React Streaming SSR原理示例深入解析
字节跳动终端技术 人气:0功能简介
React 18 提供了一种新的 SSR 渲染模式: Streaming SSR。通过 Streaming SSR,我们可以实现以下两个功能:
- Streaming HTML:服务端可以分段传输 HTML 到浏览器,而不是像 React 18 以前一样,需要等待服务端渲染完成整个页面后才返回给浏览器。这样,浏览器可以更快的启动 HTML 的渲染,提高 FP、FCP 等性能指标。
- Selective Hydration:在浏览器端 hydration 阶段,可以只对已经完成渲染的区域做 hydration,而不需要等待整个页面渲染完成、所有组件的 JS bundle 加载完成,才能开始 hydration。这样可以更早的对已经完成渲染的区域做事件绑定,从而让页面获得更好的可交互性。
基本原理
使用示例
React 官网给出的一个简单的使用示例(以 Node.js 环境下的 API 为例)如下:
let didError = false;
const stream = renderToPipeableStream(
<App />,
{
bootstrapScripts: ["main.js"],
onShellReady() {
// The content above all Suspense boundaries is ready.
// If something errored before we started streaming,
// we set the error code appropriately.
res.statusCode = didError ? 500 : 200;
res.setHeader('Content-type', 'text/html');
stream.pipe(res);
},
onShellError(error) {
// Something errored before we could complete the shell
// so we emit an alternative shell.
res.statusCode = 500;
res.send('<!doctype html><p>Loading...</p><script src="clientrender.js"></script>');
},
onAllReady() {
// stream.pipe(res);
},
onError(err) {
didError = true;
console.error(err);
}
}
);
renderToPipeableStream 是在 Node.js 环境下实现 Streaming SSR 的 API。
Streaming HTML
HTTP 支持以 stream 格式进行数据传输。当 HTTP 的 Response header 设置 Transfer-Encoding: chunked 时,服务器端就可以将 Response 分段返回。一个简单示例:
const http = require("http");
const url = require("url");
const sleep = (ms) => {
return new Promise((resolve) => {
setTimeout(resolve, ms);
});
};
const server = http.createServer(async (req, res) => {
const { pathname } = url.parse(req.url);
if (pathname === "/") {
res.statusCode = 200;
res.setHeader("Content-Type", "text/html");
res.setHeader("Transfer-Encoding", "chunked");
res.write("<html><body><div>First segment</div>");
// 手动设置延时,让分段显示的效果更加明显
await sleep(2000);
res.write("<div>Second segment</div></body></html>");
res.end();
return;
}
res.writeHead(200, { "Content-Type": "text/plain" });
res.end("okay");
});
server.listen(8080);
当访问 localhost:8080 时,「First segment」 和 「Second segment」会分 2 次传输到浏览器端,「First segment」先显示到页面上,2s 延迟后,「Second segment」再显示到页面上。

React 中的 Streaming HTML 要更加复杂。例如,对下面的 App 组件做 SSR:
//文件1: Content.js
export default function Content() {
return (
<div> This is content </div>
);
}
// 文件2:App.js
import { Suspense, lazy } from "react";
const Content = lazy(() => import("./Content"));
export default function App() {
return (
<html>
<head></head>
<body>
<div>App shell</div>
<Suspense>
<Content />
</Suspense>
</body>
</html>
);
}
第 1 次访问页面时,SSR 渲染的结果会分成 2 段传输,传输的第 1 段数据,经过格式化后,如下:
<!DOCTYPE html>
<html>
<head></head>
<body>
<div>App shell</div>
<!--$?-->
<template id="B:0"></template>
<!--/$-->
</body>
</html>
其中 template 标签的用途是为后续传输的 Suspense 的 children 渲染结果占位,注释 和 中间的内容,表示是异步渲染出来的。
传输的第 2 段数据,经过格式化后,如下:
<div hidden id="S:0">
