关于SSD目标检测模型的人脸口罩识别
Mabel-mql 人气:0最近学习了SSD算法,了解了其基本的实现思路,并通过SSD模型训练自己的模型。
基本环境
- torch1.2.0
- Pillow8.2.0
- torchvision0.4.0
- CUDA版本可查看自己电脑,这里使用CUDA10.0
- visual studio 2019
- scipy1.2.1
- numpy1.17.0
- matplotlib3.1.2
- opencv_python4.1.2.30
- tqdm4.60.0
- h5py2.10.0
安装
建议创建一个虚拟环境,本文使用到的是在Pycharm环境下
打开pytorch的官方安装方法:
http://pytorch.org/get-started/previous-versions/
但是可以先进入:
https://download.pytorch.org/whl/torch_stable.html
找到自己需要下载自己需要的即可。
找到自己的下载路径,然后再命令窗口定位,再使用
pip install +下载好的whl文件即可
再安装相关依赖包需要先激活环境,进行安装。
同时安装CUDA和visual studio 2019可参考网上教程,这里不细讲。
数据集的准备
本文使用VOC格式进行训练,
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中,文件格式为xml。
图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中,格式为jpg,如下图所示。
数据集处理
整个项目的文件如下(里面包含一些个人测试的代码):
第一步需要运行voc_annotation.py,并更改其代码里面的一些参数(annotation_mode、classes_path、trainval_percent、train_percent、VOCdevkit_path都可以修改,但也可以只修改以下内容即可):

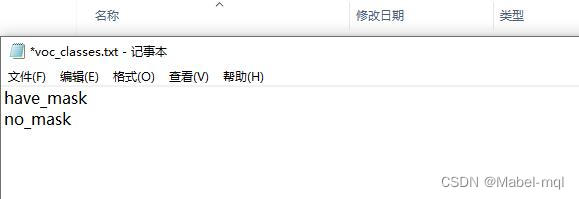
需要修改model_data文件里面的voc_classes.txt内容,例如本例中修改如下:
即可生成训练用的2007_train.txt以及2007_val.txt。
图片处理
本例统一输入进来的图片是300*300大小的3通道图片。
- 对输入进来的图片进行判断是否为RGB,如果不是则进行转RGB
- 对图像进行统一大小裁剪,为防止图片失真,在其添加上灰条。
- 对图片进行数据增强,通过翻转,随机选取等操作。
模型训练
训练文件train.py中也要修改部分参数

