Python中各类Excel表格批量合并问题的实现思路与案例
小小明-代码实体 人气:0在日常工作中,可能会遇到各类表格合并的需求。这类需求只要搞懂核心原理都很简单,本质都是万变不离其宗,相信大部分读者都能解决大部分需求。
基本思路:
- 遍历需要被合并的文件
- 读取数据,并合并数据(使用pandas最简单便捷)
- 保存数据
对样式无要求,使用Pandas对象直接写出
对样式有要求,使用openpyxl加载模板
要求样式与原始表格完全一致,使用VBA复制粘贴(本文未实现)
首先我们看下遍历文件比较简单的方法:
遍历文件示例
遍历当前目录下以xlsx为后缀的Excel,排除以~或r开头的文件:
from glob import glob
glob("[!~r]*.xlsx")['合并结果.xlsx', '多sheet表格合并.xlsx', '带表头样式合并.xlsx']
同时还想包含xls格式的文件:
glob("[!~r]*.xls*")['test.xls', '合并结果.xlsx', '多sheet表格合并.xlsx', '带表头样式合并.xlsx']
递归遍历当前文件夹,包含子文件夹:
glob("**/[!~r]*.xls*", recursive=True)['test.xls', '合并结果.xlsx', '多sheet表格合并.xlsx', '带表头样式合并.xlsx', 'Excel多sheet合并\\excel3.xlsx', 'Excel多sheet合并\\excel4.xlsx', 'Excel多sheet合并\\新建文件夹\\excel3.xlsx', 'Excel多sheet合并\\新建文件夹\\excel4.xlsx', 'Excel多sheet合并\\新建文件夹\\新建文件夹\\excel3.xlsx', 'Excel多sheet合并\\新建文件夹\\新建文件夹\\excel4.xlsx', '带样式合并\\HB区.xlsx', '带样式合并\\HN区.xlsx', '带样式合并\\XN区.xlsx', '带样式合并\\汇总表.xlsx']
递归遍历指定文件夹(例如搜索本机所有登录过的微信接收到的Excel文件):
import os
path = os.path.expanduser("~/Documents/WeChat Files")
glob(f"{path}/**/[!~r]*.xls*", recursive=True)
掌握了遍历文件的基本用法,我们就可以正式开始进行文件合并了:
无样式单文件合并示例
案例1:有一堆gzip压缩的csv文件,需要合并成新的csv文件
解压后的文本格式:

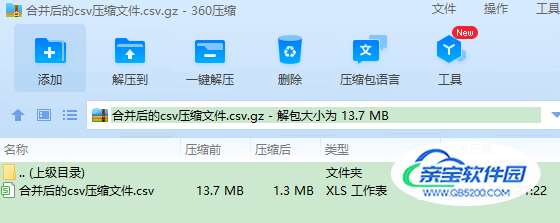
合并一堆gzip压缩的csv文件最终合并成一个gzip压缩的csv文件:
