DolphinScheduler容错Master源码分析
leo的跟班 人气:0引言
最近产品上选择使用DolphinScheduler作为大数据的任务调度系统。作为分布式调度系统DolphinScheduler采用了去中心化的多Master和多Worker服务对等架构,可以避免单Master压力过大。在这种架构下,如果一个Master或者Worker挂掉,那么相应的容错处理则必不可少。下面会介绍其具体容错处理的方式以及相关源码的分析。
容错设计
详细的设计结构我们可以参考官方文档。
服务容错设计依赖于ZooKeeper的Watcher机制,Master会监控其他Master和Worker的目录,如果监听到remove事件,则会根据具体的业务逻辑进行流程实例容错或者任务实例容错。
Zookeeper中主要的目录名称如下,这里先简单了解一下,后面源码中会一一使用到:
public static final String REGISTRY_DOLPHINSCHEDULER_MASTERS = "/nodes/master"; public static final String REGISTRY_DOLPHINSCHEDULER_WORKERS = "/nodes/worker"; public static final String REGISTRY_DOLPHINSCHEDULER_NODE = "/nodes";
官方架构图:
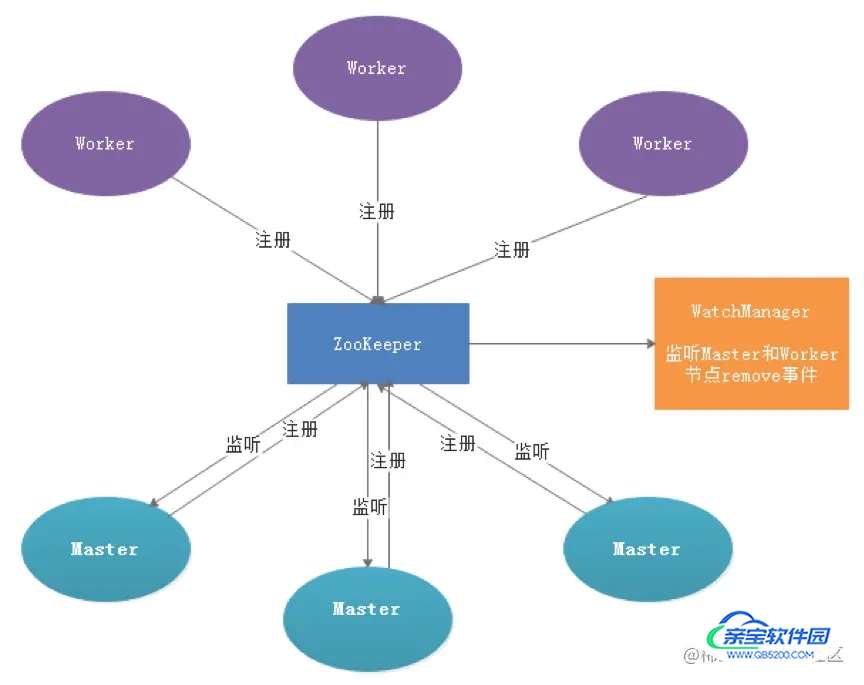
Master容错源码分析
Master启动入口
MasterServer的run方法中会有容错的入口:
@PostConstruct
public void run() throws SchedulerException {
// init rpc server
this.masterRPCServer.start();
// install task plugin
this.taskPluginManager.loadPlugin();
// self tolerant
this.masterRegistryClient.start();
this.masterRegistryClient.setRegistryStoppable(this);
this.masterSchedulerBootstrap.init();
this.masterSchedulerBootstrap.start();
this.eventExecuteService.start();
this.failoverExecuteThread.start();
this.schedulerApi.start();
......
}
Master的启动主要有几个步骤:
基于netty的rpc服务端启动、任务插件的加载、容错代码的初始化、任务调度的初始化、任务事件处理线程的启动。
这里我们只关心容错相关的代码 masterRegistryClient.start():
public void start() {
try {
this.masterHeartBeatTask = new MasterHeartBeatTask(masterConfig, registryClient);
// master registry
registry();
registryClient.addConnectionStateListener(
new MasterConnectionStateListener(masterConfig, registryClient, masterConnectStrategy));
registryClient.subscribe(REGISTRY_DOLPHINSCHEDULER_NODE, new MasterRegistryDataListener());
} catch (Exception e) {
throw new RegistryException("Master registry client start up error", e);
}
}
在上面的start方法中主要做了三件事,我们一个个来看。
Master启动注册信息
注册当前master信息到Zookeeper,并且启动了一个心跳任务定时更新master的信息到Zookeeper。
/**
* Registry the current master server itself to registry.
