基于Python预测一下世界杯最后赢家
俊欣 人气:0那么四年一度的世界杯即将要在卡塔尔开幕了,对于不少热爱足球运动的球迷来说,这可是十分难得的盛宴,而对于最后大力神杯的归属,相信很多人都满怀着期待,每个人心中都有不同的答案。
今天小编就通过Python数据分析以及机器学习等方式来预测一下谁能获得最后的冠军,当然最后预测出来的结果也仅仅只是作为一种参考,并不代表最后真实的结果。
数据集的准备
这里我们用到的数据集是来自kaggle的公开数据集,其中的一份数据集是2018年俄罗斯世界杯每小组各成员交手的记录,最后小编的预测基于该份数据集的基础之上,另外一份数据集则是从1870年开始到2022年截止,所有参赛球队的历史交手成绩汇总。那么我们首先导入要用到的模块以及导入数据集。
模块和数据集的导入
数据分析和可视化要用到的模块分别是pandas、matplotlib以及seaborn,而机器学习预测要用到的模块是sklearn,代码如下
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import matplotlib.ticker as ticker from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression
接着我们导入数据集
world_cup = pd.read_csv("World_Cup_2018_Dataset.csv")
results = pd.read_csv("results.csv")我们可以通过head()方法来查看导入数据及的前几行,校验一下数据的导入是否成功,代码如下
world_cup.head()
output

探索性数据分析和特征工程
接下来我们要做的便是探索性数据分析和特征工程了,来对数据集有一个大致的了解,同时生成一些针对最后的预测大有帮助的特征出来,例如我们针对比赛当中的比分来判断比赛是谁胜谁负,或者是平局,代码如下
winner = []
for i in range(len(results["home_team"])):
if results["home_score"][i] > results["away_score"][i]:
winner.append(results["home_team"][i])
elif results["home_score"][i] < results["away_score"][i]:
winner.append(results["away_team"][i])
else:
winner.append("Draw")
results["winning_team"] = winner
results["goal_difference"] = np.absolute(results["home_score"] - results["away_score"])
results.head()output
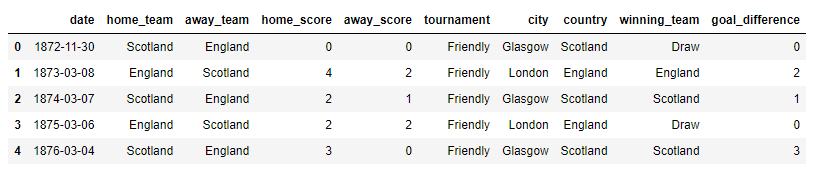
紧接着我们针对某个单独的国家,统计历史过往中所有比赛的胜负率情况,例如小编比较喜欢阿根廷队,就筛选出阿根廷队的历史战绩,代码如下
df = results[(results["home_team"] == "Argentina") | (results["away_team"] == "Argentina")] argen = df.iloc[:] argen.head()
output

那么同时我们也知道第一届世界杯举办的时间是1930年在乌拉圭举办的,那么筛选出在1930年之后的所有比赛的成绩,代码如下
year = [] for row in argen['date']: year.append(int(row[:4])) argen["match_year"] = year argen_1930 = argen[argen.match_year >= 1930] argen_1930.head()
output

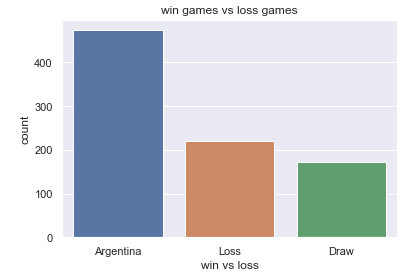
我们将比赛的结果的统计可视化出来,其中我们就能清晰地看到阿根廷球队的胜负率的情况,代码如下
x = ["Argentina","Loss","Draw"]
y = [474, 220, 173]
sns.barplot(x, y)
plt.title("win games vs loss games")
plt.xlabel("win vs loss")
plt.ylabel("count")
plt.show()output
俄罗斯世界杯的参赛队伍
我们先将目标锁定在2018年俄罗斯世界杯的参赛队伍上,总共是以下这几支球队
world_cup_russia = ["Australia", "Iran", "Japan", "Korea Republic", "Saudi Arabia", "Egypt", "Morocco", "Nigeria", "Senegal", "Tunisia", "Costa Rica", "Mexico", "Panama", "Argentina", "Brazil", "Colombia", "Peru", "Uruguay", "Belgium", "Croatia", "Denmark", "England", "France", "Germany", "Iceland", "Poland", "Portugal", "Russia", "Serbia", "Spain", "Sweden", "Switzerland"]
然后我们筛选出来这32支球队的过往的比赛成绩,代码如下
df_team_home = results[results['home_team'].isin(world_cup_russia)] df_team_away = results[results['away_team'].isin(world_cup_russia)] df_teams = pd.concat((df_team_home, df_team_away)) df_teams.drop_duplicates(inplace=True) df_teams.tail()
output

我们着重看的是1930年之后的比赛记录,那么我们再进行一次筛选,代码如下
year = [] for row in df_teams["date"]: year.append(int(row[:4])) df_teams["match_year"] = year df_teams_1930 = df_teams[df_teams.match_year >= 1930] df_teams_1930.head()
output