from glob import glob
import pandas as pd
dfs = [pd.read_csv(file, skiprows=1, sep="|", compression="gzip")
for file in glob("gzip/*.csv.gz")]
df = pd.concat(dfs, ignore_index=True)
df.to_csv("合并后的csv压缩文件.csv.gz", index=False, compression="gzip")
最终合并结果:
案例2:一堆csv文件,只取其中三列,表名不固定,但相对顺序一致
from glob import glob
import pandas as pd
import numpy as np
columns = ['Date_ID', 'erbs', 'EUtranCell']
dfs = [pd.read_csv(file, usecols=[0, 2, 3]).values for file in glob("csv/*.csv")]
df = pd.DataFrame(np.vstack(dfs), columns=columns)
df.to_csv("合并后的csv文件.csv", index=False)
案例3:一堆csv文件,列非常多,仅一列列名存在变动
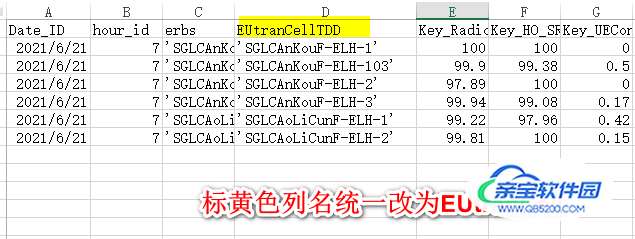
import pandas as pd
import glob
dfs = [
pd.read_csv(file).rename(
columns=lambda x:"EUtranCell" if x.startswith("EUtranCell") else x)
for file in glob.glob("csv/*.csv")
]
df = pd.concat(dfs, ignore_index=True)
df.to_csv("合并后的csv文件2.csv", index=False)
其他方法(一般不会这么写):
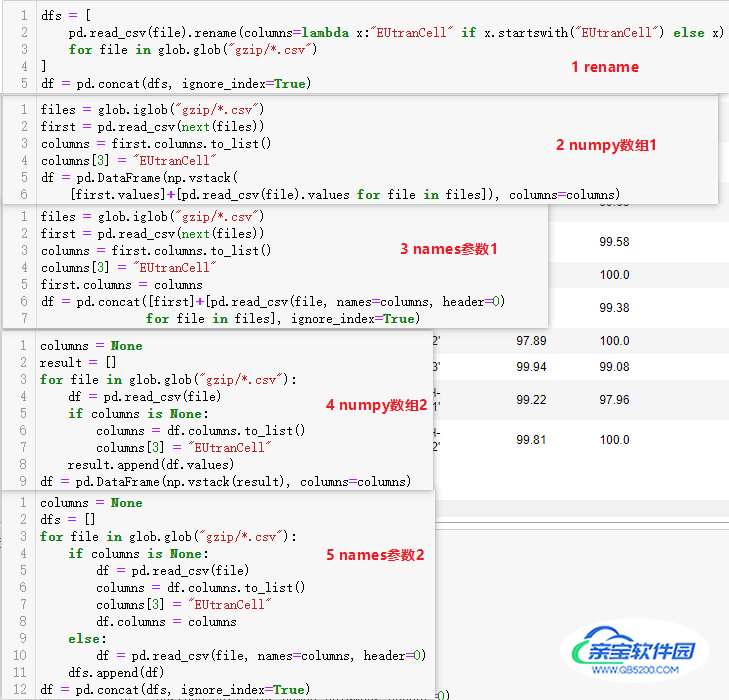
在预先能够定义好列名时,推荐以下两种写法:

案例4:寄存器数据处理并合并
需求说明:
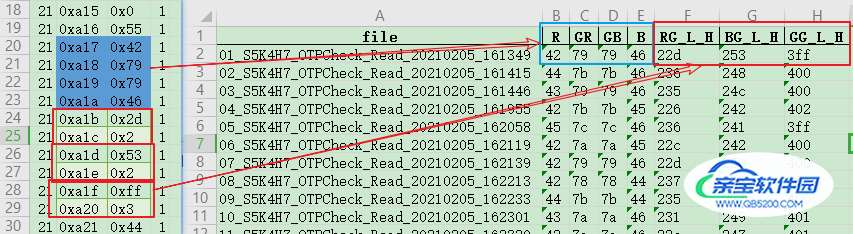
- 需要读取0xa17~0xa20这10个寄存器的数据,前4个寄存器数据保存到R,GR,RB,B这四列中
- 0xa1b~0xa20后6个寄存器,两两合并到RG_L_H,BG_L_H,GG_L_H这三列中
- 标识每行数据所读取的文件名
如下所示:
特殊情况:

为了方便获取文件名,我们使用pathlib来进行glob遍历:
import pandas as pd
from pathlib import Path
