Python基于Tensorflow2.X实现汽车油耗预测
嘟粥yyds 人气:0一、开发环境
集成开发工具:jupyter notebook 6.5.2
集成开发环境:Python 3.10.6
第三方库:tensorflow-gpu、numpy、matplotlib.pyplot、pandas
二 、代码实现
2.1 准备操作
2.1.1 导入所需模块
tensorflow若非GPU版本也可
import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers, datasets, losses import numpy as np import pandas as pd import matplotlib.pyplot as plt
2.1.2 matplotlib无法正常显示中文的解决方案(若无此情况可跳过)
博主由于已在matplotlib的配置文件中做了一系列修改,故可以正常显示中文,若出现无法正常显示中文的情况有以下两种解决方案:
1、在导入模块后加上下列两行代码(每次需要正常显示中文时都需要加):
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
2、在matplotlib的源文件中做了一系列修改(一劳永逸)
运行下列代码
import matplotlib print(matplotlib.matplotlib_fname())
会输出配置文件路径,如:(进入python配置目录因人而异,只需从\LocalCache之后开始关注)
C:\Users\31600\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\matplotlib\mpl-data\matplotlibrc
打开此文件,找到#font.family:和#font.sans-serif:开头的这两行,将两行的注释#去掉,并在font.sans-serif:后添加自己想加入的中文字体名,如:(博主选用的打开方式为visual studio2017,不同的打开方式显示可能略有不同另博主打开演示前已完成去注释操作)
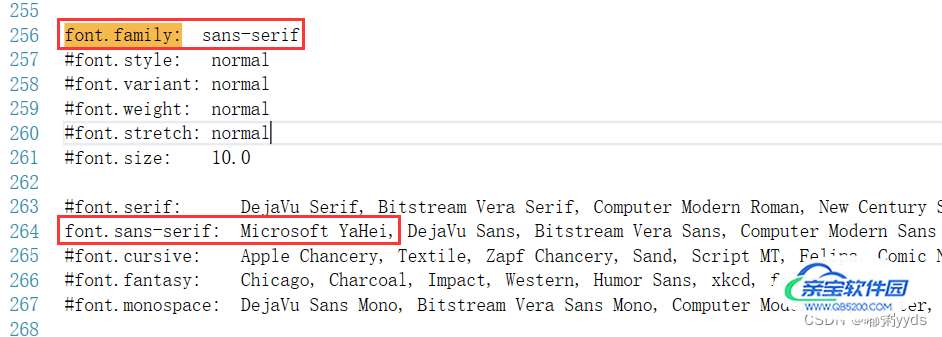
最后保存文件,重新运行python环境即可,不必在代码中做出任何修改。
2.2 加载数据集
# 在线下载汽车效能数据集
dataset_path = keras.utils.get_file("auto-mpg.data",
"http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
# 字段有效能(公里数每加仑) 气缸数 排量 马力 重量 加速度 型号年份 产地
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
各字段含义

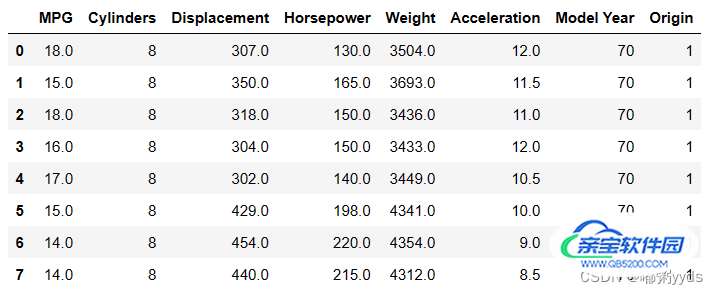
dataset = raw_dataset.copy() # 查看部分数据 dataset.head(8)
2.3 数据处理
2.3.1 数据清洗
原始数据可能含有空字段(缺失值)的数据项
isna()会返回为包含无效值的表单,再追加一个sum()实现计算无效值的和;其次,对无效数据进行处理;dropna()清除无效数据后返回一个新数据表单;
begin = dataset.isna().sum() # 统计空白数据
dataset = dataset.dropna() # 删除空白数据项
end = dataset.isna().sum() # 再次统计空白数据
