C语言目标文件的详细讲解
叫我小秦就好了 人气:0前言
一个 C 语言程序经编译器和汇编器生成可重定位目标文件,再经链接器生成可执行目标文件。那么目标文件中存放的是什么?我们的源代码在经编译以后又是怎么存储的?
文章为 《深入理解计算机系统》的读书笔记,更为详细的内容可以阅读原书。
目标文件分类
目标文件有三种形式:
- 可重定位目标文件
包含二进制代码和数据,其形式可以在编译时与其他可重定位目标文件合并,创建一个可执行目标文件 - 可执行目标文件
包含二进制代码和数据,其形式可以被直接复制到内存并执行 - 共享目标文件
一种特殊可重定位目标文件,可以在加载或运行时被动态地加载进内存并链接
可重定位目标文件
下图为一个典型的 ELF 可重定位目标文件的格式。
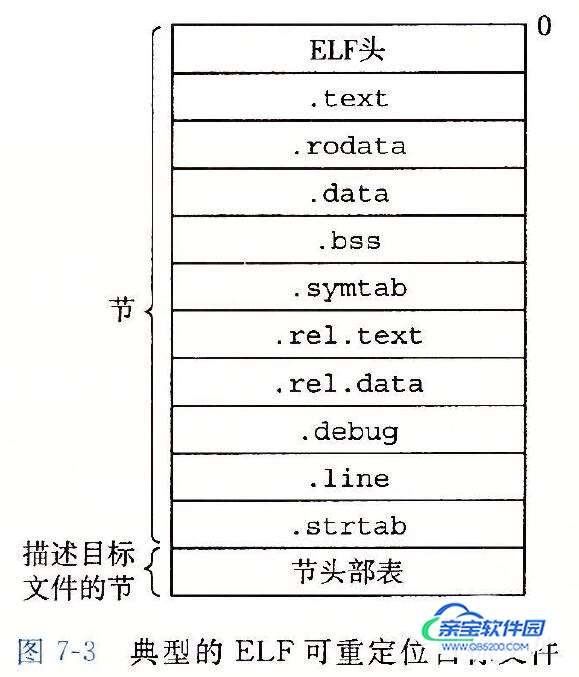
ELF 头以一个 16 字节的序列开始,这个序列包含了:生成该文件的系统的字的大小和字节顺序、目标文件的类型、机器类型、节头部表(也称段表)的文件偏移,以及节头部表中条目的大小和数量等。
节头部表是由描述文件中各个节的条目(entry)组成的数组。节头部表描述了文件中各个节在文件中的偏移位置及节的属性等,从节头部表里面可以得到每个节的所有信息。
- .text:已编译程序的机器代码
- .rodata:只读数据
- 比如 printf 语句中的格式串(%d\n)
- .data:已初始化的全局和静态 C 变量
- 局部 C 变量在运行时被保存在栈中,既不在 .data 节中,也不在 .bss 节中
- .bss:未初始化的全局和静态 C 变量,以及所有被初始化为 0 的全局或静态变量
- 目标文件格式区分已初始化和未初始化变量是为了空间效率:
- 未初始化变量不需要占据任何实际的磁盘空间,因为没有初始化,值没有意义,也就不必表示每个值
- .bss 段只是为未初始化全部变量和局部静态变量预留位置,它并没有内容,也不占据实际的空间,仅仅是个占位符
- .bss 段的大小存放在节头部表中
- 可以使用 readelf -S test 来查看 test 可执行程序节头部表
- 运行时,在内存中分配这些变量,并初始化为 0
- 目标文件格式区分已初始化和未初始化变量是为了空间效率:
- .symtab:一个符号表,它存放在程序中定义和引用的函数和全局变量的信息
- 包含局部静态变量
- 不包含局部非静态变量,这些符号在运行时在栈中被管理,链接器不关心这些
- .rel.text:一个 .text 节中位置的列表,当链接器把这个目标文件和其他文件组合时,需要修改这些位置
- .rel.data:被模块引用或定义的所有全局变量的重定位信息
- .debug:一个调试符号表,其条目是程序中定义的局部变量和类型定义,程序中定义和引用的全局变量,以及原始的 C 源文件
- 只有在编译时加入 -g 选项才会得到这张表
- .line:原始 C 源程序中的行号和 .text 节中机器指令之间的映射
- 只有在编译时加入 -g 选项才会得到这张表
- .strtab:一个字符串表,其中包含 .symtab 和 .debug 节中的符号表,以及节头部中的节名字
- 字符串表就是以 NULL 结尾的字符串序列
分段的优点
为什么要这么麻烦,把程序的指令和数据分开存放?