result = []
for file in Path("csv/PT0004B_LOG").glob("*.csv"):
df = pd.read_csv(file, header=None, usecols=[1, 2], index_col=0)
t = df[2].str[2:]
r = [str(file.name[:-4])]
r.extend(t.loc["0xa17":"0xa1a"].values)
r.extend(t.loc["0xa1c":"0xa20":2].values +
t.loc["0xa1b":"0xa20":2].str.zfill(2).values)
result.append(r)
df = pd.DataFrame(
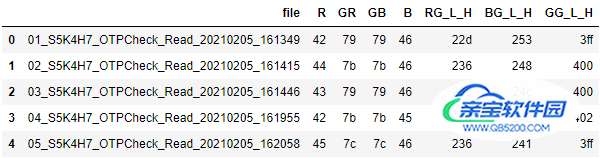
result, columns=["file", "R", "GR", "GB", "B", "RG_L_H", "BG_L_H", "GG_L_H"])
df.to_excel("combine.xlsx", index=False)
df.head()
无样式同名多sheet表格合并
如果只递归合并一个文件夹下的所有Excel的默认sheet,会非常简单,仅需4行代码搞定:
path = "Excel多sheet合并"
dfs = [pd.read_excel(file) for file in glob.glob(f"{path}/**/[!~]*.xls*", recursive=True)]
df = pd.concat(dfs, ignore_index=True)
df.to_excel("合并结果.xlsx", index=False)
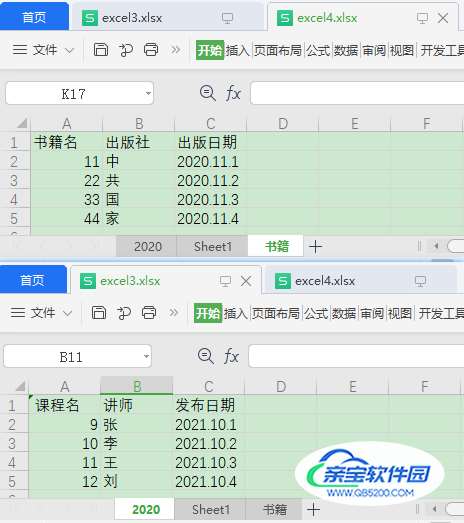
下面要求对一个文件夹下所有Excel表格,要求所有的sheet分别合并。
数据示例如下:
假设被合并的文件夹名称是Excel多sheet合并,合并代码如下:
import pandas as pd
from glob import glob
path = "Excel多sheet合并"
data = {}
for file in glob(f"{path}/**/[!~]*.xls*", recursive=True):
for name, df in pd.read_excel(file, sheet_name=None).items():
data.setdefault(name, []).append(df)
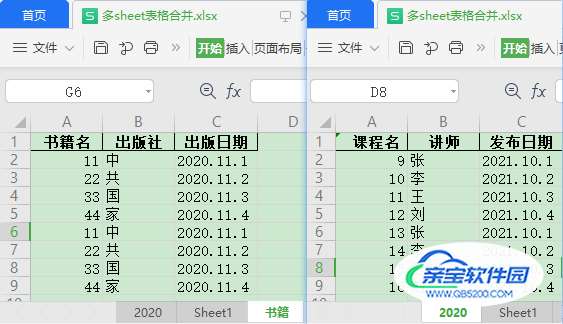
with pd.ExcelWriter("多sheet表格合并.xlsx") as write:
for name, dfs in data.items():
