k8s编排之Deployment知识点详解
半芽湾 人气:0Pod 复杂的API对象
Pod 这个看似复杂的 API 对象,实际上就是对容器的进一步抽象和封装而已。
说得更形象些,“容器”镜像虽然好用,但是容器这样一个“沙盒”的概念,对于描述应用来说,还是太过简单了。这就好比,集装箱固然好用,但是如果它四面都光秃秃的,吊车还怎么把这个集装箱吊起来并摆放好呢?
所以,Pod 对象,其实就是容器的升级版。它对容器进行了组合,添加了更多的属性和字段。这就好比给集装箱四面安装了吊环,使得 Kubernetes 这架“吊车”,可以更轻松地操作它。
而 Kubernetes 操作这些“集装箱”的逻辑,都由控制器(Controller)完成。 Deployment 这个最基本的控制器对象。
nginx-deployment
现在,我们一起来回顾一下这个名叫 nginx-deployment 的例子:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
这个 Deployment 定义的编排动作非常简单,即:确保携带了 app=nginx 标签的 Pod 的个数,永远等于 spec.replicas 指定的个数,即 2 个。
这就意味着,如果在这个集群中,携带 app=nginx 标签的 Pod 的个数大于 2 的时候,就会有旧的 Pod 被删除;反之,就会有新的 Pod 被创建。
这时,你也许就会好奇:究竟是 Kubernetes 项目中的哪个组件,在执行这些操作呢?
我在前面介绍 Kubernetes 架构的时候,曾经提到过一个叫作 kube-controller-manager 的组件。
实际上,这个组件,就是一系列控制器的集合。我们可以查看一下 Kubernetes 项目的 pkg/controller 目录:
$ cd kubernetes/pkg/controller/ $ ls -d */ deployment/ job/ podautoscaler/ cloud/ disruption/ namespace/ replicaset/ serviceaccount/ volume/ cronjob/ garbagecollector/ nodelifecycle/ replication/
这个目录下面的每一个控制器,都以独有的方式负责某种编排功能。而我们的 Deployment,正是这些控制器中的一种。
实际上,这些控制器之所以被统一放在 pkg/controller 目录下,就是因为它们都遵循 Kubernetes 项目中的一个通用编排模式,即:控制循环(control loop)。
在具体实现中,实际状态往往来自于 Kubernetes 集群本身。
比如,kubelet 通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它自己感兴趣的信息,这些都是常见的实际状态的来源。
而期望状态,一般来自于用户提交的 YAML 文件。
比如,Deployment 对象中 Replicas 字段的值。很明显,这些信息往往都保存在 Etcd 中。
接下来,以 Deployment 为例,我和你简单描述一下它对控制器模型的实现:
- Deployment 控制器从 Etcd 中获取到所有携带了“app: nginx”标签的 Pod,然后统计它们的数量,这就是实际状态;
- Deployment 对象的 Replicas 字段的值就是期望状态;
- Deployment 控制器将两个状态做比较,然后根据比较结果,确定是创建 Pod,还是删除已有的 Pod
可以看到,一个 Kubernetes 对象的主要编排逻辑,实际上是在第三步的“对比”阶段完成的。
这个操作,通常被叫作调谐(Reconcile)。这个调谐的过程,则被称作“Reconcile Loop”(调谐循环)或者“Sync Loop”(同步循环)。
所以,如果你以后在文档或者社区中碰到这些词,都不要担心,它们其实指的都是同一个东西:控制循环。
而调谐的最终结果,往往都是对被控制对象的某种写操作。
