pytorch/transformers 最后一层不加激活函数的原因分析
浪漫的数据分析 人气:0pytorch/transformers 最后一层不加激活函数原因
之前看bert及其各种变种模型,发现模型最后一层都是FC (full connect)的线性层Linear层,现在讲解原因
实验:笔者试着在最后一层后加上了softmax激活函数,用来做多分类,发现模型无法收敛。去掉激活函数后收敛很好。
说明加的不对,因此深入研究了一下。
前言
对于分类问题,pytorch最后一层为啥都是linear层,没有激活函数?
一、原因在于损失方式CrossEntropy
CrossEntropy:该损失函数集成了log_softmax和nll_loss。因此,相当于FC层后接上CrossEntropy,实际上是有经过softmax处理的。只是内置到损失函数CrossEntropy中去了。
This criterion combines `log_softmax` and `nll_loss` in a single
function.二、为什么CrossEntropy要用log_softmax而不是softmax
1.查看CrossEntropy定义:
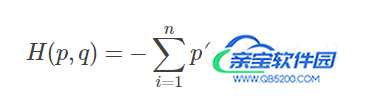
其中p为真实分布,q为预测分布。
根据CrossEntropyLoss公式,分类问题中,所以标签中只有一个类别(设为z)分量为1,其他类别全为0,我们代入公式,即求和之后只剩下一项。
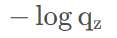
其中:
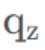
是模型FC层输出后需要接上softmax后,得到的概率。因此,这个公式就可以表示为:-log(softmax(FC的输出)),因此,这里就直接变成一个函数,叫log_softmax,便于计算CrossEntropy。
2.如果想要的到模型输出的概率值,需要在FC层输出后,人为的接上F.Softmax()就好了
代码如下(示例):
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
n_data = torch.ones(100,2)
x0 = torch.normal(2*n_data, 1)
y0 = torch.zeros(100)
x1 = torch.normal(-2*n_data, 1)
y1 = torch.ones(100)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # 组装(连接)
y = torch.cat((y0, y1), 0).type(torch.LongTensor)
x, y = Variable(x), Variable(y)
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.out = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.out(x)
return x
net = Net(2, 10, 2)
optimizer = torch.optim.SGD(net.parameters(), lr = 0.012)
for t in range(100):
out = net(x)
loss = torch.nn.CrossEntropyLoss()(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (t+1) % 20 == 0:
plt.cla()
prediction = torch.max(F.softmax(out), 1)[1] # 在第1维度取最大值并返回索引值
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:,1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
accuracy = sum(pred_y == target_y)/200
plt.text(1.5, -4, 'Accu=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
上述代码中,F.softmax(out)表示的就是模型输出的概率。
torch.max(F.softmax(out), 1)[1] # 在第1维度取表示取概率最大的列最为预测标签值,不是概率,而是标签了。
3.bert模型的输出端展示
代码如下(示例):
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
bert_out = self.bert(context, attention_mask=mask, output_hidden_states=False)
out = self.fc(bert_out.pooler_output)
return out也可以看到,bert中的self.fc = nn.Linear(config.hidden_size, config.num_classes)仅仅为Linear层,没有激活函数。
如果想得到bert的多分类概率,最后在模型的out输出后,需要接上一个
F.softmax(out)
总结
这里给大家解释一下为什么bert模型最后都不加激活函数。是因为损失函数选择的原因。
加载全部内容