pd.concat(dfs).to_excel(write, name, index=False)
合并结果:
保留表头样式同名多sheet表格合并
如果要求完全带有原有样式合并会比较麻烦,本文就不作演示了,存在具体真实需求时再考虑单独开文。
需求说明:
有很多区域表:
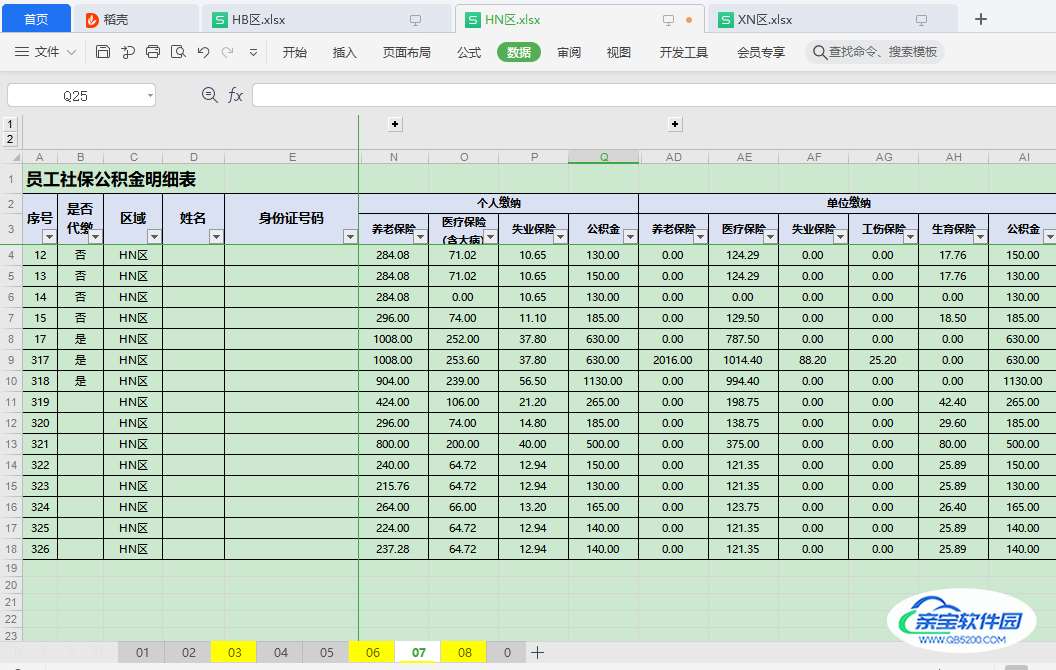
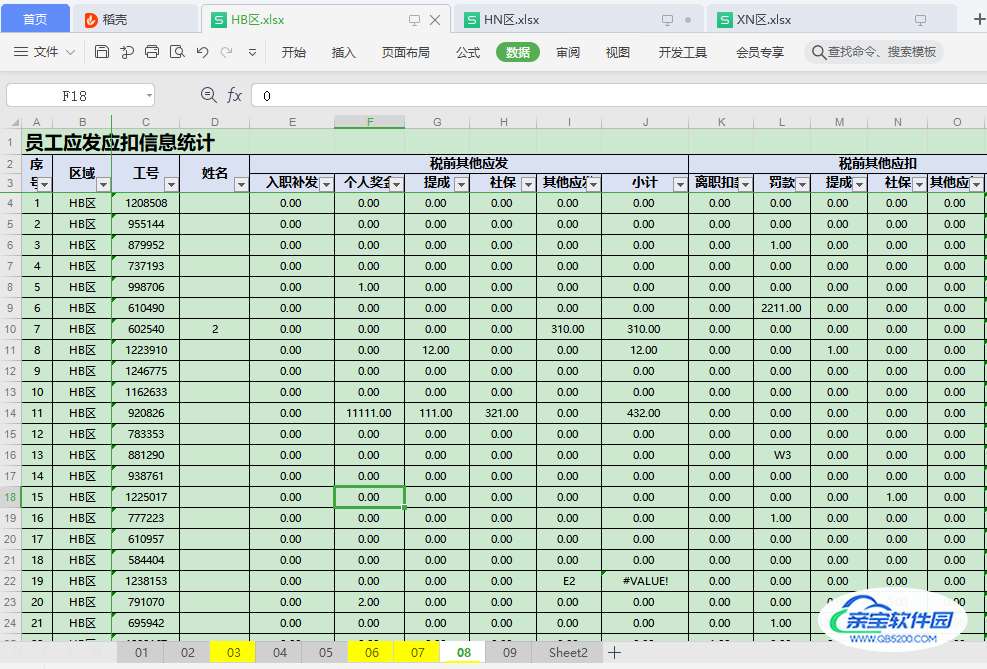
现在需要将每个区域的表格黄色的sheet合并到一张汇总表中。
为了保持表头样式的一致性,我们可以事先建立好模板,或者直接任选一个被合并的文件作为模板。
首先我们读取数据:
import pandas as pd
from glob import glob
path = "带样式合并"
# 定义被读取的sheet名和跳过的行数
sheet_start_num = {'03': 3, '06': 2, '07': 3, '08': 3}
data = {}
for file in glob(f"{path}/**/[!~r汇]*.xls*", recursive=True):
for sheet_name, skiprows in sheet_start_num.items():
excel = pd.ExcelFile(file)
df = excel.parse(sheet_name=sheet_name, skiprows=skiprows, header=None)
data.setdefault(sheet_name, []).append(df.values)
然后通过openpyxl加载模板,将数据写入各个子表中:
from openpyxl import load_workbook
workbook = load_workbook(filename="带样式合并/汇总表.xlsx")
for sheet_name, sheet_data in data.items():
sheet = workbook[sheet_name]
sheet.delete_rows(sheet_start_num[sheet_name] + 1, sheet.max_row)
for row in np.vstack(sheet_data).tolist():
sheet.append(row)
workbook.save(filename="带表头样式合并.xlsx")
最终就实现了带表头样式多sheet合并。
图形化界面选择指定的目录
如果我们希望将其做成图形化界面,可以使用tk的如下组件选择被合并的目录,或保存的位置:
from tkinter import filedialog filedialog.askdirectory(initialdir=".")