比如,增加 Pod,删除已有的 Pod,或者更新 Pod 的某个字段。这也是 Kubernetes 项目“面向 API 对象编程”的一个直观体现。
其实,像 Deployment 这种控制器的设计原理,就是我们前面提到过的,“用一种对象管理另一种对象”的“艺术”。
其中,这个控制器对象本身,负责定义被管理对象的期望状态。比如,Deployment 里的 replicas=2 这个字段。
而被控制对象的定义,则来自于一个“模板”。比如,Deployment 里的 template 字段。
可以看到,Deployment 这个 template 字段里的内容,跟一个标准的 Pod 对象的 API 定义,丝毫不差。而所有被这个 Deployment 管理的 Pod 实例,其实都是根据这个 template 字段的内容创建出来的。
像 Deployment 定义的 template 字段,在 Kubernetes 项目中有一个专有的名字,叫作 PodTemplate(Pod 模板)。
这个概念非常重要,因为后面我要讲解到的大多数控制器,都会使用 PodTemplate 来统一定义它所要管理的 Pod。更有意思的是,我们还会看到其他类型的对象模板,比如 Volume 的模板。
Deployment 及类似控制器总结
至此,我们就可以对 Deployment 以及其他类似的控制器,做一个简单总结了:

类似 Deployment 这样的一个控制器,实际上都是由上半部分的控制器定义(包括期望状态),加上下半部分的被控制对象的模板组成的。
这就是为什么,在所有 API 对象的 Metadata 里,都有一个字段叫作 ownerReference,用于保存当前这个 API 对象的拥有者(Owner)的信息。
那么,对于我们这个 nginx-deployment 来说,它创建出来的 Pod 的 ownerReference 就是 nginx-deployment 吗?或者说,nginx-deployment 所直接控制的,就是 Pod 对象么?
Deployment 看似简单,但实际上,它实现了 Kubernetes 项目中一个非常重要的功能:Pod 的“水平扩展 / 收缩”(horizontal scaling out/in)。这个功能,是从 PaaS 时代开始,一个平台级项目就必须具备的编排能力。
举个例子,如果你更新了 Deployment 的 Pod 模板(比如,修改了容器的镜像),那么 Deployment 就需要遵循一种叫作“滚动更新”(rolling update)的方式,来升级现有的容器。
而这个能力的实现,依赖的是 Kubernetes 项目中的一个非常重要的概念(API 对象):ReplicaSet。
ReplicaSet 的结构非常简单,我们可以通过这个 YAML 文件查看一下:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-set
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
从这个 YAML 文件中,我们可以看到,一个 ReplicaSet 对象,其实就是由副本数目的定义和一个 Pod 模板组成的。不难发现,它的定义其实是 Deployment 的一个子集。
更重要的是,Deployment 控制器实际操纵的,正是这样的 ReplicaSet 对象,而不是 Pod 对象。
对于一个 Deployment 所管理的 Pod,它的 ownerReference 是谁?这个问题的答案就是:ReplicaSet。
明白了这个原理,我再来和你一起分析一个Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
可以看到,这就是一个我们常用的 nginx-deployment,它定义的 Pod 副本个数是 3(spec.replicas=3)。
那么,在具体的实现上,这个 Deployment,与 ReplicaSet,以及 Pod 的关系是怎样的呢?