print(f'========统计前:========\n{begin}\n========统计后:========\n{end}')
# 输出结果:
========统计前:========
MPG 0
Cylinders 0
Displacement 0
Horsepower 6
Weight 0
Acceleration 0
Model Year 0
Origin 0
dtype: int64
========统计后:========
MPG 0
Cylinders 0
Displacement 0
Horsepower 0
Weight 0
Acceleration 0
Model Year 0
Origin 0
dtype: int642.3.2 数据转换
由于Origin字段为类型数据,我们将其移除,并转换为新的3个字段:USA、Europe和Japan。(原数据里分别对应1、2、3)
将需要的产源地分类序号从表中提取出来,使用pop(‘Origin’)提取Origin列的数据,将Origin进行one-hot转换——即Origin不同的值仅对应一个数据有效;
# 先弹出(删除并返回)Origin这一列
origin = dataset.pop('Origin')
# 根据origin列的数据来写入新的3个列
dataset['USA'] = (origin == 1) * 1.0
dataset['Europe'] = (origin == 2) * 1.0
dataset['Japan'] = (origin == 3) * 1.0
dataset.tail()
转换后的数据为:

2.3.3 数据集划分
利用sample()函数将数据集拆分为0.8的数据集和0.2的测试集,并且移除已经取出的数据下标包含的数据并返回作为测试集
# 切分为训练集和测试集 train_dataset = dataset.sample(frac=0.8, random_state=0) test_dataset = dataset.drop(train_dataset.index)
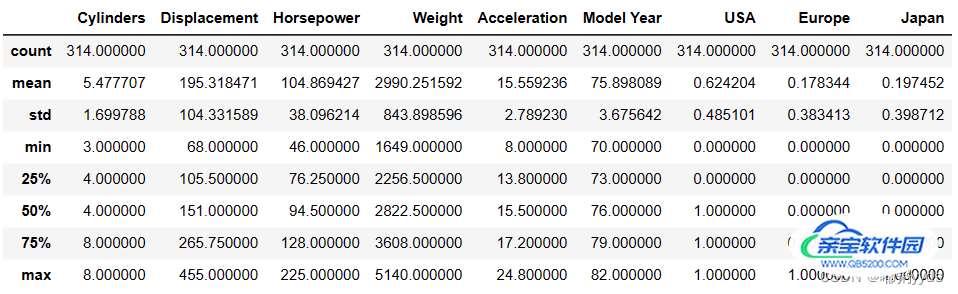
describe()用于观察一系列数据的范围,统计训练集的各个字段数值的均值和标准差,大小、波动趋势等。从获得的数据中获得训练数据的标签,即移除的MPG列数据
# 查看训练集的输入x的统计数据 train_stats = train_dataset.describe() train_stats = train_stats.transpose() # 转置 train_stats
2.3.4 真实值设定
将MPG字段移除为标签数据
# 移动MPG油耗效能这一列为真实标签Y
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
2.3.5 标准化数据
统计训练集的各个字段数值的均值和标准差,并完成数据的标准化
# 标准化数据
def norm(x):
# 减去每个字段的均值并除以标准差
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset) # 标准化训练集
normed_test_data = norm(test_dataset) # 标准化测试集
print(f'训练集大小:{normed_train_data.shape} {train_labels.shape}')
print(f"测试集大小:{normed_test_data.shape} {test_labels.shape}")
normed_train_data # 查看数据处理后的训练集
