Java SE之了解泛型
程序猿教你打篮球 人气:0如何创建可以存放各种类型的数组?
根据JavaSE的语法知识储备,如果现在让你们创建如标题一样的数组,你会怎么创建呢?
答案是:使用 Object 类来定义数组,因为 Object 是所有类的父类, 可以接收任意子类对象,也即实现了向上转型,于是我们就写出了这样的代码:
private Object[] array = new Object[3];
那么这种方法可取吗?
显然是可取的,但只是使用起来会很不方便,具体不方便在哪,我们接着往后看,在这里我们要写一个类,里面提供了获取array指定下标的数据,和设置array指定下标的数据,于是写出了这样的代码:
public class DrawForth {
private Object[] array = new Object[3];
public void setPosArray(int pos, Object o) {
this.array[pos] = o;
}
public Object getPosValue(int pos) {
return this.array[pos];
}
}代码到这里仍然是正确的,那我们就要去使用这个类,也就是在main方法中用这个类实例对象,去操作里面的数组,所以main方法的代码就是这个样子:
public static void main(String[] args) {
DrawForth draw = new DrawForth();
draw.setPosArray(0, 123);
draw.setPosArray(1, "hello");
draw.setPosArray(2, 12.5);
int a = (int)draw.getPosValue(0);
String str = (String)draw.getPosValue(1);
double d = (double)draw.getPosValue(1);
}看到这里,你是不是就发现这样做很不方便呢?
当我们往数组里面设置数据的时候开心了,想设置成什么类型就是什么类型,但是!当我们要获取对应位置的元素就麻烦了,我们必须知道他是什么类型,然后进行强制类型转换才能接收,(返回是Object类型所以需要强转),难道往后每次取数据的时候我还得看一看是什么类型吗?
泛型的概念
浅聊泛型
泛型是在JDK1.5引入的新的语法,通过上面的例子,由此我们就引出了泛型,泛型简单来说就是把类型当成参数传递,指定当前容器,你想持有什么类型的对象,你就传什么类型过去,让编译器去做类型检查!
从而实现类型参数化(不能是基本数据类型)
泛型的简单语法
class Test1<类型形参列表> {
}
class Test2<类型形参1, 类型形参2, ...> {
}类型形参列表的命名规范
类名后面的 <类型形参列表> 这是一个占位符,表示当前类是一个泛型类,形参列表里面如何写?
通常用一个大写字母表示,当然,你也可以怎么开心怎么来,但是小心办公室谈话警告哈(dog),这里有几个常用的名称:
- E:表示 Element
- K:表示 Key
- V:表示 Value
- N:表述 Number
- T:表示 Type
- S,U,V表示,第二,第三,第四个类型
使用泛型知识创建数组
这里就来修改一下刚开始的代码,使用到泛型的知识,那么我们就可以这样修改:
public class DrawForth<T> {
//private T[] array = new T[3]; error
private T[] array = (T[])new Object[3];
public void setPosArray(int pos, T o) {
this.array[pos] = o;
}
public T getPosValue(int pos) {
return this.array[pos];
}
public static void main(String[] args) {
DrawForth<Integer> draw = new DrawForth<>();
draw.setPosArray(0, 123);
//draw.setPosArray(1, "hello"); error
//draw.setPosArray(2, 12.5); error
draw.setPosArray(1, 1234);
draw.setPosArray(2, 12345);
int a = draw.getPosValue(0);
int b = draw.getPosValue(1);
int c = draw.getPosValue(2);
}
}如上修改之后的代码,我们可以得到以下知识点:
- <T> 是一个占位符,仅表示这个类是泛型类
- 不能 new 泛型数组,此代码的写法也不是最好的方法!
- 实例化泛型类的语法是:类名<类型实参>变量名 = new 泛型类<类型实参>(构造方法实参);
- 注意:new 泛型类<>尖括号中可以省略类型实参,编译器可以根据上下文推导!
- 编译时自动进行类型检查和转换。
什么是裸类型
裸类型就是指在实例化泛型类对象的时候,没有传类型实参,比如下面的代码就是一个裸类型:
DrawForth draw = new DrawForth();
我现在可以告诉你,这样做编译完全正常,但我们不要去使用裸类型,因为这是为了兼容老版本的 API 保留的机制,毕竟泛型是 Java1.5 新增的语法。
泛型是如何编译的?