<div> This is content </div>
</div>
<script>
function $RC(a, b) {
a = document.getElementById(a);
b = document.getElementById(b);
b.parentNode.removeChild(b);
if (a) {
a = a.previousSibling;
var f = a.parentNode,
c = a.nextSibling,
e = 0;
do {
if (c && 8 === c.nodeType) {
var d = c.data;
if ("/$" === d)
if (0 === e) break;
else e--;
else "$" !== d && "$?" !== d && "$!" !== d || e++
}
d = c.nextSibling;
f.removeChild(c);
c = d
} while (c);
for (; b.firstChild;) f.insertBefore(b.firstChild, c);
a.data = "$";
a._reactRetry && a._reactRetry()
}
};
$RC("B:0", "S:0")
</script>
id="S:0" 的 div 正是 Suspense 的 children 的渲染结果,但是这个 div 设置了 hidden 属性。接下来的 $RC 函数,会负责将这个 div 插入到第 1 段数据中 template 标签所在的位置,同时删除 template 标签。
总结一下
React Streaming SSR ,会先传输所有 以上层级的可以同步渲染得到的 html 结构,当 内的组件渲染完成后,会把这部分组件对应的渲染结果,连同一个 JS 函数再传输到浏览器端,这个 JS 函数会更新 dom ,得到最终的完整 HTML 结构。
当第 2 次访问页面时,html 结构会一次性返回,而不会分成 2 次传输。这时候 组件为什么没有将传输的数据分段呢?这是因为第 1 次请求时, Content 组件对应的 JS 模块在服务器端已经被加载到模块缓存中,再次请求时,加载 Content组件是一个同步过程,所以整个渲染过程是同步的,不存在分段传输渲染结果的情况。由此可见,只有当 的 children,需要被异步渲染时,SSR 返回的 HTML 才会被分段传输。
除了动态加载 JS 模块(code splitting)会产生分段传输数据的效果外,组件内获取异步数据则是更加常见的适用 Streaming SSR 的场景。
我们将 Content 组件做改造,通过调用异步函数 getData 获取数据:
let data;
const getData = () => {
if (!data) {
data = new Promise((resolve) => {
// 延迟 2s 返回数据
setTimeout(() => {
data = "content from remote";
resolve();
}, 2000);
});
throw data;
}
// promise-like
if (data && data.then) {
throw data;
}
const result = data;
data = undefined;
return result;
};
export default function Content() {
// 获取异步数据
const data = getData();
return <div>{data}</div>;
}
这样,Content 的内容会延迟 2s,待获取到 data 数据后传输到浏览器显示。示例代码(codesandbox 最近升级了,在 html 的 head 里注入了会阻塞 DOM 渲染的 JS,导致 Streaming SSR 效果可能失效,可以把代码复制到本地测试)。
注意:在数据未准备好前,getData 必须 throw 一个 promise,promise 会被 Suspense 组件捕获,这样才能保证 Streaming SSR 的顺利执行。
Selective Hydration
React 18 之前,SSR 实际上是不支持 code splitting 的,只能使用一些 workaround,常见的方式有:1. 对于需要 code splitting 的组件,不在服务端渲染,而是在浏览器端渲染;2. 提前将 code splitting 的 JS 写到 html script 标签中,在客户端等待所有的 JS 加载完成后再执行 hydration。
这一点 React Team 的 Dan 在 Suspense 的 RFC 中也有提及:
To the best of our knowledge, even popular workarounds forced you to choose between either opting out of SSR for code-split components or hydrating them after all their code loads, somewhat defeating the purpose of code splitting.
当前 Modern.js 对于这种情况的处理,采用的是第 2 种方式。Modern.js 利用 @loadable/component 在 SSR 阶段,收集做了 code splitting 的组件的 JS bundle,然后把这些 JS bundle 添加到 html script 标签中,@loadable/component 提供了一个 API loadableReady ,在等待 JS bundle 加载完成后,才执行 hydration 。示意代码如下:
loadableReady(function(){
hydrateRoot(root, <App/>)
})
如果在没有等待所有的 JS bundle 都加载完成,就开始 hydration,会出现什么问题呢?
考虑下面的例子,Content 组件做了 code splitting,如果在浏览端,在 Content 组件的 JS bundle 还未加载完成时,就开始 hydration,hydration 得到的 HTML 结构将缺少 Content 组件的内容,而服务端 SSR 返回的结构则是包含 Content 组件的,导致如下报错:
