简单,对象被操作访问的时候,去记录次数,每次操作访问一次,就+1;淘汰的时候,直接去比较这个次数,次数越少的越容易淘汰!
7.4.1 LFU的时效性问题
何为时效性问题?就是只会去考虑数量,但是不会去考虑时间。
ps:去年的某个新闻很火,点击量3000W,今年有个新闻刚出来点击量100次,本来我们是想保留今年的新的新闻的,但是如果根据LFU来做的话,我们发现淘汰的是今年的新闻,明显是不合理的
导致的问题:新的数据进不去,旧的数据出不来。
那么如何解决呢,且往下看
7.4.2 源码分析
我们还是来看redisObject(server.h)
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global
lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;我们看它的lru,它如果在LFU算法的时候!它前面16位代表的是时间,后8位代表的是一个数值,frequency是频率,应该就是代表这个对象的访问次数,我们先给它叫做counter。
前16bits时间有啥用?
跟时间相关,我猜想应该是跟解决时效性相关的,那么怎么解决的?从生活中找例子
大家应该充过一些会员,比如我这个年纪的,小时候喜欢充腾讯的黄钻、绿钻、蓝钻等等。但是有一个点,假如哪天我没充钱了的话,或者没有续VIP的时候,我这个钻石等级会随着时间的流失而降低。比如我本来是黄钻V6,但是一年不充钱的话,可能就变成了V4。
那么回到Redis,大胆的去猜测,那么这个时间是不是去记录这个对象有多久没访问了,如果多久没访问,我就去减少对应的次数。
LFUDecrAndReturn方法(evict.c)
unsigned long LFUDecrAndReturn(robj *o) {
//lru字段右移8位,得到前面16位的时间
unsigned long ldt = o->lru >> 8;
//lru字段与255进行&运算(255代表8位的最大值),
//得到8位counter值
unsigned long counter = o->lru & 255;
//如果配置了lfu_decay_time,用LFUTimeElapsed(ldt) 除以配置的值
//LFUTimeElapsed(ldt)源码见下
//总的没访问的分钟时间/配置值,得到每分钟没访问衰减多少
unsigned long num_periods = server.lfu_decay_time ?LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
//不能减少为负数,非负数用couter值减去衰减值
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}衰减因子由配置
lfu-decay-time 1 //多少分钟没操作访问就去衰减一次
后8bits的次数,最大值是255,够不够?
肯定不够,一个对象的访问操作次数肯定不止255次。
但是我们可以让数据达到255的很难。那么怎么做的?这个比较简单,我们先看源码,然后再总结
LFULogIncr方法 (evict.c 文件)
uint8_t LFULogIncr(uint8_t counter) {
//如果已经到最大值255,返回255 ,8位的最大值
if (counter == 255) return 255;
//得到随机数(0-1)
double r = (double)rand()/RAND_MAX;
//LFU_INIT_VAL表示基数值(在server.h配置)
double baseval = counter - LFU_INIT_VAL;
//如果达不到基数值,表示快不行了,baseval =0
if (baseval < 0) baseval = 0;
//如果快不行了,肯定给他加counter
//不然,按照几率是否加counter,同时跟baseval与lfu_log_factor相关
//都是在分子,所以2个值越大,加counter几率越小
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}八、Redis 持久化
8.1 RBD
8.1.1 何时触发RBD
自动触发
- 配置触发
save 900 1 900s检查一次,至少有1个key被修改就触发 save 300 10 300s检查一次,至少有10个key被修改就触发 save 60 10000 60s检查一次,至少有10000个key被修改
- shutdown正常关闭
任何组件在正常关闭的时候,都会去完成应该完成的事。比如Mysql 中的Redolog持久化,正常关闭的时候也会去持久化。
- flushall指令触发
数据清空指令会触发RDB操作,并且是触发一个空的RDB文件,所以, 如果在没有开启其他的持久化的时候,flushall是可以删库跑路的,在生产环境慎用。
8.1.2 RDB的优劣
优势
- 是个非常紧凑型的文件,非常适合备份与灾难恢复
- 最大限度的提升了性能,会fork一个子进程,父进程永远不会产于磁盘 IO或者类似操作
- 更快的重启
不足
- 数据安全性不是很高,因为是根据配置的时间来备份,假如每5分钟备份 一次,也会有5分钟数据的丢失
- 经常fork子进程,所以比较耗CPU,对CPU不是很友好
8.2 AOF
由于RDB的数据可靠性非常低,所以Redis又提供了另外一种持久化方案: Append Only File 简称:AOF
AOF默认是关闭的,你可以在配置文件中进行开启:
appendonly no //默认关闭,可以进行开启 # The name of the append only file (default:"appendonly.aof") appendfilename "appendonly.aof" //AOF文件名
追加文件,即每次更改的命令都会附加到我的AOF文件中。
8.2.1 同步机制
AOF会记录每个写操作,那么问题来了。我难道每次操作命令都要和磁盘交互?