- 程序被装载进内存后,数据和指令分别被映射到两个虚拟区域
- 由于数据是可读写的,指令是只读的,权限可以分别设置成可读写和只读
- 可以防止程序指令被改写
- 对现代 CPU 而言缓存是极其重要的
- 数据区和指令区分离有利于提高程序的局部性,从而提高缓存命中率
- 启动多个相同进程时
- 可以共享一份指令,节省内存
符号和符号表
每个可重定位目标模块 m 都有一个符号表,它包含 m 定义和引用的符号的信息。在链接器的上下文中,有三种不同的符号:
- 由模块 m 定义并能被其他模块引用的全局符号
- 全局链接器符号对应于非静态的 C 函数和全局变量
- 由其他模块定义并被模块 m 引用的全局符号
- 这些符号称为外部符号,对应于在其他模块中定义的非静态 C 函数和全局变量
- 只被模块 m 定义和引用的符号
- 它们对应于带 static 属性的 C 函数和全局变量,这些符号在模块 m 中任何位置都可见,但是不能被其他模块引用
符号表是由汇编器用编译器输出到汇编语言 .s 文件中的符号构造的。.symtab 节中包含 ELF 符号表,这张符号表包含一个条目的数组。下面是 ELF 符号表条目格式:
typedef struct {
int name; // String table offset
char type:4, // Function or data (4 bits)
binding:4;// Local or global (4 bits)
char reserved; // Unused
short section; // Section header index
long value; // Section offset or absolute address
long size; // Object size in bytes
} Elf64_Symbol;
name 是字符串表中的字节偏移,指向符号的字符串名字。value 是符号的位置。对于可重定位目标文件,value 是距定义目标的起始位置的偏移。对于可执行目标文件,该值是一个绝对运行时地址。size 是目标的大小(以字节为单位)。
每个符号都被分配到目标文件的某个节,由 section 字段表示,该字段是一个到节头部表的索引。有三个特殊的的伪节,它们在节头部表中是没有条目的:
- ABS:代表不该被重定位的符号
- UNDEF:代表未定义的符号,也就是在本目标模块中引用,但定义在其他地方的符号
- COMMON:表示还未被分配位置的未初始化的数据目标
- 对于该类型符号,value 字段给出对齐要求,size 给出最小的大小
只有可重定位目标文件中才有伪节,可执行目标文件中是没有的。
GCC 将可重定位目标文件中的符号分配到 COMMON 和 .bss 的规则:
- COMMON:未初始化的全局变量
- .bss:未初始化的静态变量,以及初始化为 0 的全局或静态变量
符号解析
对于局部符号的解析是非常简单的,因为编译器只允许每个模块中每个局部符号有一个定义。不过,对全局符号的引用解析就麻烦的多。当编译器遇到一个不是在当前模块中定义的符号(变量或函数名)时,会假设该符号是在其他某个模块中定义的,生成一个链接器符号表条目,并把它交给链接器处理。
如果多个模块定义同名的全局符号,会发生什么呢?下面是 Linux 编译系统采用的方法。
在编译时,编译器向汇编器输出每个全局符号,或者是强或者是弱,汇编器把这个信息编码在可重定位目标文件的符号表里。函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号。
根据强弱符号的定义,Linux 链接器使用如下规则来处理多重定义的符号名:
- 不允许有多个同名强符号
- 如果有一个强符号和多个弱符号同名,选择强符号
- 如果有多个弱符号同名,从弱符号中任意选择一个
重定位
当汇编器生成一个目标模块时,它并不知道数据和代码最终将放在内存中的什么位置。它也不知道这个模块引用的任何外部定义的函数或者全局变量的位置。所以,无论何时汇编器遇到对最终位置位置的目标引用,它就会生成一个重定位条目,告诉链接器在将目标文件合并成可执行文件时如何修改这个引用。代码的重定位条目放在 .rel.text 中,已初始化数据的重定位条目放在 .rel.data 中。
下图为 ELF 重定位条目的格式:

符号解析完成后,代码中的每个符号引用和正好一个符号定义关联起来。此时,就可以开始重定位了。在重定位中,将合并输入模块,并为每个符号分配运行时地址。重定位由两步组成:
- 重定位节和符号定义
- 链接器将所有相同类型的节合并为同一类型的新的聚合节
- 链接器将运行时内存地址赋给新的聚合节,赋给输入模块定义的每个节,以及赋给输入模块定义的每个符号
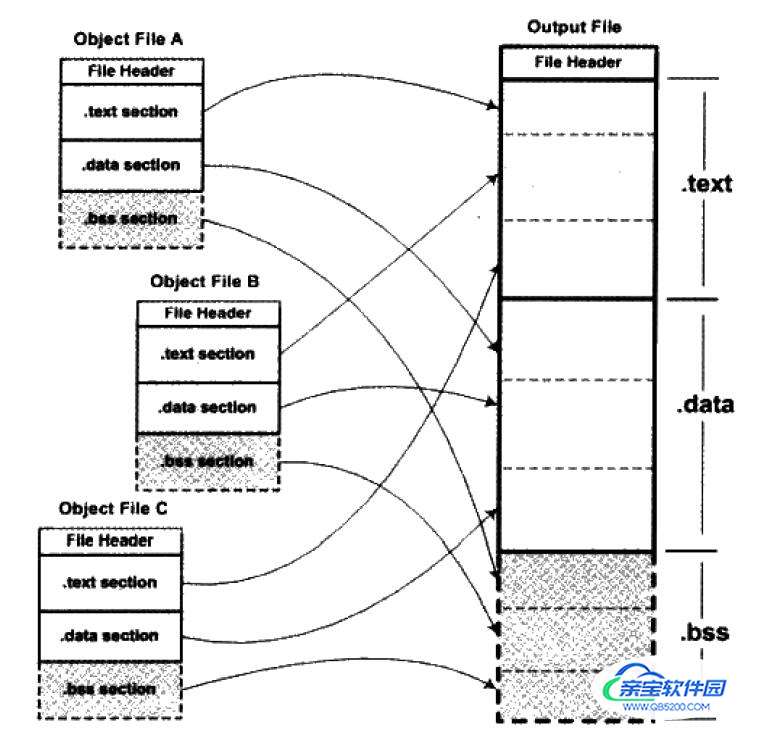
- 重定位节中的符号引用
- 链接器修改代码节和数据节中对每个符号的引用,使得它们指向正确的运行时地址
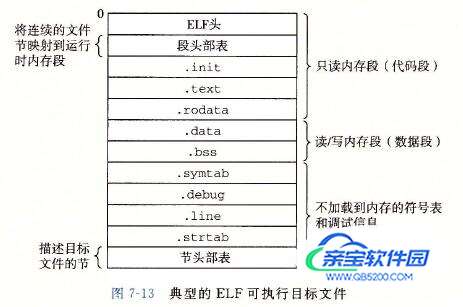
可执行目标文件
下图为一个典型的 ELF 可执行文件:
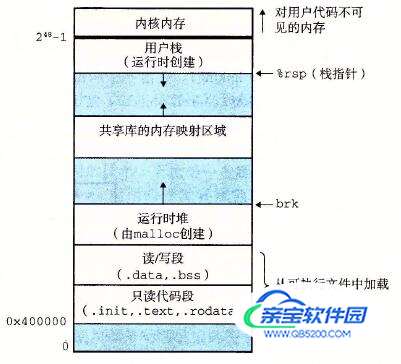
可执行文件加载到内存:
总结
加载全部内容
 爱之家商城
爱之家商城 氢松练
氢松练 Face甜美相机
Face甜美相机 花汇通
花汇通 走路宝正式版
走路宝正式版 天天运动有宝
天天运动有宝 深圳plus
深圳plus 热门免费小说
热门免费小说