泛型的擦除机制
如果我们要看泛型是如何编译的,可以通过命令 javap -c 字节码文件 来进行查看:
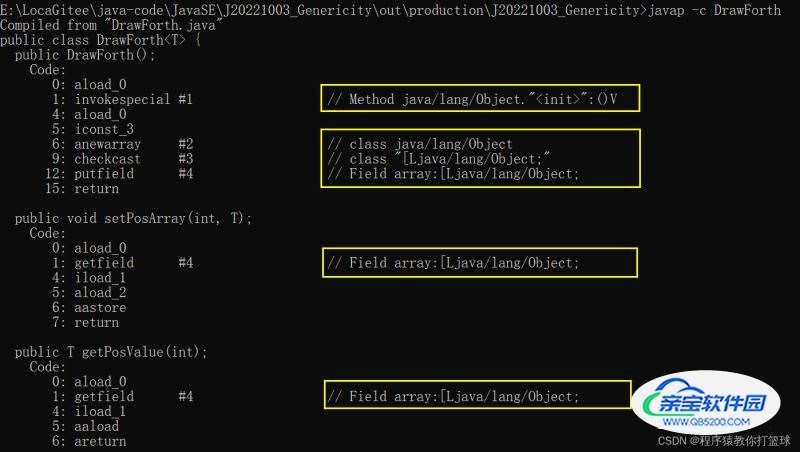
如上代码是 2.4 段落中的代码,奇怪,明明传的实参是 Integer 类型,最后所有的 T 却变成了 Object 类型,这就是擦除机制
所以在Java中,泛型机制是在编译级别实现的,运行期间不会包含任何泛型信息。
提示:类型擦除,不一定是把 T 变成 Object(泛型的上界会提到)
再谈为什么不能实例化泛型数组?
知道了擦除机制后,那么 T[] array = new T[3]; 是不对的,编译的时候,替换为Object,不是相当于:Object[] array = new Object[3]吗?
在Java中,数组是一个很特殊的类型,数组是在运行时存储和检查类型信息, 泛型则是在编译时检查类型错误。
而且Java设定擦除机制就只针对变量的类型和返回值的类型,所以在编译时候压根不会擦除 new T[3]; 这个 T ,所以自然编译就会报错!
我们前面通过强制类型转换的方式创建了泛型数组,说过那样写并不好,正确的方式是通过反射创建指定类型的数组,由于现在没学习到反射,这里先放着就行。
什么是泛型的上界?
有了擦除机制的学习,泛型在运行时都会被擦除成 Object 但是并不是所有的都是这样,泛型的上界就是对泛型类传入的类型变量做一定的约束,可以通过类型边界来进行约束。
语法:
class 泛型类名称<类型形参 extends 类型边界> {
//...code
}
这里我们来举两个例子:
例1:
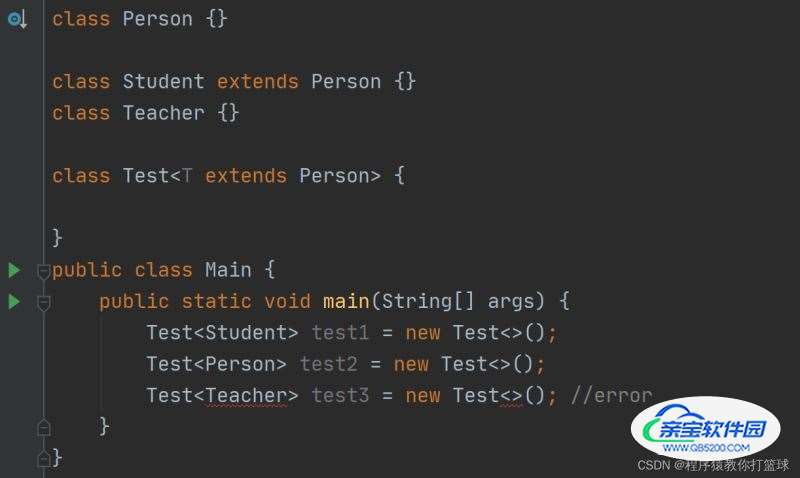
这里简单分析一下,Student 继承了 Person 类,而 Teacher 没有继承 Person 类,接着 Test 类给定了泛型的上界, 那么 Test 类中 <> 里面是什么意思呢?
