springboot执行延时任务之DelayQueue实例
且行且珍惜_ 人气:0springboot执行延时任务之DelayQueue
提示:下面案例可供参考
DelayQueue是什么?
DelayQueue提供了在指定时间才能获取队列元素的功能,队列头元素是最接近过期的元素。
没有过期元素的话,使用poll()方法会返回null值,超时判定是通过getDelay(TimeUnit.NANOSECONDS)方法的返回值小于等于0来判断。
延时队列不能存放空元素。
一般使用take()方法阻塞等待,有过期元素时继续。
使用步骤
1.队列中的元素–DelayTask
代码如下(示例):
import java.util.Date;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
/**
* @author
* @Time 2020/11/23 10:53
* @description: DelayTask延时任务队列中元素
*/
public class DelayTask implements Delayed {
final private HotelRabbitMq data;
final private long expire;
/**
* 构造延时任务
* @param data 业务数据
* @param expire 任务延时时间(ms)
*/
public DelayTask(xx data, long expire) {
super();
this.data = data;
this.expire = expire + System.currentTimeMillis();
}
public HotelRabbitMq getData() {
return data;
}
public long getExpire() {
return expire;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof DelayTask) {
return this.data.getIdentifier().equals(((DelayTask) obj).getData().getIdentifier());
}
return false;
}
@Override
public String toString() {
return "{" + "data:" + data.toString() + "," + "expire:" + new Date(expire) + "}";
}
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(this.expire - System.currentTimeMillis(), unit);
}
@Override
public int compareTo(Delayed o) {
long delta = getDelay(TimeUnit.NANOSECONDS) - o.getDelay(TimeUnit.NANOSECONDS);
return (int) delta;
}
}
2.用户自定义的业务数据基类
TaskBase类是用户自定义的业务数据基类,其中有一个identifier字段来标识任务的id,方便进行索引
代码如下(示例):
xx 类按自己需求定义
3.定义延时任务管理类DelayQueueManager
定义一个延时任务管理类DelayQueueManager,通过@Component注解加入到spring中管理,在需要使用的地方通过@Autowire注入
代码如下(示例):
import com.alibaba.fastjson.JSON;
import org.fh.config.RabbitProducer;
import org.fh.entity.dyne.HotelRabbitMq;
import org.fh.entity.dyne.HotelRegister;
import org.fh.entity.util.TaskBase;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.Executors;
/**
* @author
* @Time 2020/11/23 10:59
* @description: DelayQueueManager延时任务管理类
*/
@Component
public class DelayQueueManager implements CommandLineRunner {
@Autowired
RabbitProducer rabbitProducer;