Hydration failed because the initial UI does not match what was rendered on the server.
import loadable from '@loadable/component'
const Content = loadable(() => import("./Content"));
export default function App() {
return (
<html>
<head></head>
<body>
<div>App shell</div>
<Content />
</body>
</html>
);
}
把上面的代码,用 React 18 的 lazy 和 Suspense 改写,就可以支持 Selective Hydration,使得 SSR 真正支持 code splitting:
import {lazy, Suspense} from 'react'
const Content = lazy(() => import("./Content"));
export default function App() {
return (
<html>
<head></head>
<body>
<div>App shell</div>
<Suspense>
<Content />
</Suspense>
</body>
</html>
);
}
如果 Content 组件的 JS bundle 还没有加载完成,在 hydration 阶段,渲染到 Suspense 节点时会跳出,而不会让整个 hydration 过程失败。
Selective Hydration 还有另外一种使用场景:同步导入 Content 组件(不做 code splitting),但是需要注意 Content 组件内仍然有异步的读取数据操作(见上文代码),另外增加一个 SideBar 组件,用于验证事件绑定,代码如下:
import {lazy, Suspense, useState} from 'react'
// 同步导入 Content 组件
import Content from './Content';
const Sidebar = () => {
const [color, setColor] = useState('black');
return (
<div className="home">
<div style={{ color }}>Siderbar</div>
<button
onClick={() => {
setColor(color === 'black' ? 'red' : 'black');
}}
>
change
</button>
</div>
);
};
export default function App() {
return (
<html>
<head></head>
<body>
<div>App shell</div>
<Sidebar />
<Suspense>
<Content />
</Suspense>
</body>
</html>
);
}
访问页面时,在渲染出 Content 组件前,Siderbar 就已经可以交互了(点击 change 按钮,文字颜色会改变)。说明,虽然所有组件使用一个 JS bundle 做 hydration,但是如果 Suspense 内的组件没有完成渲染,并不会影响其他已经渲染出的组件做 hydration。示例代码。
总结一 下,React 18 的 hydration 阶段,当渲染到 Suspense 组件时,会根据 Suspense 的 children 是否已经渲染完成,而选择是否继续向子组件执行 hydration。未渲染完成的组件待渲染完成后,会恢复执行 hydration。 Suspense 的 children 异步渲染的两种场景:1. children 组件做了 code splitting;2. children 组件中有异步操作。
降级逻辑
Streaming SSR 过程中,如果某个 Suspense 的 children 渲染过程抛出异常,那么这个 children 组件将降级到 CSR,即在浏览器端重新尝试渲染。
例如,我们对前面使用的 Content 组件做改造,刻意在服务端 SSR 阶段抛出异常:
export default function Content() {
const _data = getData();
// 制造异常
if(typeof window === 'undefined'){
data = undefined
throw Error('SSR Error')
}
return (
<div>
{_data}
</div>
);
}
访问页面时,Response 返回的第二段数据,格式化后如下所示:
<script>
function $RX(b, c, d, e) {
var a = document.getElementById(b);
b = a.previousSibling;
b.data = "$!";
a = a.dataset;
c && (a.dgst = c);
d && (a.msg = d);
e && (a.stck = e);
b._reactRetry && b._reactRetry()
};
$RX("B:0", "", "SSR Error", "\n at Content\n at Lazy\n at Content\n at Lazy\n at Suspense\n at body\n at html\n at App\n at DataProvider (/Users/bytedance/work/examples/stream-ssr-demo/src/data.js:18:23)")
</script>
第二段数据中返回了 RX 函数,而不是渲染正确情况下的 RX 函数,而不是渲染正确情况下的 RX 函数,而不是渲染正确情况下的 RC 函数。RX 会将渲染出错的Suspense在HTML中对应的Comment标签 <!−−RX 会将渲染出错的 Suspense 在 HTML 中对应的 Comment 标签 <!--RX 会将渲染出错的Suspense在HTML中对应的Comment标签 <!−−?--> 修改为 ,表示这个 Suspense 的 children 需要在浏览器端执行降级渲染。当执行 $RX 时,如果父组件已经完成 hydration,会调用 Comment 节点上的 _reactRetry 方法,立即执行对需要降级的组件的渲染;否则等待父组件执行时 hydration,再“顺道”执行渲染。