*/
void registry() {
logger.info("Master node : {} registering to registry center", masterConfig.getMasterAddress());
String masterRegistryPath = masterConfig.getMasterRegistryPath();
// remove before persist
registryClient.remove(masterRegistryPath);
registryClient.persistEphemeral(masterRegistryPath, JSONUtils.toJsonString(masterHeartBeatTask.getHeartBeat()));
while (!registryClient.checkNodeExists(NetUtils.getHost(), NodeType.MASTER)) {
logger.warn("The current master server node:{} cannot find in registry", NetUtils.getHost());
ThreadUtils.sleep(SLEEP_TIME_MILLIS);
}
// sleep 1s, waiting master failover remove
ThreadUtils.sleep(SLEEP_TIME_MILLIS);
masterHeartBeatTask.start();
logger.info("Master node : {} registered to registry center successfully", masterConfig.getMasterAddress());
}
master在ZK注册的路径如下:
masterConfig.setMasterAddress(NetUtils.getAddr(masterConfig.getListenPort())); //nodes/master+ "/" +ip:listenPort masterConfig.setMasterRegistryPath(REGISTRY_DOLPHINSCHEDULER_MASTERS + "/" + masterConfig.getMasterAddress());
注册的信息主要是Master自身的健康状态如下,并且会定时更新:
@Override
public MasterHeartBeat getHeartBeat() {
return MasterHeartBeat.builder()
.startupTime(ServerLifeCycleManager.getServerStartupTime())
.reportTime(System.currentTimeMillis())
.cpuUsage(OSUtils.cpuUsage())
.loadAverage(OSUtils.loadAverage())
.availablePhysicalMemorySize(OSUtils.availablePhysicalMemorySize())
.maxCpuloadAvg(masterConfig.getMaxCpuLoadAvg())
.reservedMemory(masterConfig.getReservedMemory())
.memoryUsage(OSUtils.memoryUsage())
.diskAvailable(OSUtils.diskAvailable())
.processId(processId)
.build();
}
Master监听和订阅集群状态
监听zk客户端与集群连接的状态变化
@Override
public void addConnectionStateListener(ConnectionListener listener) {
client.getConnectionStateListenable().addListener(new ZookeeperConnectionStateListener(listener));
}
当客户端和服务端因为某些原因重连后会调用MasterConnectionStateListener相关的监听事件处理:
@Override
public void onUpdate(ConnectionState state) {
logger.info("Master received a {} event from registry, the current server state is {}", state,
ServerLifeCycleManager.getServerStatus());
switch (state) {
case CONNECTED:
break;
case SUSPENDED:
break;
case RECONNECTED:
masterConnectStrategy.reconnect();
break;
case DISCONNECTED:
masterConnectStrategy.disconnect();
break;
default:
}
}
订阅Master、Worker注册目录顶级目录/nodes相关的事件,这里主要订阅Remove事件。
registryClient.subscribe(REGISTRY_DOLPHINSCHEDULER_NODE, new MasterRegistryDataListener());
@Override
public boolean subscribe(String path, SubscribeListener listener) {
final TreeCache treeCache = treeCacheMap.computeIfAbsent(path, $ -> new TreeCache(client, path));
treeCache.getListenable().addListener(($, event) -> listener.notify(new EventAdaptor(event, path)));
try {
treeCache.start();
} catch (Exception e) {
treeCacheMap.remove(path);
throw new RegistryException("Failed to subscribe listener for key: " + path, e);
}
return true;
}
这里是基于curator客户端中的TreeCache来实现订阅,它允许对ZK中某个路径的数据和路径变更以及其下所有子孙节点的数据和路径变更进行监听。ZK监听数据变化后最终会回调到MasterRegistryDataListener中的notify方法:
public void notify(Event event) {