表示只接收 Person 或 Person 的子类作为 T 的类型实参。
通过 main 方法中的例子也可也看出,类型传参只能传 Person 或 Person 的子类。
例2:
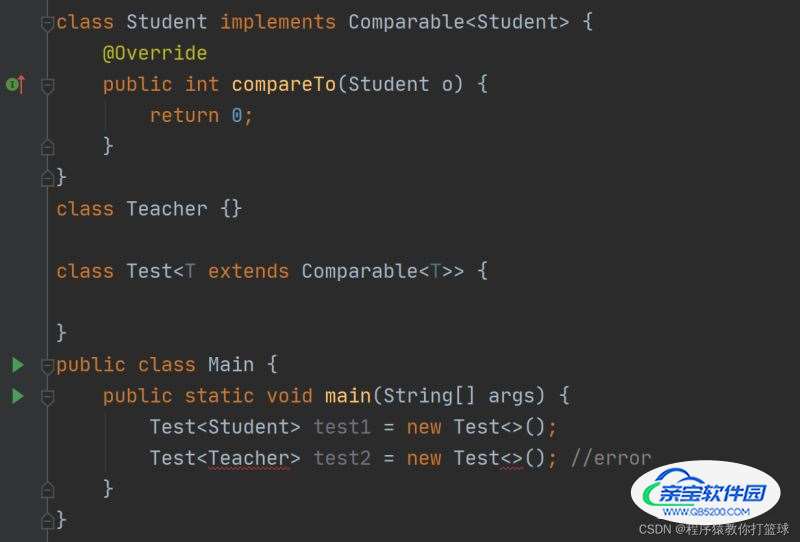
还是简单分析一下,Student 类实现了 Comparable 接口,而 Teacher 类并没有实现, 接着 Test 类给定了泛型的上界, 那么 Test 类中 <> 里面是什么意思呢?
表示 T 接收的类型必须是实现 Comparable 这个接口的!
通过 main 方法中的例子也可也看出,类型传参只能传实现了 Comparable 接口的类 。
注意:如果泛型类没有指定边界,则可以默认视为 T extends Object。
再谈擦除机制
如果给泛型设置了上界,则会擦除到边界处,也就不会擦除成 Object!
class Person {}
class Student extends Person {}
public class Main<T extends Person> {
T array[] = (T[])new Object[10];
public static void main(String[] args) {
Main<Student> main = new Main<>();
}
}这里 Main 方法中设定了泛型的上界,传的类型实参必须是Person的子类,所以编译时会不会被擦除成 Person呢?下面我们查看一下对应的字节码文件:
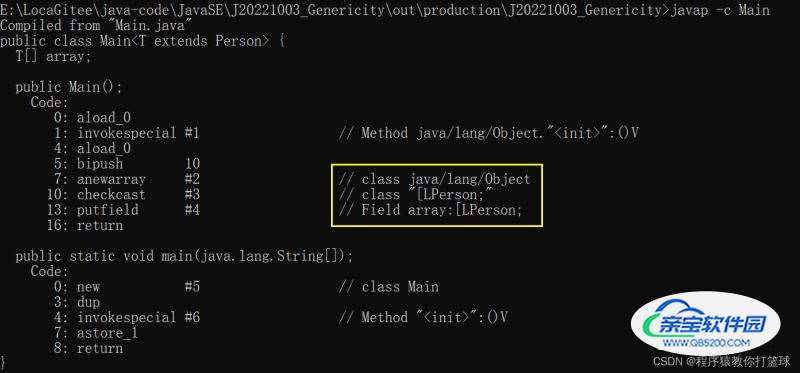
显而易见,确实被擦除成了泛型的上界!