我们可以用一张图把它描述出来:
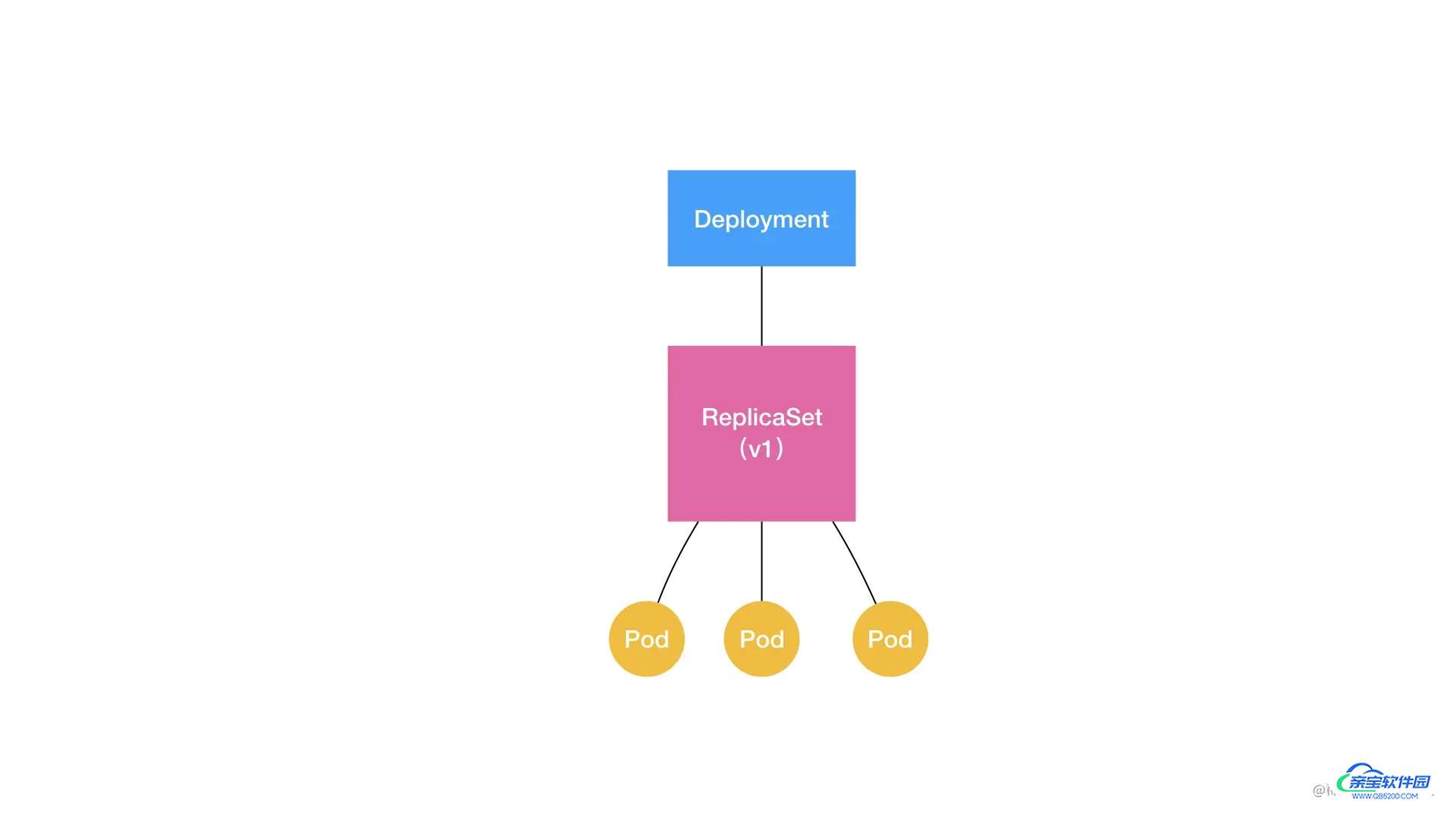
通过这张图,我们就很清楚的看到,一个定义了 replicas=3 的 Deployment,与它的 ReplicaSet,以及 Pod 的关系,实际上是一种“层层控制”的关系。
其中,ReplicaSet 负责通过“控制器模式”,保证系统中 Pod 的个数永远等于指定的个数(比如,3 个)。这也正是 Deployment 只允许容器的 restartPolicy=Always 的主要原因:只有在容器能保证自己始终是 Running 状态的前提下,ReplicaSet 调整 Pod 的个数才有意义。
而在此基础上,Deployment 同样通过“控制器模式”,来操作 ReplicaSet 的个数和属性,进而实现“水平扩展 / 收缩”和“滚动更新”这两个编排动作。
其中,“水平扩展 / 收缩”非常容易实现,Deployment Controller 只需要修改它所控制的 ReplicaSet 的 Pod 副本个数就可以了。
比如,把这个值从 3 改成 4,那么 Deployment 所对应的 ReplicaSet,就会根据修改后的值自动创建一个新的 Pod。这就是“水平扩展”了;“水平收缩”则反之。
而用户想要执行这个操作的指令也非常简单,就是 kubectl scale,比如:
$ kubectl scale deployment nginx-deployment --replicas=4 deployment.apps/nginx-deployment scaled
那么,“滚动更新”又是什么意思,是如何实现的呢?