//这里的path就是/node目录下发生变化的path信息,可能是/nodes/master/**或者/nodes/worker/**
final String path = event.path();
if (Strings.isNullOrEmpty(path)) {
return;
}
//monitor master
if (path.startsWith(REGISTRY_DOLPHINSCHEDULER_MASTERS + Constants.SINGLE_SLASH)) {
handleMasterEvent(event);
} else if (path.startsWith(REGISTRY_DOLPHINSCHEDULER_WORKERS + Constants.SINGLE_SLASH)) {
//monitor worker
handleWorkerEvent(event);
}
}
在notify中会针对ZK中/nodes/master/或者/nodes/worker/ 路径的变动做不同的处理。
Master容错流程
这里先来看一下当ZK中/nodes/master/路径下发生了变动之后做了哪些事情:
private void handleMasterEvent(Event event) {
final String path = event.path();
switch (event.type()) {
case ADD:
logger.info("master node added : {}", path);
break;
case REMOVE:
masterRegistryClient.removeMasterNodePath(path, NodeType.MASTER, true);
break;
default:
break;
}
}
如果ZK监听到有master node path被删除,则说明有master节点异常,此时需要对其上面的任务进行容错。
public void removeMasterNodePath(String path, NodeType nodeType, boolean failover) {
logger.info("{} node deleted : {}", nodeType, path);
if (StringUtils.isEmpty(path)) {
logger.error("server down error: empty path: {}, nodeType:{}", path, nodeType);
return;
}
//获取异常节点的ip:port
String serverHost = registryClient.getHostByEventDataPath(path);
if (StringUtils.isEmpty(serverHost)) {
logger.error("server down error: unknown path: {}, nodeType:{}", path, nodeType);
return;
}
try {
if (!registryClient.exists(path)) {
logger.info("path: {} not exists", path);
}
// failover server
if (failover) {
failoverService.failoverServerWhenDown(serverHost, nodeType);
}
} catch (Exception e) {
logger.error("{} server failover failed, host:{}", nodeType, serverHost, e);
}
}
/**
* failover server when server down
*
* @param serverHost server host
* @param nodeType node type
*/
public void failoverServerWhenDown(String serverHost, NodeType nodeType) {
switch (nodeType) {
case MASTER:
LOGGER.info("Master failover starting, masterServer: {}", serverHost);
masterFailoverService.failoverMaster(serverHost);
LOGGER.info("Master failover finished, masterServer: {}", serverHost);
break;
case WORKER:
LOGGER.info("Worker failover staring, workerServer: {}", serverHost);
workerFailoverService.failoverWorker(serverHost);
LOGGER.info("Worker failover finished, workerServer: {}", serverHost);
break;
default:
break;
}
}
Master的容错最终会调用masterFailoverService.failoverMaster(serverHost);这里的serverHost就是异常Master节点的ip:port信息。
因为这里可能会有多个Master监听到异常Master节点挂掉的事件,所以会先拿到分布式锁然后进行容错的操作,拿到锁的Master会开始进行容错:
public void failoverMaster(String masterHost) {
String failoverPath = Constants.REGISTRY_DOLPHINSCHEDULER_LOCK_FAILOVER_MASTERS + "/" + masterHost;
try {
registryClient.getLock(failoverPath);
doFailoverMaster(masterHost);
} catch (Exception e) {
LOGGER.error("Master server failover failed, host:{}", masterHost, e);
} finally {
registryClient.releaseLock(failoverPath);
}
}
整个容错的过程大致如下:
Failover master, will failover process instance and associated task instance. When the process instance belongs to the given masterHost and the restartTime is before the current server start up time,then the process instance will be failovered.
