Seata AT模式前后镜像是如何生成详解
梦想实现家_Z 人气:0前言
在Seata官网中,我们可以知道AT模式一阶段的处理流程如下:
1.解析 SQL:得到 SQL 的类型(UPDATE),表(product),条件(where name = 'TXC')等相关的信息。
2.查询前镜像:根据解析得到的条件信息,生成查询语句,定位数据。
3.执行业务 SQL。
4.查询后镜像:根据前镜像的结果,通过 主键 定位数据。
5.插入回滚日志:把前后镜像数据以及业务 SQL 相关的信息组成一条回滚日志记录,插入到 UNDO_LOG 表中
......
前镜像的作用是保证在分布式事务失败时能够成功回滚的重要依据,后镜像是在回滚前校验是否脏写的数据依据,那么我们一阶段的前后镜像在真实的代码实现中是如何生成的呢?
前后镜像的生成
为了能够探寻到前后镜像的生成原理,我们需要看一看seata源码。最终我们把入口定位到AbstractDMLBaseExecutor.executeAutoCommitFalse()方法:
protected T executeAutoCommitFalse(Object[] args) throws Exception {
// 获取前镜像
TableRecords beforeImage = beforeImage();
// 执行业务SQL
T result = statementCallback.execute(statementProxy.getTargetStatement(), args);
// 获取后镜像
TableRecords afterImage = afterImage(beforeImage);
// 存储前后镜像
prepareUndoLog(beforeImage, afterImage);
return result;
}
前镜像
继续深入探究一下到底是怎么获取beforeImage的,根据源码来看,我们发现beforeImage()方法有很多实现:
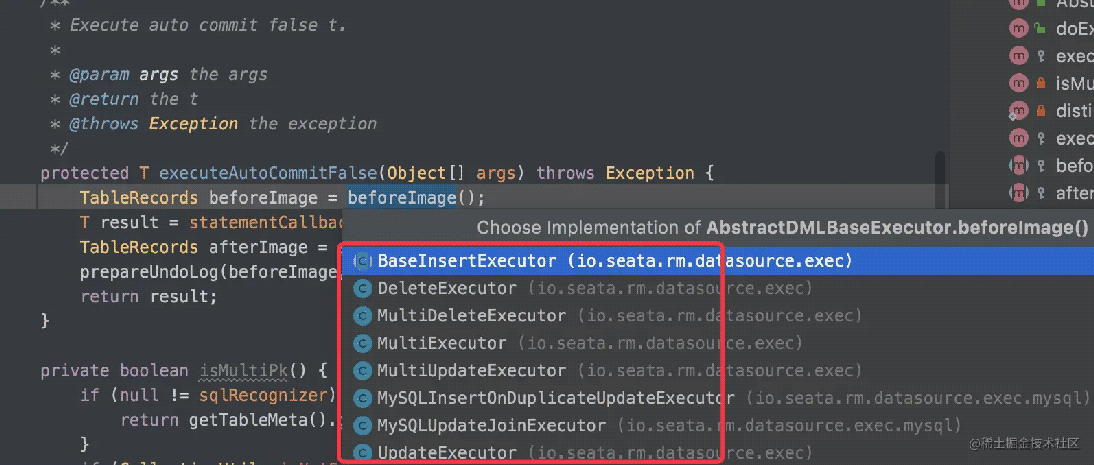
也就是说,Seata会根据不同的业务SQL来生成beforeImage,有点经验的小伙伴能够看出,这里其实使用到了模版模式加上策略模式,我们挑一个DeleteExecutor来看一下:
@Override
protected TableRecords beforeImage() throws SQLException {
SQLDeleteRecognizer visitor = (SQLDeleteRecognizer) sqlRecognizer;
// 根据表名解析出元数据
TableMeta tmeta = getTableMeta(visitor.getTableName());
ArrayList<List<Object>> paramAppenderList = new ArrayList<>();
// 生成查询beforeImage的SQL语句
// SELECT [列名,] FROM [表名] (别名) (WHERE) (ORDER BY) (LIMIT) FOR UPDATE
String selectSQL = buildBeforeImageSQL(visitor, tmeta, paramAppenderList);
// 执行SQL查询beforeImage
return buildTableRecords(tmeta, selectSQL, paramAppenderList);
}
1.关键原理就是根据业务SQL反向查询出被影响的数据;
2.为了保证查询到的数据不是快照数据,一定要记得加上FOR UPDATE;
另外的话,我们发现其实UpdateExecutor的前镜像生成方式和DeleteExecutor也差不多,像普通的insert这种SQL的前镜像就更简单了:
@Override
protected TableRecords beforeImage() throws SQLException {
return TableRecords.empty(getTableMeta());
}
因为普通insert语句不存在任何前镜像,所以直接返回空记录;
后镜像
我们再来看一下后镜像是如何生成的,这次我们看一下UpdateExecutor的后镜像生成方法afterImage():
@Override
protected TableRecords afterImage(TableRecords beforeImage) throws SQLException {
// 获取元数据
TableMeta tmeta = getTableMeta();
// 没有前镜像,也不存在后镜像,说明没有数据被修改
if (beforeImage == null || beforeImage.size() == 0) {
return TableRecords.empty(getTableMeta());
}
// 生成查询后镜像SQL
// SELECT [列名,] FROM [表名] (别名) WHERE 主键 in (前镜像的主键值)
// 这里面有一个配置项[client.undo.onlyCareUpdateColumns],是否只关心被修改的列名,默认是true
String selectSQL = buildAfterImageSQL(tmeta, beforeImage);
ResultSet rs = null;
try (PreparedStatement pst = statementProxy.getConnection().prepareStatement(selectSQL)) {
SqlGenerateUtils.setParamForPk(beforeImage.pkRows(), getTableMeta().getPrimaryKeyOnlyName(), pst);
// 执行查询后镜像
rs = pst.executeQuery();
// 包装查询结果
return TableRecords.buildRecords(tmeta, rs);
} finally {
IOUtil.close(rs);
}
}
后镜像的生成原理与前镜像的生成原理差不多,不过还是有一些小小的区别的:
1.后镜像的查询条件使用的是前镜像对应的主键值,就没有用业务SQL的查询条件;不同的Executor处理方式不同,需要根据具体的业务SQL来区分;
2.查询后镜像的SQL没有使用FOR UPDATE加锁,直接拿的快照数据;
小结
通过对seata源码的分析,我们现在已经了解了前后镜像的生成原理了:
1.通过业务SQL来判断SQL语句的类型,从而选择不同的Executor来获取前后镜像;
2.前镜像是通过业务SQL的查询条件,并加上FOR UPDATE来查询业务SQL执行前的数据;(不同的Executor实现不同)
3.后镜像是在业务SQL执行完毕后,根据前镜像内的主键数据来获取的数据;(不同的Executor实现不同)
4.通过前后镜像的多种实现可以判断出seata AT模式所支持的SQL语句的所有类型;
加载全部内容