filedialog.asksaveasfilename(title="保存",
initialdir=".",
defaultextension="xlsx",
filetypes=[("Excel 工作簿", "*.xlsx"),
("Excel 97-2003 工作簿", "*.xls")])
我们以多Excel多Sheet合并为例,可以编写如下代码的py脚本:
from tkinter import filedialog
import pandas as pd
from glob import glob
path = filedialog.askdirectory(initialdir=".")
data = {}
for file in glob(f"{path}/**/[!~]*.xls*", recursive=True):
for name, df in pd.read_excel(file, sheet_name=None).items():
data.setdefault(name, []).append(df)
save_name = filedialog.asksaveasfilename(title="保存",
initialdir=".",
defaultextension="xlsx",
filetypes=[("Excel 工作簿", "*.xlsx"),
("Excel 97-2003 工作簿", "*.xls")])
with pd.ExcelWriter(save_name) as write:
for name, dfs in data.items():
pd.concat(dfs).to_excel(write, name, index=False)
也可以考虑使用Gooey工具转换为图形化界面:
from glob import glob
import pandas as pd
from gooey import Gooey, GooeyParser
def combine_excel(path, save_name):
data = {}
for file in glob(f"{path}/**/[!~]*.xls*", recursive=True):
for name, df in pd.read_excel(file, sheet_name=None).items():
data.setdefault(name, []).append(df)
with pd.ExcelWriter(save_name) as write:
for name, dfs in data.items():
pd.concat(dfs).to_excel(write, name, index=False)
@Gooey
def main():
parser = GooeyParser(description="多Excel多Sheet合并程序 - @小小明")
parser.add_argument('path', help="被合并的Excel文件目录", widget="DirChooser")
parser.add_argument('save_name', help="合并后保存的文件(以Excel文件形式保存)", widget="FileSaver")
args = parser.parse_args()
print("输入路径:", args.path)
print("保存位置:", args.save_name)
combine_excel(args.path, args.save_name)
print("合并完成!")
if __name__ == '__main__':
main()
还可以通过Gooey展示合并进度:
from glob import glob
import pandas as pd
from gooey import Gooey, GooeyParser
def combine_excel(path, save_name):
data = {}
files = glob(f"{path}/**/[!~]*.xls*", recursive=True)
for i, file in enumerate(files, 1):
for name, df in pd.read_excel(file, sheet_name=None).items():
data.setdefault(name, []).append(df)
yield f"合并进度:{i}/{len(files)}"
with pd.ExcelWriter(save_name) as write:
items = data.items()
for i, (name, dfs) in enumerate(items, 1):
pd.concat(dfs).to_excel(write, name, index=False)
yield f"保存进度:{i}/{len(items)}"
@Gooey(progress_regex=r"^..进度:(?P<current>\d+)/(?P<total>\d+)$",
progress_expr="current / total * 100",
timing_options={
'show_time_remaining': False,
'hide_time_remaining_on_complete': True,
})
def main():
parser = GooeyParser(description="多Excel多Sheet合并程序 - @小小明")
parser.add_argument('path', help="被合并的Excel文件目录", widget="DirChooser")
parser.add_argument('save_name', help="合并后保存的文件(以Excel文件形式保存)", widget="FileSaver")
args = parser.parse_args()
print("输入路径:", args.path)
print("保存位置:", args.save_name)
for msg in combine_excel(args.path, args.save_name):
print(msg)
print("合并完成!")
if __name__ == '__main__':
main()
加载全部内容