1-首先会会根据异常节点的masterHost去DB中查询出所有需要容错的工作流实例和任务实例。
2-其次会比较工作流实例启动时间和当前masterHost节点启动时间,在服务启动时间之后的则跳过容错。如果当前节点还没有重新启动,那么就需要容错所有的实例。
3-变量工作流实例下所有的任务实例,进行容错处理
4-将工作流实例的Host更新为NULL,并且新增RECOVER_TOLERANCE_FAULT_PROCESS类型的Command到command表中。
private void doFailoverMaster(@NonNull String masterHost) {
StopWatch failoverTimeCost = StopWatch.createStarted();
Optional<Date> masterStartupTimeOptional = getServerStartupTime(registryClient.getServerList(NodeType.MASTER),
masterHost);
//1-根据 异常节点的masterHost查询所有工作流实例
List<ProcessInstance> needFailoverProcessInstanceList = processService.queryNeedFailoverProcessInstances(
masterHost);
if (CollectionUtils.isEmpty(needFailoverProcessInstanceList)) {
return;
}
LOGGER.info(
"Master[{}] failover starting there are {} workflowInstance may need to failover, will do a deep check, workflowInstanceIds: {}",
masterHost,
needFailoverProcessInstanceList.size(),
needFailoverProcessInstanceList.stream().map(ProcessInstance::getId).collect(Collectors.toList()));
for (ProcessInstance processInstance : needFailoverProcessInstanceList) {
try {
LoggerUtils.setWorkflowInstanceIdMDC(processInstance.getId());
LOGGER.info("WorkflowInstance failover starting");
//2-校验工作流实例启动时间是否满足容错条件
if (!checkProcessInstanceNeedFailover(masterStartupTimeOptional, processInstance)) {
LOGGER.info("WorkflowInstance doesn't need to failover");
continue;
}
// todo: use batch query
ProcessDefinition processDefinition =
processService.findProcessDefinition(processInstance.getProcessDefinitionCode(),
processInstance.getProcessDefinitionVersion());
processInstance.setProcessDefinition(processDefinition);
int processInstanceId = processInstance.getId();
List<TaskInstance> taskInstanceList =
processService.findValidTaskListByProcessId(processInstanceId);
//3-对任务实例进行容错,具体在failoverTaskInstance方法中
for (TaskInstance taskInstance : taskInstanceList) {
try {
LoggerUtils.setTaskInstanceIdMDC(taskInstance.getId());
LOGGER.info("TaskInstance failover starting");
if (!checkTaskInstanceNeedFailover(taskInstance)) {
LOGGER.info("The taskInstance doesn't need to failover");
continue;
}
failoverTaskInstance(processInstance, taskInstance);
LOGGER.info("TaskInstance failover finished");
} finally {
LoggerUtils.removeTaskInstanceIdMDC();
}
}
//4-insert a failover command
ProcessInstanceMetrics.incProcessInstanceByState("failover");
// updateProcessInstance host is null to mark this processInstance has been failover
// and insert a failover command
processInstance.setHost(Constants.NULL);
processService.processNeedFailoverProcessInstances(processInstance);
LOGGER.info("WorkflowInstance failover finished");
} finally {
LoggerUtils.removeWorkflowInstanceIdMDC();
}
}
failoverTimeCost.stop();
LOGGER.info("Master[{}] failover finished, useTime:{}ms",
masterHost,
failoverTimeCost.getTime(TimeUnit.MILLISECONDS));
}
构造Command,类型为RECOVER_TOLERANCE_FAULT_PROCESS
/**
* process need failover process instance
*
* @param processInstance processInstance
*/
@Override
@Transactional
public void processNeedFailoverProcessInstances(ProcessInstance processInstance) {
// 1 update processInstance host is null
processInstance.setHost(Constants.NULL);
processInstanceMapper.updateById(processInstance);
ProcessDefinition processDefinition = findProcessDefinition(processInstance.getProcessDefinitionCode(),
processInstance.getProcessDefinitionVersion());
// 2 insert into recover command
Command cmd = new Command();
cmd.setProcessDefinitionCode(processDefinition.getCode());
cmd.setProcessDefinitionVersion(processDefinition.getVersion());
cmd.setProcessInstanceId(processInstance.getId());
cmd.setCommandParam(
String.format("{\"%s\":%d}", CMD_PARAM_RECOVER_PROCESS_ID_STRING, processInstance.getId()));
cmd.setExecutorId(processInstance.getExecutorId());
cmd.setCommandType(CommandType.RECOVER_TOLERANCE_FAULT_PROCESS);
cmd.setProcessInstancePriority(processInstance.getProcessInstancePriority());
createCommand(cmd);
}
工作流实例中任务实例的处理,设置状态TaskExecutionStatus.NEED_FAULT_TOLERANCE
private void failoverTaskInstance(@NonNull ProcessInstance processInstance, @NonNull TaskInstance taskInstance) {
TaskMetrics.incTaskInstanceByState("failover");
boolean isMasterTask = TaskProcessorFactory.isMasterTask(taskInstance.getTaskType());
taskInstance.setProcessInstance(processInstance);
if (!isMasterTask) {
LOGGER.info("The failover taskInstance is not master task");
TaskExecutionContext taskExecutionContext = TaskExecutionContextBuilder.get()
.buildTaskInstanceRelatedInfo(taskInstance)
.buildProcessInstanceRelatedInfo(processInstance)
.buildProcessDefinitionRelatedInfo(processInstance.getProcessDefinition())
.create();
if (masterConfig.isKillYarnJobWhenTaskFailover()) {
// only kill yarn job if exists , the local thread has exited
LOGGER.info("TaskInstance failover begin kill the task related yarn job");
ProcessUtils.killYarnJob(logClient, taskExecutionContext);
}
// kill worker task, When the master failover and worker failover happened in the same time,
// the task may not be failover if we don't set NEED_FAULT_TOLERANCE.