# 利用切分的训练集构建数据集对象
train_db = tf.data.Dataset.from_tensor_slices((normed_train_data.values, train_labels.values)) # 构建Dataset对象
# 为防止数据标准化后出现梯度弥散,切分训练集,分为几个batch,加速计算
train_db = train_db.shuffle(100).batch(32) # 随机打散,批量化
# 输出结果:
训练集大小:(314, 9) (314,)
测试集大小:(78, 9) (78,)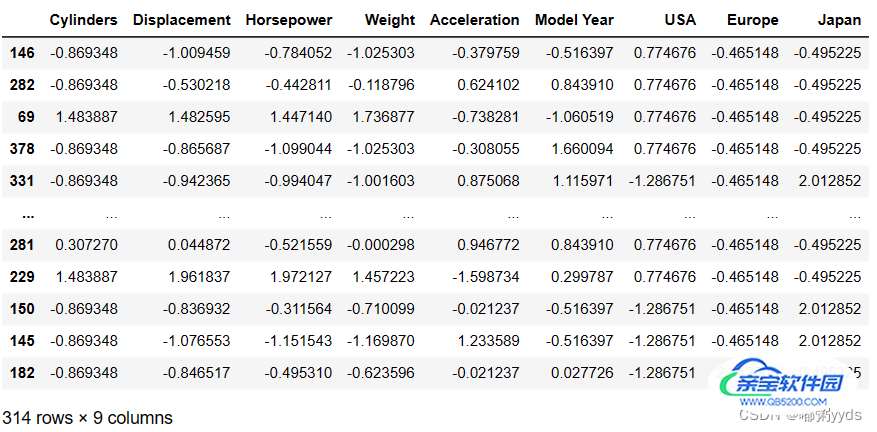
2.3.6 查看各字段对MPG的影响
# 创建同y轴的上下三联图,需要plt.subplots()
fig, axes = plt.subplots(nrows=1,ncols=3,sharey=True,figsize=(20,6))
fig.suptitle('各个字段对MPG的影响', fontsize=16)
#subplot1
axes[0].scatter(train_dataset['Cylinders'].to_numpy(), train_labels.to_numpy(), color='b',s=20)
axes[0].set_xlabel('Cylinders', fontsize=13)
axes[0].set_ylabel('MPG', fontsize=14)
#subplot2
axes[1].scatter(train_dataset['Displacement'].to_numpy(), train_labels.to_numpy(), color='b',s=20)
axes[1].set_xlabel('Displacement', fontsize=13)
#subplot3
axes[2].scatter(train_dataset['Weight'].to_numpy(), train_labels.to_numpy(), color='b',s=20)
axes[2].set_xlabel('Weight', fontsize=13)
#展示图片
plt.show()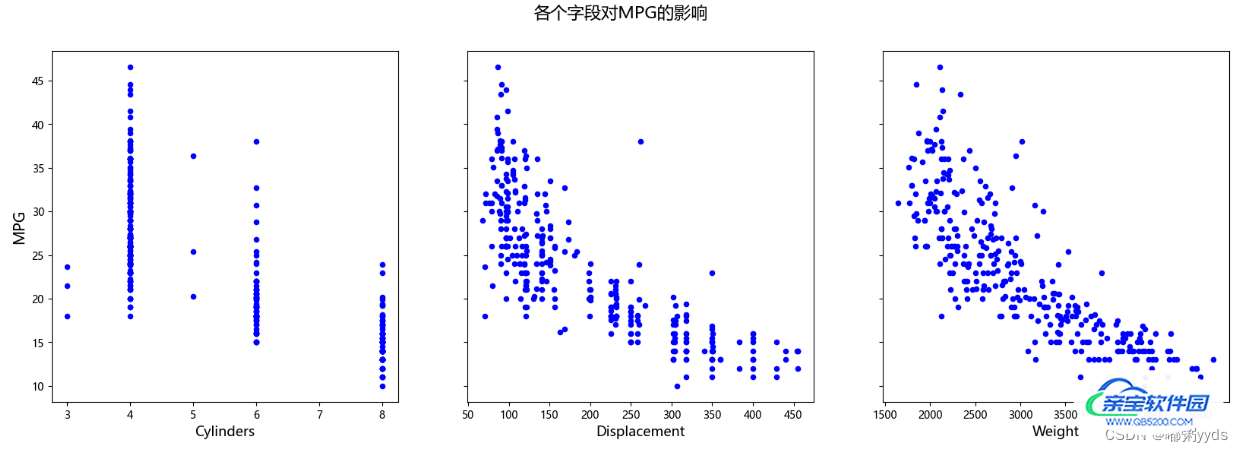
2.4 创建网络
因为该数据集比较小,我们只创建一个3层的全连接网络来完成MPG值的预测任务。 我们将网络实现为一个自定义网络类,只需要在初始化函数中创建各个子网络层,并在前向计算函数 call 中实现自定义网络类的计算逻辑即可。自定义网络类继承自 keras.Model 基类,这也是自定义网络类的标准写法,以方便地利用 keras.Model 基类提供 的 trainable_variables、save_weights 等各种便捷功能。
class Network(keras.Model):
# 回归网络模型
def __init__(self):
super(Network, self).__init__()
# 创建3个全连接层
self.fc1 = layers.Dense(64, activation='relu', name='Layer1')
self.fc2 = layers.Dense(64, activation='relu', name='Layer2')
self.fc3 = layers.Dense(1, name='OutputLayer')
def call(self, inputs, training=None, mask=None):
# 依次通过3个全连接层
x = self.fc1(inputs)
x = self.fc2(x)