接下来,我还以这个 Deployment 为例,来为你讲解“滚动更新”的过程。
首先,我们来创建这个 nginx-deployment:$ kubectl create -f nginx-deployment.yaml --record 注意,在这里,我额外加了一个–record 参数。它的作用,是记录下你每次操作所执行的命令,以方便后面查看。
然后,我们来检查一下 nginx-deployment 创建后的状态信息:
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx-deployment 3 0 0 0 1s
在返回结果中,我们可以看到四个状态字段,它们的含义如下所示。
- DESIRED:用户期望的 Pod 副本个数(spec.replicas 的值);
- CURRENT:当前处于 Running 状态的 Pod 的个数;
- UP-TO-DATE:当前处于最新版本的 Pod 的个数,所谓最新版本指的是 Pod 的 Spec 部分与 Deployment 里 Pod 模板里定义的完全一致;
- AVAILABLE:当前已经可用的 Pod 的个数,即:既是 Running 状态,又是最新版本,并且已经处于 Ready(健康检查正确)状态的 Pod 的个数。
可以看到,只有这个 AVAILABLE 字段,描述的才是用户所期望的最终状态。
而 Kubernetes 项目还为我们提供了一条指令,让我们可以实时查看 Deployment 对象的状态变化。这个指令就是 kubectl rollout status:
$ kubectl rollout status deployment/nginx-deployment Waiting for rollout to finish: 2 out of 3 new replicas have been updated... deployment.apps/nginx-deployment successfully rolled out
在这个返回结果中,“2 out of 3 new replicas have been updated”意味着已经有 2 个 Pod 进入了 UP-TO-DATE 状态。
Deployment 所控制的 ReplicaSet查看
继续等待一会儿,我们就能看到这个 Deployment 的 3 个 Pod,就进入到了 AVAILABLE 状态
此时,你可以尝试查看一下这个 Deployment 所控制的 ReplicaSet:
$ kubectl get rs NAME DESIRED CURRENT READY AGE nginx-deployment-3167673210 3 3 3 20s
如上所示,在用户提交了一个 Deployment 对象后,Deployment Controller 就会立即创建一个 Pod 副本个数为 3 的 ReplicaSet。这个 ReplicaSet 的名字,则是由 Deployment 的名字和一个随机字符串共同组成。
这个随机字符串叫作 pod-template-hash,在我们这个例子里就是:3167673210。ReplicaSet 会把这个随机字符串加在它所控制的所有 Pod 的标签里,从而保证这些 Pod 不会与集群里的其他 Pod 混淆。
而 ReplicaSet 的 DESIRED、CURRENT 和 READY 字段的含义,和 Deployment 中是一致的。所以,相比之下,Deployment 只是在 ReplicaSet 的基础上,添加了 UP-TO-DATE 这个跟版本有关的状态字段。
这个时候,如果我们修改了 Deployment 的 Pod 模板,“滚动更新”就会被自动触发。
修改 Deployment 有很多方法。比如,我可以直接使用 kubectl edit 指令编辑 Etcd 里的 API 对象。kubectl edit deployment/nginx-deployment
这个 kubectl edit 指令,会帮你直接打开 nginx-deployment 的 API 对象。然后,你就可以修改这里的 Pod 模板部分了。比如,在这里,我将 nginx 镜像的版本升级到了 1.9.1。