当 Suspense 的 children SSR 阶段渲染失败时,可以在 renderToPipeableStream 的 onError 回调中执行专门的逻辑处理,例如下面的例子中,会打印出错误日志,并将响应的状态码设置为 500。
如果还没有渲染到任一 Suspense 组件时,就发生了错误,这意味着应用对应的整棵组件树都没有渲染成功,SSR 完全失败,这个时候 onShellReady 不会被调用,onShellError 会调用,我们可以在 onShellError 中返回 CSR 使用的 HTML 模版,让整个应用完全降级到 CSR 。
let didError = false;
const stream = renderToPipeableStream(
<App assets={assets} />,
{
onShellReady() {
// If something errored before we started streaming, we set the error code appropriately.
res.statusCode = didError ? 500 : 200;
res.setHeader("Content-type", "text/html");
stream.pipe(res);
},
onError(x) {
didError = true;
console.error(x);
},
onShellError(x) {
didError = true;
res.send(<html>...</html>)//返回 CSR 使用的 HTML 模版,整棵组件树降级到 CSR
}
}
);
JS 和 CSS 设置
当前,我们还没有介绍如何在 Streaming SSR 中设置 JS 和 CSS 文件。有三种方式:
- 在 HTML 组件中设置示例如下:
function Html({ assets, children, title }) {
return (
<html>
<head>
<title>{title}</title>
<link rel="stylesheet" href={assets["main.css"]} />
<script src={assets["main.js"]}></script>
</head>
<body>
<noscript
dangerouslySetInnerHTML={{
__html: `<b>Enable JavaScript to run this app.</b>`
}}
/>
{children}
<script
dangerouslySetInnerHTML={{
__html: `assetManifest = ${JSON.stringify(assets)};`
}}
/>
</body>
</html>
);
}
function App({assets}) {
return (
<Html assets={assets} title="Hello">
{/* other components */}
</Html>
);
}
hydrateRoot(document, <App assets={window.assetManifest} />);
我们将 html、head、body 等这些标签也通过 React 组件表示,这样对 JS 和 CSS 的设置,也可以在 JSX 中完成。示例中,通过 assets 属性,设置 HTML 组件需要引人的 JS 和 CSS 文件。 SSR 阶段时,assets 一般是通过读取 webpack 等构建工具的构建产物结果得到的,assets 还会写入到一个 script 的assetManifest 变量上, 这样在 hydration 阶段,App 组件可以通过 window.assetManifest 获取到 assets 信息。
- 在返回第一段数据时添加这种方式下,html、head、body 等这些最外层标签,通过 HTML 模版注入到 Streaming SSR 返回的第一段数据中。 示例如下:
import { Transform } from 'stream';
// 代表传输的第一段数据
let isShellStream = true;
const injectTemplateTransform = new Transform({
transform(chunk, _encoding, callback) {
if (isShellStream) {
// headTpl 代表 <html><head>...</head><body><div id='root'> 部分的模版
// tailTpl 代表 </div></body></html> 部分的模版
this.push(`${headTpl}${chunk.toString()}${tailTpl}`));
isShellStream = false;
} else {
this.push(chunk);
}
callback();
},
});
const stream = renderToPipeableStream(
<App />,
{
onShellReady() {
res.setHeader('Content-type', 'text/html');
stream.pipe(injectTemplateTransform).pipe(res);
},
}
);
在构建阶段,将 HTML 所需的 JS 和 CSS 文件,构建到 html 模版中。然后通过创建一个 Transform 流,在传输第一段数据时,将 headTpl 、tailTpl 的 html 模版数据添加到第一段数据的两端。
- 通过参数 bootstrapScripts 设置通过 renderToPipeableStream 的第二个参数,设置 bootstrapScripts 的值,``bootstrapScripts` 的值为 HTML 所需的 JS 文件路径。注意,这种方式不支持设置 CSS 文件。 示例如下:
const stream = renderToPipeableStream(
<App />,
{
bootstrapScripts: ["main.js"],
onShellReady() {