包装类的知识
基本数据类型和包装类
在Java中,由于基本类型不是继承自Object,为了在泛型代码中可以支持基本类型,Java给每个基本类型都对应了 一个包装类型。
装箱和拆箱
装箱和拆箱也可也被称为装包和拆包。
装箱:将一个基本数据类型值放入对象的某个属性中。
拆箱:将一个包装类型中的值取出放到一个基本数据类型中。
这里我们举例来更清楚的认识装箱和拆箱:
public class Test {
public static void main(String[] args) {
int a = 10;
Integer integer1 = new Integer(a); //手动装箱
Integer integer2 = Integer.valueOf(100); //手动装箱
int b = integer1.intValue(); //手动拆箱
}
}自动装箱和拆箱
由上面的例子我们可以看出,手动装箱和拆箱会带来不少的代码量,为了减少开发者的负担,Java中提供了自动转换机制,比如:
public class Test {
public static void main(String[] args) {
Integer integer = 100; //自动装箱
int a = integer; //自动拆箱
}
}一道面试题
以下代码输出什么?
public class Test {
public static void main(String[] args) {
Integer a1 = 100;
Integer a2 = 100;
System.out.println(a1 == a2);
Integer a3 = 200;
Integer a4 = 200;
System.out.println(a3 == a4);
}
}结果是:true false
为什么是这样的答案?这里我们去看一下对应的字节码文件再分析:
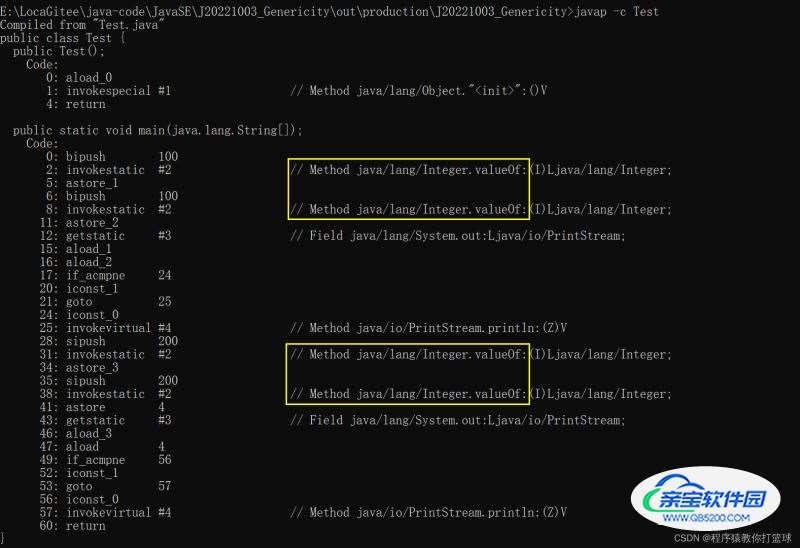
通过观察字节码文件,我们可以看到,在自动装箱的过程中,调用了 Integer.valueOf 方法,那么我们就去看一看 valueOf 方法中做了一件什么事:
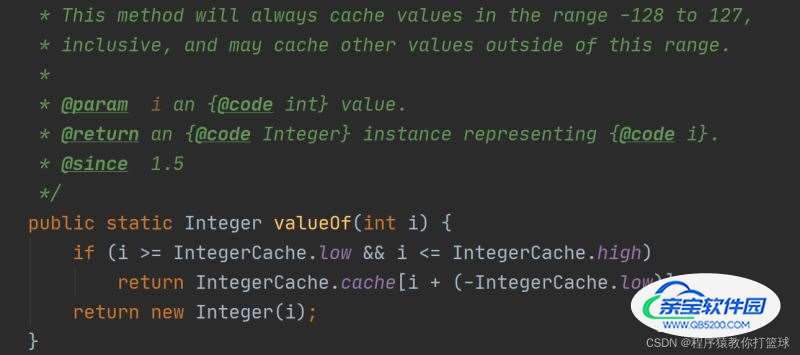
通过查看源码,我们也能看出此方法将始终缓存 -128到127范围内的值, 通过查看对应的 low 和 high 值也可也发现 low为 -128,high为127,cache 是一个缓存数组。
接着我们来阅读下这段代码的操作,如果传入的值是介于 -128和127 之间,则直接返回缓存数组对应下标的值,比如传入的值是 -127 也就返回 chache[-127+(-(-128))],也即1下标位置的值!
如果超出了 -128到127 的范围则是新 new 一个对象返回,只要是 new 就一定是一个新对象,地址也是唯一的。
而且引用类型用 == 比较,比较的是引用的对象的地址,看完上面的介绍,你能弄明白为什么输出 true 和 false 吗?