classes_path一定要对应自己的分类文件,以及自己权重文件的位置。经过多次epochs后,权值会生成在logs文件夹。
在训练开始前还需要更改其他py文件的内容:
在summary.py文件中:
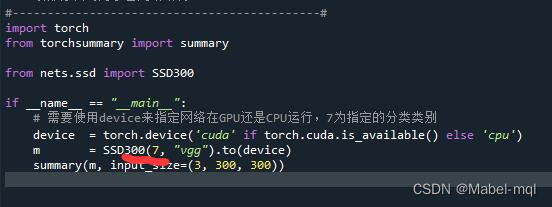
m=SSD300(7,‘vgg’).to(device)中7代表的是分类的个数,这里需要修改为2,因为只本例只分为了2类。
下面(3,300,300)代表输入的是300*300大小的3通道图片。
运行train.py文件进行模型训练,若出现out of memory问题,可以减小每次训练的batch_size的大小。
模型预测
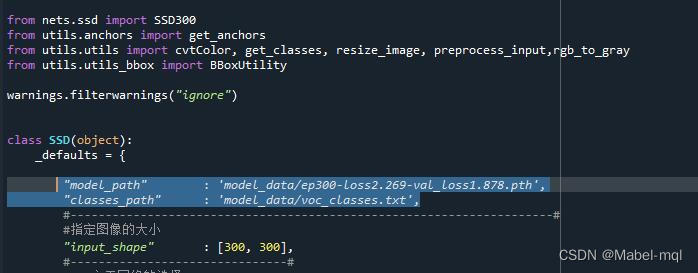
模型预测先要去修改ssd.py文件中的model_path(在自己保存权值的logs文件当中选取一个权值文件,放到model_data文件夹中,并修改下面的路径,其次classes_path也要进行对应的修改:
这里单独调用摄像头进行预测,相关代码如下所示:
import time
import cv2
import numpy as np
from PIL import Image
from ssd import SSD
#口罩识别模型
if __name__ == "__main__":
ssd = SSD()
video_path = 0
video_save_path = ""
video_fps = 25.0
# 指定测量fps的时候,图片检测的次数
test_interval = 100
capture=cv2.VideoCapture(video_path)
if video_save_path!="":
fourcc = cv2.VideoWriter_fourcc(*'XVID')
size = (int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)), int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)))
out = cv2.VideoWriter(video_save_path, fourcc, video_fps, size)
ref, frame = capture.read()
if not ref:
raise ValueError("未能正确读取摄像头(视频),请注意是否正确安装摄像头(是否正确填写视频路径)。")
fps = 0.0
while(True):
t1 = time.time()
# 读取某一帧
ref, frame = capture.read()
if not ref:
break
# 格式转变,BGRtoRGB
frame = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
# 转变成Image
frame = Image.fromarray(np.uint8(frame))
# 进行检测
frame = np.array(ssd.detect_image(frame))
# RGBtoBGR满足opencv显示格式
frame = cv2.cvtColor(frame,cv2.COLOR_RGB2BGR)
fps = ( fps + (1./(time.time()-t1)) ) / 2
print("fps= %.2f"%(fps))
frame = cv2.putText(frame, "fps= %.2f"%(fps), (0, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow("video",frame)
if video_save_path!="":
out.write(frame)
if cv2.waitKey(10) & 0xff==ord('q'):
break
capture.release()
cv2.destroyAllWindows()效果图如下
未戴口罩
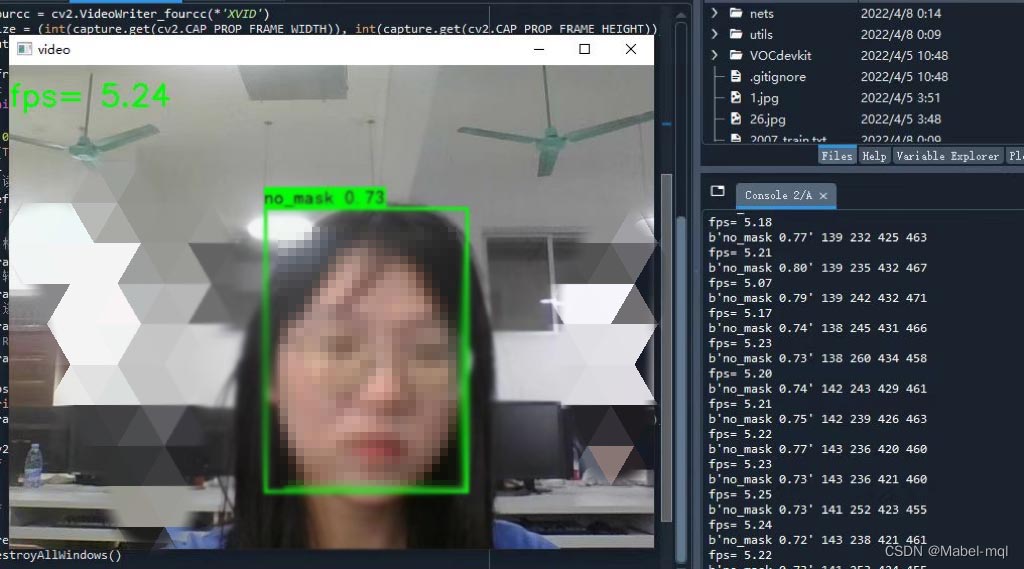
戴口罩

整体来说效果还是不错的。
后续
后面我又去找了其他数据集进行训练,对其进行不同的图片处理以及模型的改进,达到的效果还不错。但是图片格式为jpeg的,因此在代码当中添加了对图片类型的判断,但是若不添加代码,则需要更改文件
get_map.py中:
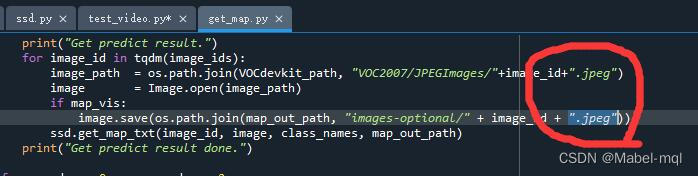
后缀为对应的图片类型,还有在voc_annotation.py代码中有一处也需要修改图片后缀名。
其次自己写了一个简易版的GUI界面,使其输出各坐标,以及害虫的分类
效果图如下:

但在模型对小目标检测方面还是存在一点问题,正在尝试提高其精度。
建议还是要先去学习下SSD模型的基本算法思路,理解起来更加清楚、明白.
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容