当然不行,所以redis支持几种策略,由用户来决定要不要每次都和磁盘交互
# appendfsync always 表示每次写入都执行fsync(刷新)函数 性能会非常非常慢 但是非常安全 appendfsync everysec 每秒执行一次fsync函数 可能丢失1s的数据 # appendfsync no 由操作系统保证数据同步到磁盘,速度最快 你的数据只需要交给操作系统就行
默认1s一次,最多有1s丢失
8.2.2 重写机制
由于AOF是追加的形式,所以文件会越来越大,越大的话,数据加载越慢。 所以我们需要对AOF文件进行重写。
何为重写
比如 我们的incr指令,假如我们incr了100次,现在数据是100,但是我们的aof文件中会有100条incr指令,但是我们发现这个100条指令用处不大, 假如我们能把最新的内存里的数据保存下来的话。所以,重写就是做了这么一件事情,把当前内存的数据重写下来,然后把之前的追加的文件删除。
重写流程
- 在Redis7之前
- Redis fork一个子进程,在一个临时文件中写入新的AOF(当前内存的数据生成的新的AOF)
- 那么在写入新的AOF的时候,主进程还会有指令进入,那么主进程会在内存缓存区中累计新的指令 (但是同时也会写在旧的AOF文件中,就算 重写失败,也不会导致AOF损坏或者数据丢失)
- 如果子进程重写完成,父进程会收到完成信号,并且把内存缓存中的指令追加到新的AOF文件中
- 替换旧的AOF文件 ,并且将新的指令附加到重写好的AOF文件中
- 在Redis7之后,AOF文件不再是一个,所以会有临时清单的概念
- 子进程开始在一个临时文件中写入新的基础AOF
- 父级打开一个新的增量 AOF 文件以继续写入更新。如果重写失败,旧的基础和增量文件(如果有的话)加上这个新打开的增量文件就代表了完整的更新数据集,所以我们是安全的
- 当子进程完成基础文件的重写后,父进程收到一个信号,并使用新打开 的增量文件和子进程生成的基础文件来构建临时清单,并将其持久化
- 现在 Redis 对清单文件进行原子交换,以便此 AOF 重写的结果生效。 Redis 还会清理旧的基础文件和任何未使用的增量文件
但是重写是把当前内存的数据,写入一个新的AOF文件,如果当前数据比较大,然后以指令的形式写入的话,会很慢很慢
所以在4.0之后,在重写的时候是采用RDB的方式去生成新的AOF文件,然 后后续追加的指令,还是以指令追加的形式追加的文件末尾
aof-use-rdb-preamble yes //是否开启RDB与AOF混合模式
什么时候重写
配置文件redis.conf
# 重写触发机制 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb 就算达到了第一个百分比的大小,也必须大于 64M 在 aof 文件小于64mb的时候不进行重写,当到达64mb的时候,就重写一 次。重写后的 aof 文件可能是40mb。上面配置了auto-aof-rewritepercentag为100,即 aof 文件到了80mb的时候,进行重写。
8.2.3 AOF的优势与不足
优势
- 安全性高,就算是默认的持久化同步机制,也最多只会丢失1s数据
- AOF由于某些原因,比如磁盘满了等导致追加失败,也能通过redischeck-aof 工具来修复
- 格式都是追加的日志,所以可读性更高
不足
- 数据集一般比RDB大
- 持久化跟数据加载比RDB更慢
- 在7.0之前,重写的时候,因为重写的时候,新的指令会缓存在内存区,所以会导致大量的内存使用
- 并且重写期间,会跟磁盘进行2次IO,一个是写入老的AOF文件,一个是写入新的AOF文件
九、Redis常见问题总结
9.1 Redis数据丢失场景
9.1.1 持久化丢失
采用RDB或者不持久化, 会有数据丢失,因为是手动或者配置以快照的形式来进行备份。
解决:启用AOF,以命令追加的形式进行备份,但是默认也会有1s丢失, 这是在性能与数据安全性中寻求的一个最适合的方案,如果为了保证数据 一致性,可以将配置更改为always,但是性能很慢,一般不用。
9.1.2 主从切换
因为Redis的数据是主异步同步给从的,提升了性能,但是由于是异步同步到从。所以存在数据丢失的可能
- master写入数据k1 ,由于是异步同步到slave,当master没有同步给slave的时候,master挂了
- slave会成为新的master,并且没有同步k1
- master重启,会成为新master的slave,同步数据会清空自己的数据,从新的master加载
- k1丢失
9.2 Redis缓存雪崩、穿透、击穿问题分析
9.2.1 缓存雪崩
缓存雪崩就是Redis的大量热点数据同时过期(失效),因为设置了相同的过期时间,刚好这个时候Redis请求的并发量又很大,就会导致所有的请求落到数据库。
- 保证Redis的高可用,防止由于Redis不可用导致全部打到DB
- 加互斥锁或者使用队列,针对同一个key只允许一个线程到数据库查询
- 缓存定时预先更新,避免同时失效
- 通过加随机数,使key在不同的时间过期
9.2.2 缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,但是用户一直请求不存在的数据!这时的用户很可能就是攻击者,恶意搞你们公司的,攻击会导致数据库压力过大。
解决方案:布隆过滤器
布隆过滤器的思想:既然是因为你Redis跟DB都没有,然后用户恶意一直访问不存在的key,然后全部打到Redis跟DB。那么我们能不能单独把DB的数据单独存到另外一个地方,但是这个地方只存一个简单的标记,标记这个key存不存在,如果存在,就去访问Redis跟DB,否则直接返回。并且这个内存最好很小。
9.2.3 缓存击穿
单个key过期的时候有大量并发,使用互斥锁,回写redis,并且采用双重检查锁来提升性能!减少对DB的访问。
加载全部内容
 爱之家商城
爱之家商城 氢松练
氢松练 Face甜美相机
Face甜美相机 花汇通
花汇通 走路宝正式版
走路宝正式版 天天运动有宝
天天运动有宝 深圳plus
深圳plus 热门免费小说
热门免费小说