res.setHeader('Content-type', 'text/html');
stream.pipe(res);
},
}
);
源码解析
数据结构
Streaming SSR 的实现,主要涉及 Segment、Boundary、Task 和 Request 4种数据结构。
Segment
代表 Streaming SSR 分段传输过程中的每段数据。
简化后的 Segment 类型及字段说明如下:
type Segment = {
// segment 状态。依次代表 pending、completed、flushed、aborted、errored
status: 0 | 1 | 2 | 3 | 4,
// 真正要传输到浏览器端的数据
chunks: Array<string | Uint8Array>,
// 子级 Segment,当遇到 Suspense Boundary 时会创建新的 Segment,
// 作为当前 Segment 的子级 Segment
children: Array<Segment>,
// 在父级 Segment 的 chunks 中的位置索引,如果没有父级 Segment, 则为 0
index: number,
// 如果这个 Segment 代表 Suspense 组件的 fallback,
// boundary 代表 Suspense 组件内部真正内容对应的 Boundary
boundary: null | SuspenseBoundary,
};
- status
新建时,状态为 pending;当 Segment 已经获取到需要传输的数据时,状态为 completed;当 Segment 的数据已经写入到 HTTP Response 对象时,状态为 flushed。
- children
当 React 解析到 Suspense 组件时,会创建新的 Segment,存储到当前 Segment 的 children 中。 例如以下 App 组件:
import { lazy } from 'react'
const Content = lazy(() => import('./Content' ));
function App = (props) => {
return (
<div>
<div>App</div>
<Suspense fallback={<Spinner />}>
<Content />
</Suspense>
</div>
)
}
React 会创建 3 个 Segment:
Segment 1 对应的 DOM 结构为:
<div> <div>App<div/> </div>
Segement 1 对应所有 Suspense 组件之上的内容,可以称为 Root Segment
Segment 2 对应 Spinner 组件渲染出的内容。同时 Segment 2 会存储到 Segment 1 的 children 属性中。
Segment 3 对应 Suspense 组件的 children 渲染出的内容。注意,因为被 Suspense 组件分割,Segment 3 的内容和 Segment 1 、Segment 2 的内容,在 HTTP 传输过程中,是分成 2 段传输的(也有可能是在 1 段中传输,后面会介绍),所以 Segment 3 并不会保存到 Segment 1 的 children中。
- index
继续考虑上面的例子,Segment 1 chunks 保存的数组元素,我们做一下简化,用以下 3 个元素示意:
[0]: <div> [1]: <div>App</div> [2]: </div>
Segment 2 chunks 中的数据,需要插入到 Segment 1 chunks 数组中的第 1 个元素之后的位置,才能保证传输的 dom 结构顺序是正确的,所以这个例子中 index 等于 2 。
Boundary
SSR 逻辑分段的“分界线”,每个 Suspense 组件对应 1 个 Suspense Boundary。
例如以下 App 组件有 2 个 Suspense 组件,会创建 2 个 Boundary,这 2 个 Boundary 实际上将整个组件的解析过程分成了 3 部分,Boundary 1 以上的部分,我们也可以视做一个 Boundary,称为 Root Boundary。
import { lazy } from 'react'
const Content = lazy(() => import('./Content' ));
const Comments = lazy(() => import('./Comments' ));
function App = (props) => {
return (
<div>
<div>App<div/>
{/* Boundary 1 */}
<Suspense fallback={<Spinner />}>
<Content />
{/* Boundary 2 */}
<Suspense fallback={<Spinner />}>
<Comments />
</Suspense>
</Suspense>
</div>
)
}
简化后的 Boundary ( React 代码中命名为 SuspenseBoundary)类型及字段说明如下:
type SuspenseBoundary = {
// 当前 boundary 范围内的 pending 状态的 task 数量
pendingTasks: number,
// 当前 boundary 范围内的已完成渲染的 Segment
completedSegments: Array<Segment>,
};
Task
1 个 Task 代表一个将组件树渲染成 DOM 结构的任务。一般情况下,一个应用对应一棵组件树,似乎一个应用只需要 1 个 Task 即可。但是,因为 Suspense 将组件树分成了多个子组件树,子组件树可以是异步处理的,所以实际上会需要多个 Task。
简化后的 Task 类型及字段说明如下:
type Task = {
// Task 对应的组件树
node: ReactNodeList,
// Task 对应的 Boundary
blockedBoundary: null | SuspenseBoundary,
// Task 对应的 Segment
blockedSegment: Segment,
// 后面介绍
ping: () => void,
}