kubectl edit 指令编辑完成后,保存退出,Kubernetes 就会立刻触发“滚动更新”的过程。你还可以通过 kubectl rollout status 指令查看 nginx-deployment 的状态变化:
$ kubectl rollout status deployment/nginx-deployment Waiting for rollout to finish: 2 out of 3 new replicas have been updated... deployment.extensions/nginx-deployment successfully rolled out
这时,你可以通过查看 Deployment 的 Events,看到这个“滚动更新”的流程: kubectl describe deployment nginx-deployment
可以看到,首先,当你修改了 Deployment 里的 Pod 定义之后,Deployment Controller 会使用这个修改后的 Pod 模板,创建一个新的 ReplicaSet(hash=1764197365),这个新的 ReplicaSet 的初始 Pod 副本数是:0。
然后,在 Age=24 s 的位置,Deployment Controller 开始将这个新的 ReplicaSet 所控制的 Pod 副本数从 0 个变成 1 个,即:“水平扩展”出一个副本。
紧接着,在 Age=22 s 的位置,Deployment Controller 又将旧的 ReplicaSet(hash=3167673210)所控制的旧 Pod 副本数减少一个,即:“水平收缩”成两个副本。
如此交替进行,新 ReplicaSet 管理的 Pod 副本数,从 0 个变成 1 个,再变成 2 个,最后变成 3 个。而旧的 ReplicaSet 管理的 Pod 副本数则从 3 个变成 2 个,再变成 1 个,最后变成 0 个。这样,就完成了这一组 Pod 的版本升级过程。
像这样,将一个集群中正在运行的多个 Pod 版本,交替地逐一升级的过程,就是“滚动更新”。
在这个“滚动更新”过程完成之后,你可以查看一下新、旧两个 ReplicaSet 的最终状态:
$ kubectl get rs NAME DESIRED CURRENT READY AGE nginx-deployment-1764197365 3 3 3 6s nginx-deployment-3167673210 0 0 0 30s
其中,旧 ReplicaSet(hash=3167673210)已经被“水平收缩”成了 0 个副本。
这种“滚动更新”的好处是显而易见的。 比如,在升级刚开始的时候,集群里只有 1 个新版本的 Pod。如果这时,新版本 Pod 有问题启动不起来,那么“滚动更新”就会停止,从而允许开发和运维人员介入。而在这个过程中,由于应用本身还有两个旧版本的 Pod 在线,所以服务并不会受到太大的影响。
当然,这也就要求你一定要使用 Pod 的 Health Check 机制检查应用的运行状态,而不是简单地依赖于容器的 Running 状态。要不然的话,虽然容器已经变成 Running 了,但服务很有可能尚未启动,“滚动更新”的效果也就达不到了。
而为了进一步保证服务的连续性,Deployment Controller 还会确保,在任何时间窗口内,只有指定比例的 Pod 处于离线状态。同时,它也会确保,在任何时间窗口内,只有指定比例的新 Pod 被创建出来。这两个比例的值都是可以配置的,默认都是 DESIRED 值的 25%。
所以,在上面这个 Deployment 的例子中,它有 3 个 Pod 副本,那么控制器在“滚动更新”的过程中永远都会确保至少有 2 个 Pod 处于可用状态,至多只有 4 个 Pod 同时存在于集群中。这个策略,是 Deployment 对象的一个字段,名叫 RollingUpdateStrategy,如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
...