// This can be improved if we can load all task when cache a workflowInstance in memory
sendKillCommandToWorker(taskInstance);
} else {
LOGGER.info("The failover taskInstance is a master task");
}
taskInstance.setState(TaskExecutionStatus.NEED_FAULT_TOLERANCE);
processService.saveTaskInstance(taskInstance);
}
容错工作流被重新调度
前面介绍了在Master启动之后,会启动一个MasterSchedulerBootstrap线程对任务进行调度。在DolphinScheduler中不管是定时任务,还是单次任务,或者是容错的任务,如果到了需要执行的时刻都会生成一个command命令插入到command表中。而MasterSchedulerBootstrap这个线程的作用就是不断从command表中获取需要被执行的command,来进行调度。
/**
* run of MasterSchedulerService
*/
@Override
public void run() {
while (!ServerLifeCycleManager.isStopped()) {
try {
if (!ServerLifeCycleManager.isRunning()) {
// the current server is not at running status, cannot consume command.
logger.warn("The current server {} is not at running status, cannot consumes commands.", this.masterAddress);
Thread.sleep(Constants.SLEEP_TIME_MILLIS);
}
// todo: if the workflow event queue is much, we need to handle the back pressure
boolean isOverload =
OSUtils.isOverload(masterConfig.getMaxCpuLoadAvg(), masterConfig.getReservedMemory());
if (isOverload) {
logger.warn("The current server {} is overload, cannot consumes commands.", this.masterAddress);
MasterServerMetrics.incMasterOverload();
Thread.sleep(Constants.SLEEP_TIME_MILLIS);
continue;
}
List<Command> commands = findCommands();
if (CollectionUtils.isEmpty(commands)) {
// indicate that no command ,sleep for 1s
Thread.sleep(Constants.SLEEP_TIME_MILLIS);
continue;
}
List<ProcessInstance> processInstances = command2ProcessInstance(commands);
if (CollectionUtils.isEmpty(processInstances)) {
// indicate that the command transform to processInstance error, sleep for 1s
Thread.sleep(Constants.SLEEP_TIME_MILLIS);
continue;
}
MasterServerMetrics.incMasterConsumeCommand(commands.size());
processInstances.forEach(processInstance -> {
try {
LoggerUtils.setWorkflowInstanceIdMDC(processInstance.getId());
if (processInstanceExecCacheManager.contains(processInstance.getId())) {
logger.error(
"The workflow instance is already been cached, this case shouldn't be happened");
}
WorkflowExecuteRunnable workflowRunnable = new WorkflowExecuteRunnable(processInstance,
processService,
processInstanceDao,
nettyExecutorManager,
processAlertManager,
masterConfig,
stateWheelExecuteThread,
curingGlobalParamsService);
processInstanceExecCacheManager.cache(processInstance.getId(), workflowRunnable);
workflowEventQueue.addEvent(new WorkflowEvent(WorkflowEventType.START_WORKFLOW,
processInstance.getId()));
} finally {
LoggerUtils.removeWorkflowInstanceIdMDC();
}
});
} catch (InterruptedException interruptedException) {
logger.warn("Master schedule bootstrap interrupted, close the loop", interruptedException);
Thread.currentThread().interrupt();
break;
} catch (Exception e) {
logger.error("Master schedule workflow error", e);
// sleep for 1s here to avoid the database down cause the exception boom
ThreadUtils.sleep(Constants.SLEEP_TIME_MILLIS);
}
}
}
上面的代码每次会从DB中批量获取10个(默认)command。然后构造成工作流实例进行遍历处理。
这里需要关注一下command2ProcessInstance方法,会将获取到需要执行的command转为工作流实例。在其内部最终会调用handleCommand方法中的constructProcessInstance方法来构造工作流实例。在其内部会将当前处理此实例的host节点信息设置到实例信息中,并且会对commandType是RECOVER_TOLERANCE_FAULT_PROCESS容错类型的情况进行设置(省略部分代码):
protected @Nullable ProcessInstance constructProcessInstance(Command command,
String host) throws CronParseException, CodeGenerateException {
ProcessInstance processInstance;
ProcessDefinition processDefinition;
CommandType commandType = command.getCommandType();
processDefinition =
this.findProcessDefinition(command.getProcessDefinitionCode(), command.getProcessDefinitionVersion());
if (processDefinition == null) {
logger.error("cannot find the work process define! define code : {}", command.getProcessDefinitionCode());
throw new IllegalArgumentException("Cannot find the process definition for this workflowInstance");
}
Map<String, String> cmdParam = JSONUtils.toMap(command.getCommandParam());
int processInstanceId = command.getProcessInstanceId();
if (processInstanceId == 0) {
processInstance = generateNewProcessInstance(processDefinition, command, cmdParam);
} else {
processInstance = this.findProcessInstanceDetailById(processInstanceId).orElse(null);
if (processInstance == null) {
return null;
}
}
if (cmdParam != null) {
......