x = self.fc3(x)
return x2.5 训练与测试
在训练网络时,一般的流程是通过前向计算获得网络的输出值, 再通过损失函数计算网络误差,然后通过自动求导工具计算梯度并更新,同时间隔性地测试网络的性能。
所以,在完成网络模型的搭建后,需要指定网络使用的优化器对象、 损失函数类型, 评价指标等设定,这一步称为装配。这里只指定网络使用的优化器对象,损失函数在梯度求导时在指定
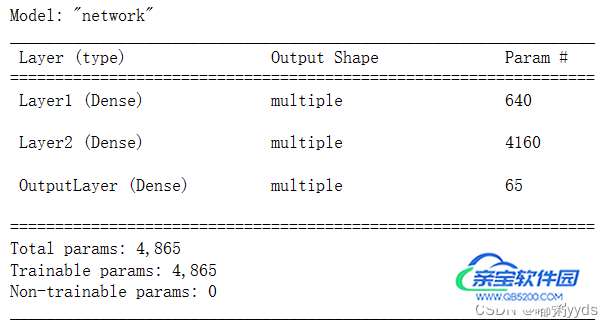
# 创建网络类实例 model = Network() # 通过build函数完成内部张量的创建(其中4为任意设置的batch量,9为输入特征长度) model.build(input_shape=(4, 9)) # 打印网络信息 model.summary() # 创建优化器,指定学习率为0.001 optimizers = tf.keras.optimizers.RMSprop(0.001)
# 接下来实现网络训练部分。通过 Epoch 和 Step 组成的双层循环训练网络,共训练 200 个 Epoch
Epoch = np.arange(0, 200)
train_MAE = np.zeros(200)
test_MAE = np.zeros(200)
for epoch in range(200):
for step, (x, y) in enumerate(train_db): # 遍历依次训练集
# 梯度记录器
with tf.GradientTape() as tape:
out = model(x) # 通过网络获得输出
loss = tf.reduce_mean(losses.MSE(y, out))
mae_loss = tf.reduce_mean(losses.MAE(y, out)) # 计算 MAE
# 计算梯度并更新
grads = tape.gradient(loss, model.trainable_variables)
Optimizers.apply_gradients(zip(grads, model.trainable_variables))
train_MAE[epoch] = float(mae_loss)
out = model(tf.constant(normed_test_data.values))
test_MAE[epoch] = tf.reduce_mean(losses.MAE(test_labels, out))2.6 误差结果可视化
对于回归问题,除了 MSE 均方差可以用来模型的测试性能,还可以用平均绝对误差(Mean Absolute Error,简称 MAE)来衡量模型的性能,程序运算时记录每个 Epoch 结束时的训练和测试 MAE 数据,并绘制变化曲线
plt.xlabel('Epoch')
plt.ylabel('MAE')
plt.plot(Epoch, train_MAE, label="Train")
plt.plot(Epoch, test_MAE, label="Test")
plt.title('汽车油耗实战')
plt.legend(['Train', 'Test']) # 设置折线名称
plt.show()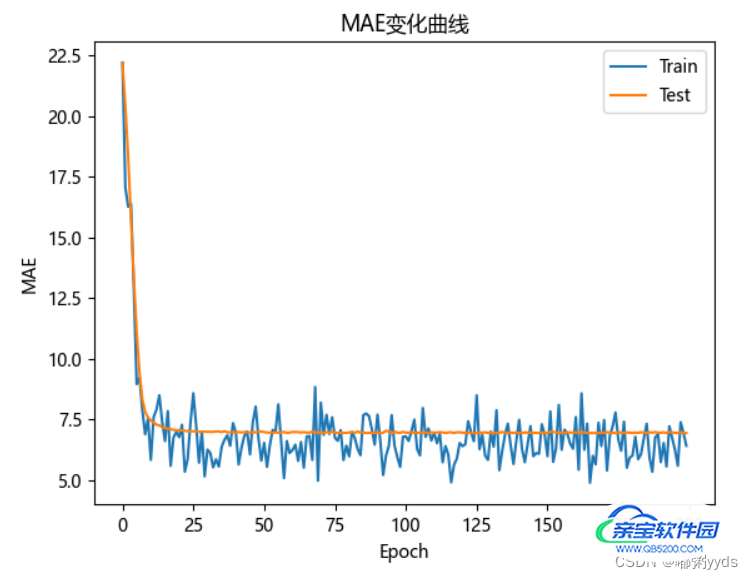
三 、结果分析
可以观察到,在训练到约第 25 个 Epoch 时, MAE 的下降变得较缓慢,其中训练集的 MAE
还在继续不断波动,但是测试集 MAE 几乎保持不变,因此可以在约第 25 个 epoch 时提前结束训练,并利用此时的网络参数来预测新的输入样本即可。
加载全部内容