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
在上面这个 RollingUpdateStrategy 的配置中,maxSurge 指定的是除了 DESIRED 数量之外,在一次“滚动”中,Deployment 控制器还可以创建多少个新 Pod;而 maxUnavailable 指的是,在一次“滚动”中,Deployment 控制器可以删除多少个旧 Pod。
同时,这两个配置还可以用前面我们介绍的百分比形式来表示,比如:maxUnavailable=50%,指的是我们最多可以一次删除“50%*DESIRED 数量”个 Pod。
结合以上讲述,现在我们可以扩展一下 Deployment、ReplicaSet 和 Pod 的关系图了。
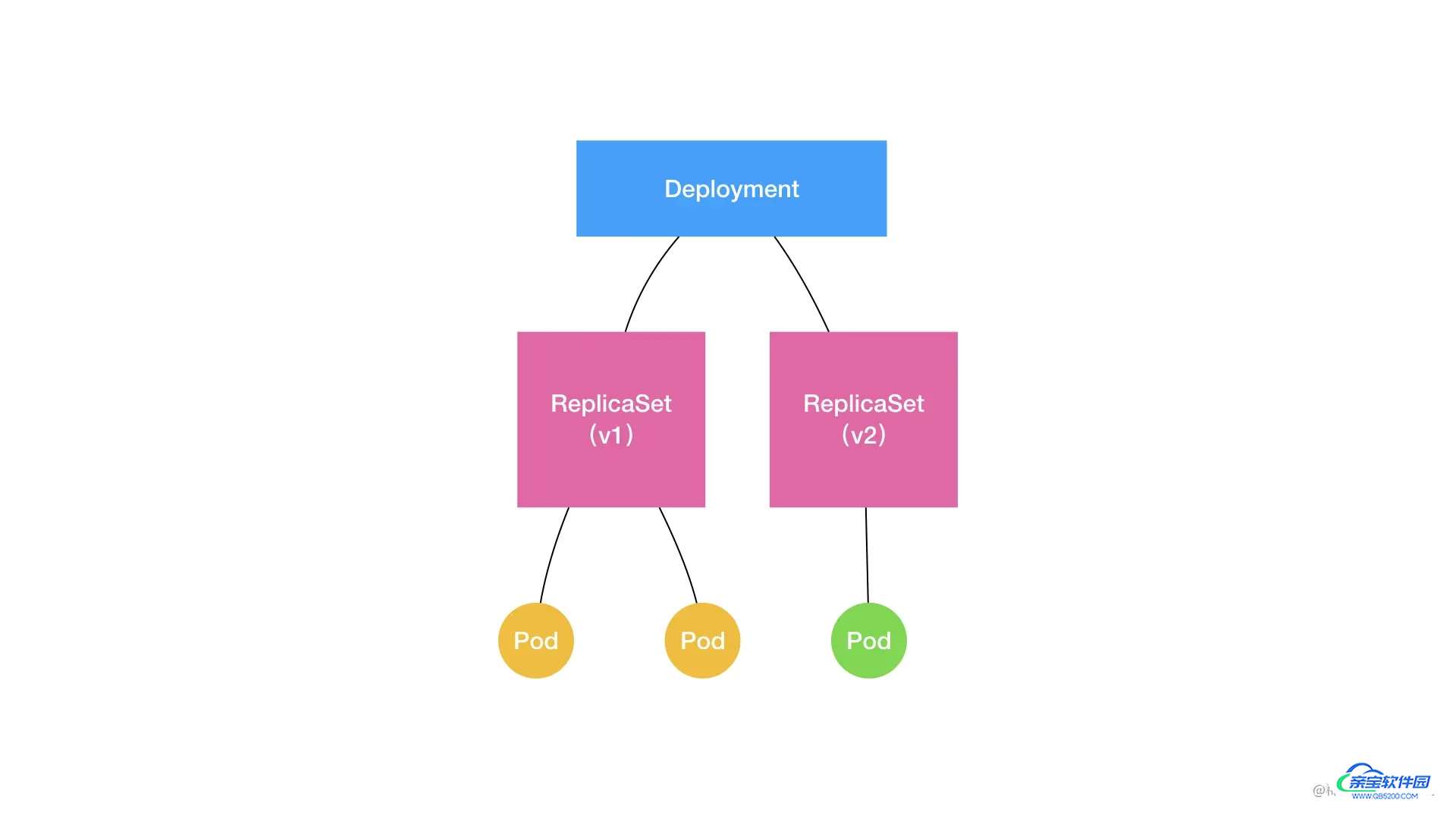
如上所示,Deployment 的控制器,实际上控制的是 ReplicaSet 的数目,以及每个 ReplicaSet 的属性。
而一个应用的版本,对应的正是一个 ReplicaSet;这个版本应用的 Pod 数量,则由 ReplicaSet 通过它自己的控制器(ReplicaSet Controller)来保证。
通过这样的多个 ReplicaSet 对象,Kubernetes 项目就实现了对多个“应用版本”的描述。
加载全部内容