}
// reset command parameter
if (processInstance.getCommandParam() != null) {
Map<String, String> processCmdParam = JSONUtils.toMap(processInstance.getCommandParam());
processCmdParam.forEach((key, value) -> {
if (!cmdParam.containsKey(key)) {
cmdParam.put(key, value);
}
});
}
// reset command parameter if sub process
if (cmdParam.containsKey(CommandKeyConstants.CMD_PARAM_SUB_PROCESS)) {
processInstance.setCommandParam(command.getCommandParam());
}
if (Boolean.FALSE.equals(checkCmdParam(command, cmdParam))) {
logger.error("command parameter check failed!");
return null;
}
if (command.getScheduleTime() != null) {
processInstance.setScheduleTime(command.getScheduleTime());
}
//设置处理节点的host和restartTime。
processInstance.setHost(host);
processInstance.setRestartTime(new Date());
WorkflowExecutionStatus runStatus = WorkflowExecutionStatus.RUNNING_EXECUTION;
int runTime = processInstance.getRunTimes();
switch (commandType) {
case START_PROCESS:
break;
case START_FAILURE_TASK_PROCESS:
// find failed tasks and init these tasks
......
break;
case START_CURRENT_TASK_PROCESS:
break;
case RECOVER_WAITING_THREAD:
break;
case RECOVER_SUSPENDED_PROCESS:
// find pause tasks and init task's state
......
break;
//这里对容错类型的command进行设置Flag.YES
case RECOVER_TOLERANCE_FAULT_PROCESS:
// recover tolerance fault process
processInstance.setRecovery(Flag.YES);
processInstance.setRunTimes(runTime + 1);
runStatus = processInstance.getState();
break;
case COMPLEMENT_DATA:
// delete all the valid tasks when complement data if id is not null
......
break;
case REPEAT_RUNNING:
// delete the recover task names from command parameter
......
break;
case SCHEDULER:
break;
default:
break;
}
processInstance.setStateWithDesc(runStatus, commandType.getDescp());
return processInstance;
}
接着对于每个工作流实例都会加入到一个队列中。
private static final LinkedBlockingQueue<WorkflowEvent> workflowEventQueue = new LinkedBlockingQueue<>();
/**
* Add a workflow event.
*/
public void addEvent(WorkflowEvent workflowEvent) {
workflowEventQueue.add(workflowEvent);
logger.info("Added workflow event to workflowEvent queue, event: {}", workflowEvent);
}
/**
* Pool the head of the workflow event queue and wait an workflow event.