blockedBoundary 的值可以为 null 或 SuspenseBoundary。 null 表示 task 代表所有 Suspense 组件之上的组件树的渲染任务,即 root task;
SuspenseBoundary 表示 task 代表某个 Suspense 组件内的组件树的异步渲染任务。
通过如下示例进一步说明:
import { lazy } from 'react'
const Content = lazy(() => import('./Content' ));
function App = (props) => {
return (
<div>
<div>App</div>
<Suspense fallback={<Spinner />}>
<Content />
</Suspense>
</div>
)
}
在 SSR 渲染开始时,会创建一个 Task,代表 App 作为根节点的组件树的渲染任务。这个 Task 的 Boundary 为 Root Boundary,所以为 null。
如果是第一次请求,因为 Content 组件做了 code splitting,所以 Content 组件代码的加载是异步的。这时会再创建 2 个 Task,一个为代表包裹 Content 组件的 React.lazy 为根节点的组件树的渲染任务;另一个为代表 Spinner 作为根节点的组件树的渲染任务。
这种情况,SSR 渲染结果会分成 2 次传输。
如果不是第一次请求,这是 Content 模块已经被加载到缓存中,再次加载不存在异步问题。此时,整个组件树的渲染是一个同步过程,也不需要使用 fallback 组件 Spinner ,所以只需要一个 Task 即可,即 App 作为根节点的 Task。
这种情况,SSR 渲染结果只需要 1 次传输。
Request
Request 是 SSR 逻辑中的最顶层对象。每 1 个 SSR 请求,会生成一个 Request 对象,存储这次 SSR 过程所需要的 Task、Boundary、Segement 等相关信息,以及 SSR 过程中不同时机的回调函数(onShellReady ,onAllReady ,onShellError,onError )。
简化后的 Request 类型及字段说明如下:
type Request = {
// 请求结果的输出流,即 Response 对象
destination: null | Destination,
// 所有未完成的 Task 数量,当等于 0 时,表示本次 SSR 完成,可以关闭 HTTP 连接
allPendingTasks: number,
// Root Boundary 范围内的未完成的 Task 数量,当等于 0 时,Root Boundary 渲染完成
pendingRootTasks: number,
// 等待执行的 Task
pingedTasks: Array<Task>,
// 已完成的 Root Segment
completedRootSegment: null | Segment,
// 已完成的 Boundary
completedBoundaries: Array<SuspenseBoundary>,
// Root Boundary 渲染完成后的回调
onShellReady: () => void,
// Root Boundary 渲染过程中,出错的回调
onShellError: (error: mixed) => void,
// 所有 Boundary 都渲染完成,即 SSR 完成的回调
onAllReady: () => void,
// Root Boundary 渲染完成后,在后续 Suspense Boundary 渲染过程中出错的回调
onError: (error: mixed) => ?string,
};
主要流程
renderToPipeableStream 涉及的关键函数调用过程如下图所示:
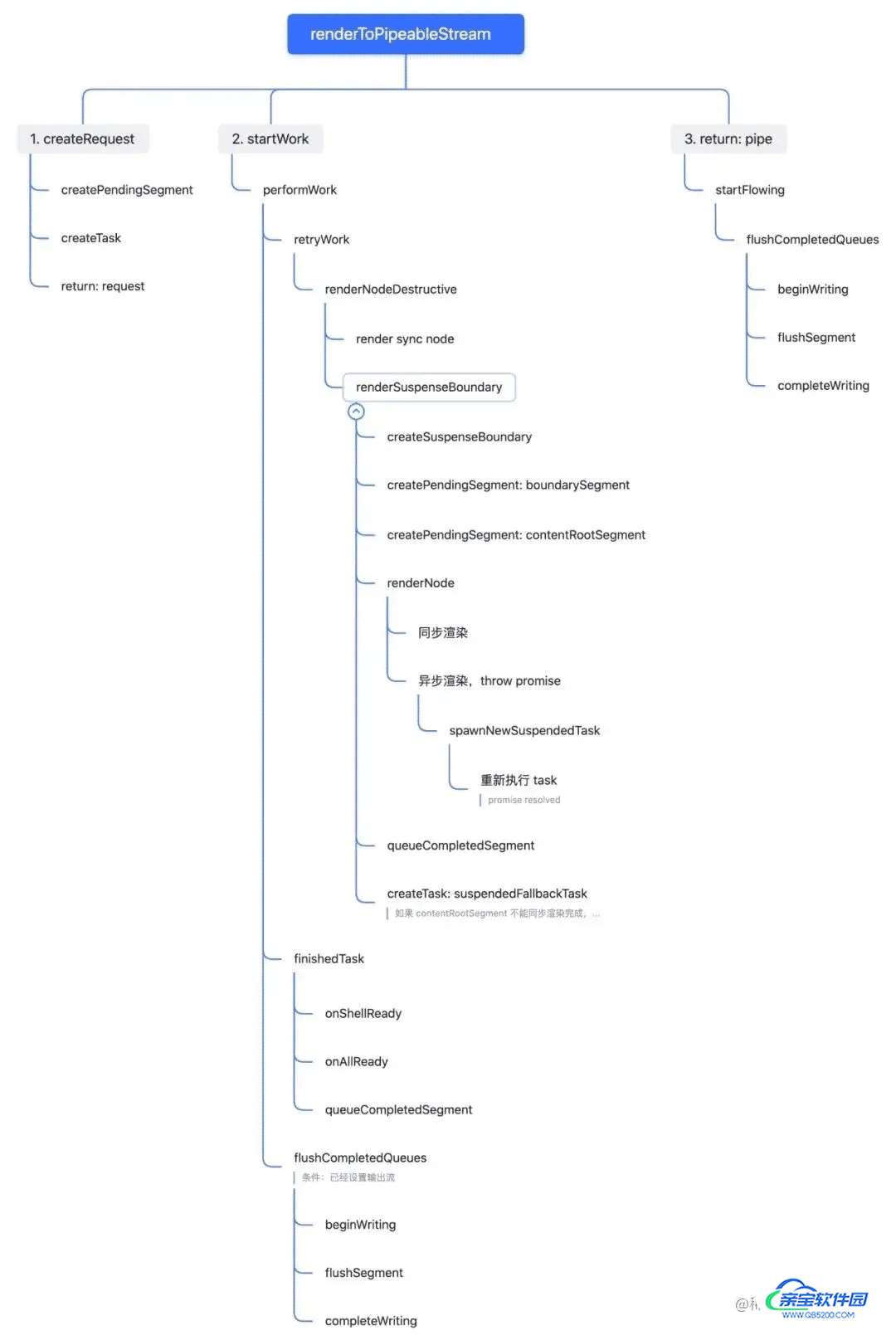
renderToPipeableStream 的关键代码如下:
function renderToPipeableStream(
children: ReactNodeList,
options?: Options,
): PipeableStream {
// 创建请求对象 Request
const request = createRequest(children, options);
// 启动组件树的渲染任务
startWork(request);
return {
pipe<T: Writable>(destination: T): T {
// 开始将渲染结果写入输出流
startFlowing(request, destination);
return destination;
},
abort(reason: mixed) {
abort(request, reason);
},
};
}
为了便于理解主干流程,本节列出的 React 源码,做了大量删减和微调,并非完整源码。
完整源码请参考:ReactDOMFizzServerNode.js 、ReactFizzServer.js、 ReactServerStreamConfigNode.js 等文件。
分析上面的代码调用过程,我们把 SSR 过程分为三个阶段:
创建请求对象创建请求对象即创建 Request 数据结构,对应 createRequest ,主要逻辑为:a. 根据入参 options ,创建 request 对象,设置 onShellReady 、onAllReady 等回调函数b. 创建 root segment,关联的 boundary 为 root boundary,即 nullc. 根据入参 children 和 root segment,创建 root taskd. 将 root task 保存到 request 的 pingedTasks 中,root task 将作为后续渲染操作的起点
export function createRequest(
children: ReactNodeList,
options?: Options,
): Request {
const pingedTasks = [];
const request = {
// 初始化 request
};
// This segment represents the root fallback.