当然我们在最后进行预测的时候,会有一些无关紧要的特征掺杂其中,我们需要将其去掉,代码如下
df_teams_1930 = df_teams.drop(['date', 'home_score', 'away_score', 'tournament', 'city', 'country', 'goal_difference', 'match_year'], axis=1) df_teams_1930.tail()
output
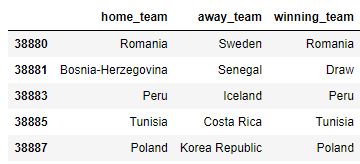
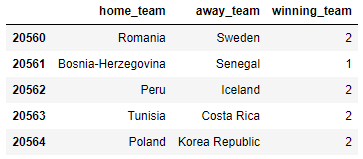
我们需要将winning_team这一列的标签做一次转换,将赢得比赛的标签改为2,输掉比赛的标签改为0,而平局的标签改为1,代码如下
df_teams_1930 = df_teams_1930.reset_index(drop=True) df_teams_1930.loc[df_teams_1930.winning_team == df_teams_1930.home_team,'winning_team']=2 df_teams_1930.loc[df_teams_1930.winning_team == 'Draw', 'winning_team']=1 df_teams_1930.loc[df_teams_1930.winning_team == df_teams_1930.away_team, 'winning_team']=0 df_teams_1930.tail()
output
紧接着,我们需要对这些离散类型的变量进行独热编码,用到的是pandas模块当中的get_dummies()方法,代码如下
# convert home team and away team from categorical variables to continous inputs # Get dummy variables final = pd.get_dummies(df_teams_1930, prefix=['home_team', 'away_team'], columns=['home_team', 'away_team']) final.head()
output

划分出训练集和测试集,调用的是train_test_split()方法,代码如下
# Separate X and y sets
X = final.drop(['winning_team'], axis=1)
y = final["winning_team"]
y = y.astype('int')
# Separate train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=42)逻辑回归算法
那小编这里调用的是非常简单的逻辑回归的算法,读者朋友后续也可以尝试其他的分类算法进一步的完善一下整个预测的流程与结果,代码如下
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
score = logreg.score(X_train, y_train)
score2 = logreg.score(X_test, y_test)
print("Training set accuracy: ", '%.3f'%(score))
print("Test set accuracy: ", '%.3f'%(score2))预测结果
那么最后便是将我们训练出来的模型去做一个预测了,我们先前的数据集当中有主队和客队之分,但是在世界杯的赛场上没有,这里我们就依据世界排名的先后顺序来划分一下,因此需要导入世界排名的数据集
# 导入新的数据集,各球队的世界排名
ranking = pd.read_csv('datasets/fifa_rankings.csv')
# 2018年俄罗斯世界杯的对阵情况
fixtures = pd.read_csv('datasets/fixtures.csv')
pred_set = []在数据集当中插入主队和客队排名的字段,代码如下
# 插入两个新的字段,主队和客队排名的字段
fixtures.insert(1, 'first_position', fixtures['Home Team'].map(ranking.set_index('Team')['Position']))
fixtures.insert(2, 'second_position', fixtures['Away Team'].map(ranking.set_index('Team')['Position']))
# 我们筛选出来在小组赛中的对阵情况
fixtures = fixtures.iloc[:48, :]
fixtures.head()output

根据排名的高低来重新修正参赛球队是作为主队还是客队,代码如下
# Loop to add teams to new prediction dataset based on the ranking position of each team
for index, row in fixtures.iterrows():
if row['first_position'] < row['second_position']:
pred_set.append({'home_team': row['Home Team'], 'away_team': row['Away Team'], 'winning_team': None})
else:
pred_set.append({'home_team': row['Away Team'], 'away_team': row['Home Team'], 'winning_team': None})
pred_set = pd.DataFrame(pred_set)
backup_pred_set = pred_set
pred_set.head()output
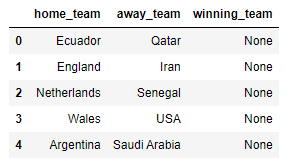
还是和之前一样的,我们需要对这些离散类型的变量进行编码,这里就不做演示了,我们调用训练好的模型并且进行比赛结果的预测,代码如下
# 小组赛对决的预测
predictions = logreg.predict(pred_set)
for i in range(fixtures.shape[0]):
print(backup_pred_set.iloc[i, 1] + " and " + backup_pred_set.iloc[i, 0])
if predictions[i] == 2:
print("Winner: " + backup_pred_set.iloc[i, 1])
elif predictions[i] == 1:
print("Draw")
elif predictions[i] == 0:
print("Winner: " + backup_pred_set.iloc[i, 0])
print('Probability of ' + backup_pred_set.iloc[i, 1] + ' winning: ', '%.3f'%(logreg.predict_proba(pred_set)[i][2]))
print('Probability of Draw: ', '%.3f'%(logreg.predict_proba(pred_set)[i][1]))
print('Probability of ' + backup_pred_set.iloc[i, 0] + ' winning: ', '%.3f'%(logreg.predict_proba(pred_set)[i][0]))
print("")output



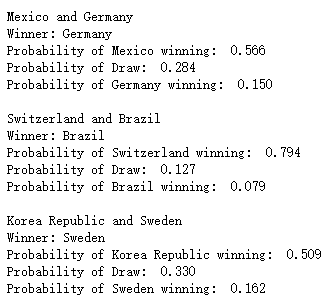
上述预测的结果针对的是2018年俄罗斯世界杯小组赛的对阵情况,那么2022年卡塔尔世界杯小组赛的预测,我们只需要将fixture数据集更新一下即可
fixtures = pd.read_csv("datasets/fifa-world-cup-2022.csv")
fixtures.head()output

最后预测出来的结果如下所示


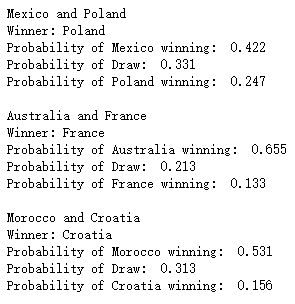

加载全部内容