泛型方法
定义泛型方法的语法:
方法限定符 <类型形参列表> 返回值类型 方法名称(形参列表) {
//...code
}
普通泛型方法
这里我们就举一个很简单的例子:
public class Test {
public <T> T getValue(T value) {
return value;
}
public static void main(String[] args) {
Test test = new Test();
int ret = test.<Integer>getValue(150); //不使用类型推导
System.out.println(ret);
double d = test.getValue(12.5); //使用类型推导
System.out.println(d);
}
}这就是泛型方法,这里面有个关键词,类型推导,什么是类型推导呢?
类型推导就是编译器会根据你传参的数据,自动推断出你要传递的类型实参,你也可以不使用类型推导,他们的效果都是一样的。
静态泛型方法
既然有普通泛型方法,同理,也有静态的泛型方法,也就是在修饰符后面加上 static,静态泛型方法跟普通静态方法一样,都是通过类名访问,不依赖于对象:
public class Test {
public static<T> T getValue(T value) {
return value;
}
public static void main(String[] args) {
int ret = Test.<Integer>getValue(150); //不使用类型推导
System.out.println(ret);
double d = getValue(12.5); //使用类型推导(静态方法可以直接访问同类中静态方法,可以不借助类名)
System.out.println(d);
}
}通配符
引出通配符
我们先来看这样的一段代码:
class Message<T> {
private T message ;
public T getMessage() {
return message;
}
public void setMessage(T message) {
this.message = message;
}
}
public class TestDemo {
public static void fun(Message<String> temp){
System.out.println(temp.getMessage());
}
public static void main(String[] args) {
Message<String> message = new Message<>();
message.setMessage("欢迎来到篮球哥的博客!");
fun(message);
}
}如果你仔细观察,TestDemo 类中的 fun 方法是有局限性的,他的形参就限制了传过来的 Missage类的类型必须是String,也就是说,形参能接收的对象的类型参数必须是String类型。
所以如果我们 new Missage对象时,类型实参传的是 Integer 呢?fun方法就会报错:
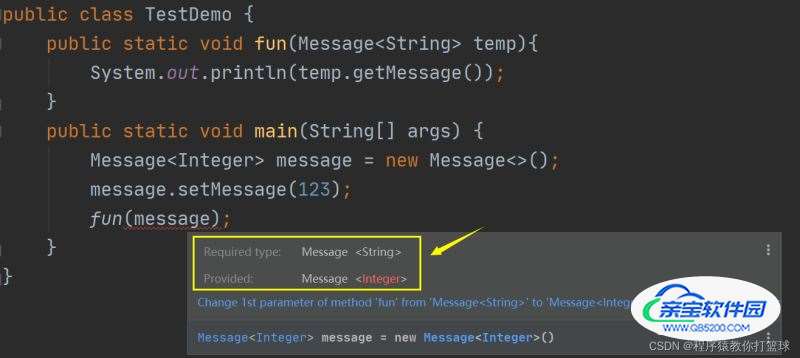
所以为了解决以上的问题,就有了通配符的概念!
认识通配符
泛型T是确定的类型,一旦传类型了,就定下来了,而通配符的出现,就会使得更灵活,或者说更不确定,就好像他是一个垃圾箱,可以接收所有的泛型类型,但又不能让用户随意更改!
通配符:?
现在我们就把上面的代码更改一下,运用上通配符:
public class TestDemo {
public static void fun(Message<?> temp){
System.out.println(temp.getMessage());
}
public static void main(String[] args) {
Message<Integer> message1 = new Message<>();
message1.setMessage(123);
fun(message1);
Message<String> message2 = new Message<>();
message2.setMessage("欢迎来到篮球哥的博客!");
fun(message2);
}
}这样我们的代码就不会出错,但是,你不能通过 fun 方法去修改你传递对象的内容,为什么呢?
站在 fun 的角度,他使用了 ? 接收可以任意泛型类,所以他不能确定自己接收了什么对象的!也就无法对对象的值进行更改!
这样代码还是不够好,如果真的什么泛型类都能接收,那不是乱套了,所以在此基础上,又增加了通配符的上界和下界!
通配符的上界
语法:<? extends 上界> 例如:<? extends Person>
表示只能接收的实参类型是 Person 或者 Person的子类!