const rootSegment = {
status: PENDING,
index: 0,
chunks: [],
children: [],
};
const rootTask = createTask(
request,
children,
null,
rootSegment
);
pingedTasks.push(rootTask);
return request;
}
Root task 由createTask 创建,创建 task 时,需要设置 task 关联的待渲染的组件树( node )、 Boundary( blockedBoundary ) 和 Segement ( blockedSegment ),同时还需要修改 request和 blockedBoundary 关联的待完成的 task 数量。
createTask 简化后的代码及注释如下:
function createTask(
request: Request,
node: ReactNodeList,
blockedBoundary: Root | SuspenseBoundary,
blockedSegment: Segment,
): Task {
// allPendingTasks 自增 1
request.allPendingTasks++;
// 如果是 root boundary, pendingRootTasks 自增1;
// 否则把对应 boundary 范围里的 pendingTask 自增1
if (blockedBoundary === null) {
request.pendingRootTasks++;
} else {
blockedBoundary.pendingTasks++;
}
// 创建 task,ping 的作用后续介绍
const task: Task = ({
node,
ping: () => pingTask(request, task),
blockedBoundary,
blockedSegment,
}: any);
return task;
}
2、启动渲染流程创建好 root task 后,就可以以 root task 作为起点,启动组件的渲染流程了,对应 startWork 。
主要逻辑可以从 startWork 内部调用performWork 开始看:
export function performWork(request: Request): void {
const pingedTasks = request.pingedTasks;
let i;
for (i = 0; i < pingedTasks.length; i++) {
const task = pingedTasks[i];
retryTask(request, task);
}
pingedTasks.splice(0, i);
if (request.destination !== null) {
flushCompletedQueues(request, request.destination);
}
}
performWork遍历 request 的pingedTasks,对每一个 task 执行 retryTask 。retryTask 主要逻辑如下:
- 通过调用 renderNodeDestructive ,对 task 包含的 React node 节点执行渲染逻辑。
- 如果renderNodeDestructive 执行过程中没有抛出异常:a. 表示 task 关联的渲染任务完成,将 task 关联的 segment 状态设置为完成状态。b. 调用 finishedTask ,对 request 上的 segment 信息做更新:如果是 root boundary 的task,将当前 task 关联的 segment 赋值给 request 的completedRootSegment ;如果是 suspense boundary,将当前 task 关联的 segment 添加到关联 boundary 的 completedSegments。注意,onShellReady 回调也是在这个函数中执行的,当 root boundary 上的 task 都已经执行完成(request.pendingRootTasks === 0),就会调用onShellReady 。
- 如果renderNodeDestructive 执行过程中抛出异常(主要针对 throw promise 场景):a. 捕获异常,如果是 promise-like 对象,在 promise resolve 后,把当前 task 重新放到 request 的 pingedTask 中,等待重新执行(调用 performWork )。
retryTask 主要代码如下:
function retryTask(request: Request, task: Task): void {
const segment = task.blockedSegment;
try {
renderNodeDestructive(request, task, task.node);
segment.status = COMPLETED;
finishedTask(request, task.blockedBoundary, segment);
} catch (x) {
resetHooksState();
if (typeof x === 'object' && x !== null && typeof x.then === 'function') {
// Something suspended again, let's pick it back up later.
const ping = task.ping;
x.then(ping, ping);
}
}
}
3.a 步骤中,需要依赖 12行的 task.ping 把 task 重新放回 request 的pingedTasks。
task.ping 对应函数:() => pingTask(request, task),pingTask 实现如下:
function pingTask(request: Request, task: Task): void {
const pingedTasks = request.pingedTasks;
pingedTasks.push(task);
scheduleWork(() => performWork(request));
}
renderNodeDestructive 对 task 的 node 属性代表的组件树,做 深度优先 遍历,一边将组件渲染为 dom 节点,一边将 dom 节点的信息存储到 task 的 blockedSegment 属性中。
Streaming SSR 实现的一个关键,是对Suspense组件的渲染逻辑。当 renderNodeDestructive 遍历到 Suspense 组件时,会调用renderSuspenseBoundary 执行渲染逻辑。
renderSuspenseBoundary 的主要逻辑为:
- 针对解析到的 Suspense 组件,创建一个新的 Boundary:newBoundary
- 新建一个 segment:boundarySegment, boundarySegment用于保存 Suspense 的 fallback 代表的内容,所以boundarySegment 的 boundary 属性值为 newBoundary 。同时, boundarySegment 也会保存到当前 task 的 blockedSegment的 children 属性中(可参考介绍 Segment 数据结构的例子)。
- 新建一个 segment:contentRootSegment ,保存 Suspense组件的children 代表的内容。
- 渲染 Suspense组件的children
- 如果渲染成功,说明 Suspense组件的 children没有需要异步等待的内容(渲染是同步完成的):a. 设置contentRootSegment 的状态为 COMPLETEDb. 把 contentRootSegment存入newBoundary的completedSegments属性中