*/
public WorkflowEvent poolEvent() throws InterruptedException {
return workflowEventQueue.take();
}
有添加就会有消费,在Master启动之后就已经启动了消费的线程WorkflowEventLooper。
this.masterSchedulerBootstrap.start(); 启动入口:
@Override
public synchronized void start() {
logger.info("Master schedule bootstrap starting..");
super.start();
workflowEventLooper.start();
logger.info("Master schedule bootstrap started...");
}
具体消费逻辑代码:
public void run() {
WorkflowEvent workflowEvent = null;
while (!ServerLifeCycleManager.isStopped()) {
try {
workflowEvent = workflowEventQueue.poolEvent();
LoggerUtils.setWorkflowInstanceIdMDC(workflowEvent.getWorkflowInstanceId());
logger.info("Workflow event looper receive a workflow event: {}, will handle this", workflowEvent);
WorkflowEventHandler workflowEventHandler =
workflowEventHandlerMap.get(workflowEvent.getWorkflowEventType());
workflowEventHandler.handleWorkflowEvent(workflowEvent);
} catch (InterruptedException e) {
logger.warn("WorkflowEventLooper thread is interrupted, will close this loop", e);
Thread.currentThread().interrupt();
break;
} catch (WorkflowEventHandleException workflowEventHandleException) {
logger.error("Handle workflow event failed, will add this event to event queue again, event: {}",
workflowEvent, workflowEventHandleException);
workflowEventQueue.addEvent(workflowEvent);
ThreadUtils.sleep(Constants.SLEEP_TIME_MILLIS);
} catch (WorkflowEventHandleError workflowEventHandleError) {
logger.error("Handle workflow event error, will drop this event, event: {}",
workflowEvent,
workflowEventHandleError);
} catch (Exception unknownException) {
logger.error(
"Handle workflow event failed, get a unknown exception, will add this event to event queue again, event: {}",
workflowEvent, unknownException);
workflowEventQueue.addEvent(workflowEvent);
ThreadUtils.sleep(Constants.SLEEP_TIME_MILLIS);
} finally {
LoggerUtils.removeWorkflowInstanceIdMDC();
}
}
}
可以看到就是从队列中获取添加的event,然后找对应的handler处理。最终会进入到WorkflowStartEventHandler中:
@Override
public void handleWorkflowEvent(final WorkflowEvent workflowEvent) throws WorkflowEventHandleError {
logger.info("Handle workflow start event, begin to start a workflow, event: {}", workflowEvent);
WorkflowExecuteRunnable workflowExecuteRunnable = processInstanceExecCacheManager.getByProcessInstanceId(
workflowEvent.getWorkflowInstanceId());
if (workflowExecuteRunnable == null) {
throw new WorkflowEventHandleError(
"The workflow start event is invalid, cannot find the workflow instance from cache");
}
ProcessInstanceMetrics.incProcessInstanceByState("submit");
ProcessInstance processInstance = workflowExecuteRunnable.getProcessInstance();
CompletableFuture.supplyAsync(workflowExecuteRunnable::call, workflowExecuteThreadPool)
.thenAccept(workflowSubmitStatue -> {
if (WorkflowSubmitStatue.SUCCESS == workflowSubmitStatue) {
// submit failed will resend the event to workflow event queue
logger.info("Success submit the workflow instance");
if (processInstance.getTimeout() > 0) {
stateWheelExecuteThread.addProcess4TimeoutCheck(processInstance);
}
} else {
logger.error("Failed to submit the workflow instance, will resend the workflow start event: {}",
workflowEvent);
workflowEventQueue.addEvent(workflowEvent);
}
});
}
最终就会对工作流实例中的Task进行提交处理:
构造工作流实例的DAG,初始化队列,提交DAG的头节点
@Override
public WorkflowSubmitStatue call() {
if (isStart()) {
// This case should not been happened
logger.warn("[WorkflowInstance-{}] The workflow has already been started", processInstance.getId());
return WorkflowSubmitStatue.DUPLICATED_SUBMITTED;
}
try {
LoggerUtils.setWorkflowInstanceIdMDC(processInstance.getId());
if (workflowRunnableStatus == WorkflowRunnableStatus.CREATED) {
buildFlowDag();
workflowRunnableStatus = WorkflowRunnableStatus.INITIALIZE_DAG;
logger.info("workflowStatue changed to :{}", workflowRunnableStatus);
}
if (workflowRunnableStatus == WorkflowRunnableStatus.INITIALIZE_DAG) {
initTaskQueue();
workflowRunnableStatus = WorkflowRunnableStatus.INITIALIZE_QUEUE;