图例:
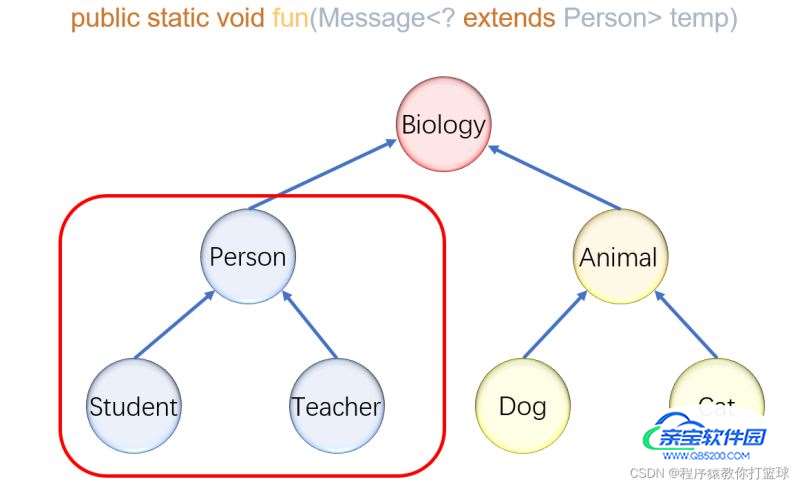
这里我们写一段伪代码,更改上面用例的方法:
public static void fun(Message<? extends Person> temp){
//temp.setMessage(new Student()); //仍然无法修改!
//temp.setMessage(new Person()); //仍然无法修改!
Person person = temp.getMessage();
System.out.println(person);
}为什么还是不能修改对象的属性呢?
因为 temp 接收的是 Person 或 Person的子类,此时接收的是哪个子类无法确定,也就无法设置对象的属性。
因为我们知道只能接收 Person以及他的子类,所以我们就可以拿 Person 类型来接收 getMessage 的对象,因为 Person是他们的父类,获取的是子类对象就可以实现向上转型,是安全的。
总结: 通配符的上界,不能进行写入数据,只能进行读取数据。
通配符的下界
语法:<? extends 下界> 例如:<? super Person>
表示只能接收的实参类型是 Person 或者 Person的父类!
图例:
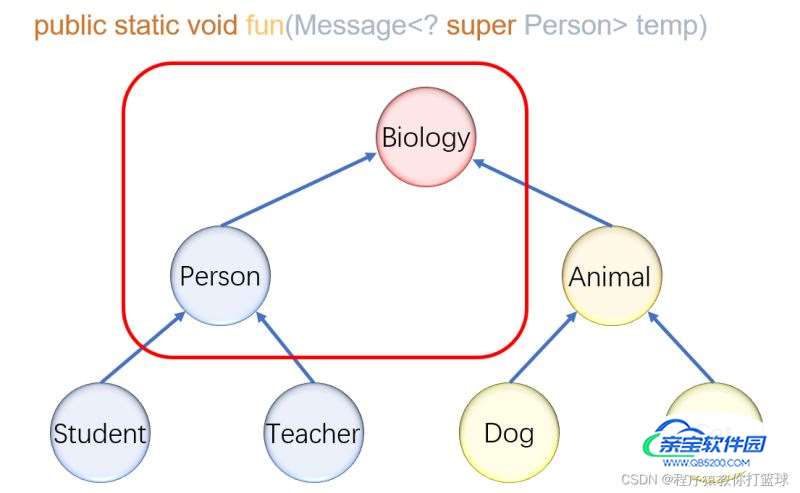
这里我们写一段伪代码,更改上面用例的方法:
public static void fun(Message<? super Person> temp){
temp.setMessage(new Student()); //可以修改,因为添加的是他的子类
temp.setMessage(new Person()); //可以修改,因为添加的是他本身
//Person person = temp.getMessage(); // 不能接收,不知道获取的是哪个父类
System.out.println(temp.getMessage()); //只能输出
}为啥下界就可以设置对象的属性呢?
因为只能接收本身以及父类的类型,所以我们可以setMessage 传子类对象,但是不能传递父类,因为修改成子类对象是向上转型是安全的,如果 setMessaget 传父类对象的话就是向下转型则不安全!
为啥不能 getMessage呢?因为你不知道形参接收的类型是哪个父类,只能去输出内容!
总结:通配符的下界,不能进行读取数据,只能写入数据。
加载全部内容