private final Logger logger = LoggerFactory.getLogger(DelayQueueManager.class);
private DelayQueue<DelayTask> delayQueue = new DelayQueue<>();
/**
* 加入到延时队列中
* @param task
*/
public void put(DelayTask task) {
logger.info("加入延时任务:{}", task);
delayQueue.put(task);
}
/**
* 取消延时任务
* @param task
* @return
*/
public boolean remove(DelayTask task) {
logger.info("取消延时任务:{}", task);
return delayQueue.remove(task);
}
/**
* 取消延时任务
* @param taskid
* @return
*/
public boolean remove(String taskid) {
return remove(new DelayTask(new HotelRabbitMq(taskid), 0));
}
@Override
public void run(String... args) throws Exception {
logger.info("初始化延时队列");
Executors.newSingleThreadExecutor().execute(new Thread(this::excuteThread));
}
/**
* 延时任务执行线程
*/
private void excuteThread() {
while (true) {
try {
DelayTask task = delayQueue.take();
processTask(task);
} catch (InterruptedException e) {
break;
}
}
}
/**
* 内部执行延时任务
* @param task
*/
private void processTask(DelayTask task) {
logger.info("执行延时任务:{}", task);
//根据task中的data自定义数据来处理相关逻辑,例 if (task.getData() instanceof XXX) {}
//发送rabbitmq
//rabbitProducer.sendDemoQueue(task.getData());
}
public void put(HotelRegister hotelRegister, int i) {
}
}
日常开发延迟任务
在开发中,往往会遇到一些关于延时任务的需求。例如
- 生成订单30分钟未支付,则自动取消
- 生成订单60秒后,给用户发短信
对上述的任务,我们给一个专业的名字来形容,那就是延时任务。延时任务属于定时任务的一种,不同于一般的定时任务,延时任务是在某事件触发后的未来某个时刻执行,没有重复的执行周期。
技术对比
1.DelayQueue
JDK自带DelayQueue是支持延时获取元素的阻塞队列,内部采用优先队列PriorityQueue 存储元素,同时元素必须实现 Delayed 接口
创建元素时可以指定多久才可以从队列中获取当前队列中获取当前元素,只有当延迟期满时才能从队列中提取元素

DelayQueue属于排序队列,它的特殊之处在于队列的元素必须实现Delayed接口,该接口需要实现compareTo和getDelay方法
getDelay方法:获取元素在队列中的剩余时间,只有当剩余时间为0时元素才可以出队列。compareTo方法:用于排序,确定元素出队列的顺序。
在springboot中的实现
1:在测试包jdk下创建延迟任务元素对象DelayedTask,实现compareTo和getDelay方法,
2:在main方法中创建DelayQueue并向延迟队列中添加三个延迟任务,
3:循环的从延迟队列中拉取任务
public class DelayedTask implements Delayed{
// 任务的执行时间
private int executeTime = 0;
public DelayedTask(int delay){
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.SECOND,delay);
this.executeTime = (int)(calendar.getTimeInMillis() /1000 );
}
/**
* 元素在队列中的剩余时间
* @param unit
* @return
*/
@Override
public long getDelay(TimeUnit unit) {