- 如果渲染过程 throw promise,说明 Suspense的 children 有需要异步等待的内容:a. 新建一个 task,task 的blockedBoundary等于 newBoundaryb. 当 promise resolve 后,将 task 保存到 request 的 pingedTasks 中(通过 task 的ping属性),等待下一个事件循环处理。c. 再新建一个 task,代表Suspense 的 fallback 组件树的渲染任务, task 的blockedSegment 等于 boundarySegment,task 的blockedBoundary 等于调用 renderSuspenseBoundary时的 task.blockedBoundary (不是 newBoundary,是 newBoundary 上一层级的 boundary)d. 把 task 保存到 request的 pingedTasks 中,等待在 performWork 中处理
这段逻辑比较复杂,简单理解的话,在渲染过程中,每当遇到 Suspense 组件,就会创建一个新的 Boundary,但新 Boundary 并不意味着一定要创建一个新的 Task,因为Suspense组件内元素的渲染不一定需要异步完成,只有存在 动态导入组件(React.lazy)或获取异步数据等情况,才会创建一个新的 Task,用以表示这个异步的渲染过程。
上面的过程还有 2 个注意点:
- 步骤 6.a 中,新建的 task 不会立即放入 request的 pingedTasks 中,而是要等待代表异步任务的 promise resolve 后,才放入pingedTasks。所以pingedTasks ,实际上保存的是「没有异步任务依赖」的 task,是可以同步完成组件渲染工作的 task。
- 步骤 5 中, 没有 6.c 和 6.d 两步, 因为如果 Suspense 的 children 没有需要异步等待的内容,就不需要展示 fallback 内容,自然也不需要新建一个 task 负责 fallback 组件树的渲染任务 。
3、启动输出流
renderToPipeableStream 返回 pipe 和 abort 2 个方法,分别用于向输出流写入组件树的渲染结果,和终止本次 SSR 请求。这里我们主要分析向输出流写入组件树的渲染结果。pipe 内部调用startFlowing,startFlowing 调用 flushCompletedQueues,flushCompletedQueues顾名思义,会将已完成的组件树的渲染信息,写入到输出流(Response)。
flushCompletedQueues 主要逻辑为:
- 检测 root boundary 范围的 tasks 是否已经渲染完成,如果是,则将对应的 segments 写入输出流;如果否,则返回(因为需要保证写入输出流的第一段数据,一定是 root boundary 范围内的组件的渲染结果)
- 检查 suspense boundaries ,如果 suspense boundary 满足条件:关联的所有 task 都已经完成, 则将 suspense boundary 的 segment 写入输出流,suspense boundary 的完整内容在浏览器页面处于可见状态(不再显示 suspense 的 fallback 内容)。
- 继续检查 suspense boundaries,如果 suspense boundary 满足条件:存在完成的 task,但不是所有 task 都完成,则将这些完成的 task 的 segment 写入输出流,但 suspense boundary 的完整内容在浏览器页面仍然处于隐藏状态(包裹内容的 div 此时还是 hidden 状态)。
- 如果所有 suspense boundaries 的关联的 task 都已经完成,说明本次 SSR 完成, 调用 close 结束请求。
flushCompletedQueues 简化后的代码如下:
function flushCompletedQueues(
request: Request,
destination: Destination,
): void {
// 1.开始:root boundary 写入到输出流
beginWriting(destination);
let i;
const completedRootSegment = request.completedRootSegment;
if (completedRootSegment !== null) {
// 将 root boundary 范围内的组件渲染结果写入输出流
if (request.pendingRootTasks === 0) {
flushSegment(request, destination, completedRootSegment);
request.completedRootSegment = null;
writeCompletedRoot(destination, request.responseState);
} else {
// root boundary 范围内,还存在没有完成的 task,直接返回。
// 不需要继续向下看 suspense boundary 是否完成
return;
}
}
// 1.完成:root boundary 写入到输出流
completeWriting(destination);
// 2.开始:suspense boundary(关联的 task 已全部完成)写入到输出流
beginWriting(destination);
const completedBoundaries = request.completedBoundaries;
for (i = 0; i < completedBoundaries.length; i++) {
const boundary = completedBoundaries[i];
if (!flushCompletedBoundary(request, destination, boundary)) {
request.destination = null;
i++;
completedBoundaries.splice(0, i);
return;
}
}
completedBoundaries.splice(0, i);
// 2.完成:suspense boundary(关联的 task 已全部完成)写入到输出流
completeWriting(destination);
// 3.开始:suspense boundary(关联的 task 部分完成)写入到输出流
beginWriting(destination);
const partialBoundaries = request.partialBoundaries;
for (i = 0; i < partialBoundaries.length; i++) {
const boundary = partialBoundaries[i];
if (!flushPartialBoundary(request, destination, boundary)) {
request.destination = null;
i++;
partialBoundaries.splice(0, i);
return;
}
}
partialBoundaries.splice(0, i);
// 3.完成:suspense boundary(关联的 task 部分完成)写入到输出流
completeWriting(destination);
if (
request.allPendingTasks === 0 &&
request.pingedTasks.length === 0 &&
request.clientRenderedBoundaries.length === 0 &&
request.completedBoundaries.length === 0
) {
// 所有渲染任务都已完成,关闭输出流
close(destination);
}
}
上面的代码中,一共有 3 组 beginWriting / completeWriting ,分别代表了 flushCompletedQueues 的前 3 步骤。
至此,我们就完成了 Streaming SSR 主要源码实现的分析。
加载全部内容