logger.info("workflowStatue changed to :{}", workflowRunnableStatus);
}
if (workflowRunnableStatus == WorkflowRunnableStatus.INITIALIZE_QUEUE) {
submitPostNode(null);
workflowRunnableStatus = WorkflowRunnableStatus.STARTED;
logger.info("workflowStatue changed to :{}", workflowRunnableStatus);
}
return WorkflowSubmitStatue.SUCCESS;
} catch (Exception e) {
logger.error("Start workflow error", e);
return WorkflowSubmitStatue.FAILED;
} finally {
LoggerUtils.removeWorkflowInstanceIdMDC();
}
}
那么针对需要容错的任务是在哪里处理的呢? 可以去initTaskQueue方法中瞧一瞧:
首先会调用isNewProcessInstance方法来判断是否是新的工作流实例,具体代码如下
private boolean isNewProcessInstance() {
if (Flag.YES.equals(processInstance.getRecovery())) {
logger.info("This workInstance will be recover by this execution");
return false;
}
if (WorkflowExecutionStatus.RUNNING_EXECUTION == processInstance.getState()
&& processInstance.getRunTimes() == 1) {
return true;
}
logger.info(
"The workflowInstance has been executed before, this execution is to reRun, processInstance status: {}, runTimes: {}",
processInstance.getState(),
processInstance.getRunTimes());
return false;
}
通过上面可以看到如果工作流实例的recovery熟悉等于Flag.YES,则会返回false。通过前面我们可以知道在处理容错类型command转换为ProcessInstance的时候对其recovery属性设置了Flag.YES。因此返回false,就会执行如下的处理
if (!isNewProcessInstance()) {
logger.info("The workflowInstance is not a newly running instance, runtimes: {}, recover flag: {}",
processInstance.getRunTimes(),
processInstance.getRecovery());
List<TaskInstance> validTaskInstanceList =
processService.findValidTaskListByProcessId(processInstance.getId());
for (TaskInstance task : validTaskInstanceList) {
try {
LoggerUtils.setWorkflowAndTaskInstanceIDMDC(task.getProcessInstanceId(), task.getId());
logger.info(
"Check the taskInstance from a exist workflowInstance, existTaskInstanceCode: {}, taskInstanceStatus: {}",
task.getTaskCode(),
task.getState());
if (validTaskMap.containsKey(task.getTaskCode())) {
logger.warn("Have same taskCode taskInstance when init task queue, need to check taskExecutionStatus, taskCode:{}",
task.getTaskCode());
int oldTaskInstanceId = validTaskMap.get(task.getTaskCode());
TaskInstance oldTaskInstance = taskInstanceMap.get(oldTaskInstanceId);
if (!oldTaskInstance.getState().isFinished() && task.getState().isFinished()) {
task.setFlag(Flag.NO);
processService.updateTaskInstance(task);
continue;
}
}
validTaskMap.put(task.getTaskCode(), task.getId());
taskInstanceMap.put(task.getId(), task);
if (task.isTaskComplete()) {
logger.info("TaskInstance is already complete.");
completeTaskMap.put(task.getTaskCode(), task.getId());
continue;
}
if (task.isConditionsTask() || DagHelper.haveConditionsAfterNode(Long.toString(task.getTaskCode()),
dag)) {
continue;
}
if (task.taskCanRetry()) {
if (task.getState().isNeedFaultTolerance()) {
logger.info("TaskInstance needs fault tolerance, will be added to standby list.");
task.setFlag(Flag.NO);
processService.updateTaskInstance(task);
// tolerantTaskInstance add to standby list directly
TaskInstance tolerantTaskInstance = cloneTolerantTaskInstance(task);
addTaskToStandByList(tolerantTaskInstance);
} else {
logger.info("Retry taskInstance, taskState: {}", task.getState());
retryTaskInstance(task);
}
continue;
}
if (task.getState().isFailure()) {
errorTaskMap.put(task.getTaskCode(), task.getId());
}
} finally {
LoggerUtils.removeWorkflowAndTaskInstanceIdMDC();
}
}
} else {
logger.info("The current workflowInstance is a newly running workflowInstance");
}
上面就会对工作流实例下的所有任务实例进行处理,对已完成的任务加入到completeTaskMap中。并且通过task.getState().isNeedFaultTolerance()来判断是否是需要容错的任务还是重试任务。容错任务会加入到队列readyToSubmitTaskQueue中(tolerantTaskInstance add to standby list directly)。
最后通过submitPostNode方法来触发工作流实例中任务实例的执行。可以发现和普通任务没有什么区别。
总结
对于Master的容错流程大致分为三个方向:
1-获取容错范围:全程会加锁获取,根据异常节点的host去获取哪些工作流实例需要加速
2-容错处理:包括容错工作流实例和任务实例,在容错前会比较实例的开始时间和服务节点的启动时间,在服务启动时间之后的则跳过容错;最终生成command命令到表中。
3-容错任务的调度:调度线程遍历到command命令之后会重新构造为工作流实例,并根据容错的类型初始化任务实例到对应的队列中,然后对其任务实例重新进行调度。
可以参考官方文档
加载全部内容