Calendar calendar = Calendar.getInstance();
return executeTime - (calendar.getTimeInMillis()/1000);
}
/**
* 元素排序
* @param o
* @return
*/
@Override
public int compareTo(Delayed o) {
long val = this.getDelay(TimeUnit.NANOSECONDS) - o.getDelay(TimeUnit.NANOSECONDS);
return val == 0 ? 0 : ( val < 0 ? -1: 1 );
}
public static void main(String[] args) {
DelayQueue<DelayedTask> queue = new DelayQueue<DelayedTask>();
queue.add(new DelayedTask(5));
queue.add(new DelayedTask(10));
queue.add(new DelayedTask(15));
System.out.println(System.currentTimeMillis()/1000+" start consume ");
while(queue.size() != 0){
DelayedTask delayedTask = queue.poll();
if(delayedTask !=null ){
System.out.println(System.currentTimeMillis()/1000+" cosume task");
}
//每隔一秒消费一次
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}使用DelayQueue的问题:
- 1.都是在内存中运行,如果宕机,数据全部消失
- 2.集群扩展相当麻烦
- 3.占用大量内存,影响性能
- 4.代码复杂度高
2.DB轮询
数据库方案
将任务存在数据库中,然后使用定时器轮询
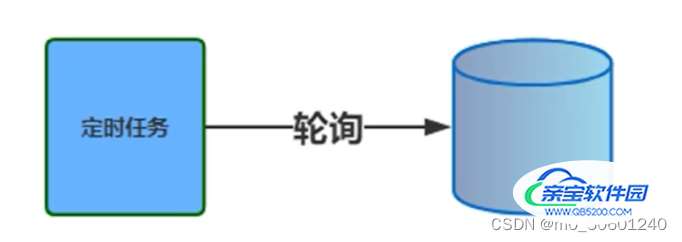
不足:小型系统如果只有几万任务,采用上述方案即可。如果大规模系统,任务量过大,对数据库造成的压力很大 。频繁查询数据库带来性能影响
3.数据库+缓存(redis)实现
zset数据类型的去重有序(分数排序)特点进行延迟
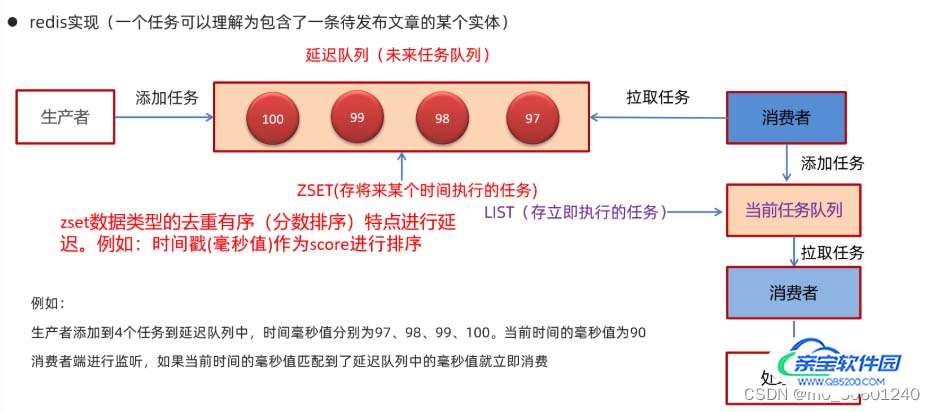
实现流程
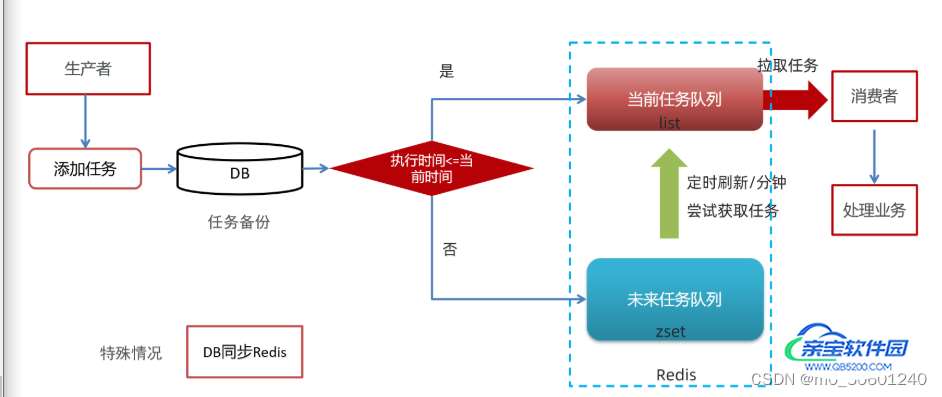
特殊情况:如果redis宕机导致数据无法恢复,那么需要有一种机制在系统启动后,重新加载全部未处理的任务到Cache中,此方案作为应急补充方案
问题思路:
为什么将任务放在数据库中?
延迟任务是一个通用的服务,任何需要延迟的任务都可以调用该任务,需要考虑数据持久化问题,存储数据库中是一种数据安全的考虑(备份机制)
为什么redis中使用两种数据类型,list和zset? 效率问题,算法的时间复杂度
zset还做了那些优化:不同任务不同key,进一步优化
未来任务定时刷新支持:
启动类上添加@EnableScheduling注解,开启任务调度
执行方法上添加
@Scheduled(cron = "0 */1 * * * ?") 每一分钟执行一次
redis key值匹配
方案1:keys模糊匹配
keys的模糊匹配功能很方便也很强大,但是在生产环境需要慎用!开发中使用keys的模糊匹配却发现redis的CPU使用率极高,所以公司的redis生产环境将keys命令禁用了!redis是单线程,会被堵塞
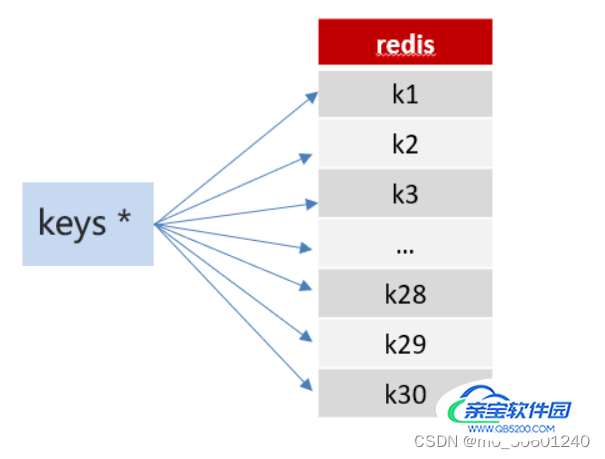
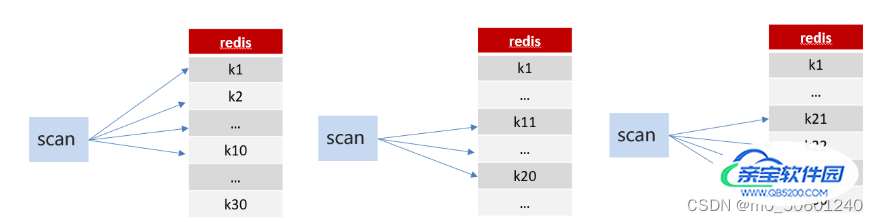
方案2:scan
SCAN 命令是一个基于游标的迭代器,SCAN命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为SCAN命令的游标参数, 以此来延续之前的迭代过程。
- 分布式锁:解决任务重复执行的问题,控制分布式系统有序的去对共享资源进行操作,通过互斥来保证数据的一致性。
- DB同步任务:当redis宕机数据丢失的时候,在系统启动时执行一次
- DB同步任务逻辑:同步方法上添加@PostConstruct注解,1.删除全部未来队列数据 2.删除全部当前队列数据 3.从任务日志表查询待执行任务 4.遍历任务添加到缓存
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容