Go数组与切片轻松掌握
Mingvvv 人气:1在 Go 中,数组和切片的功能其实是类似的,都是用来存储一种类型元素的集合。数组是固定长度的,而切片的长度是可以调整的
数组(array)
我们在声明一个数组的时候据必须要定义它的长度,并且不能修改。
数组的长度是其类型的一部分:比如,[2]int 和 [4]int 是两个不同的数组类型。
初始化数组
// 1. 创建一维数组
// 元素都是默认值
var arr1 [3]int
// 指定长度并设置初始值
var arr2 = [3]int{1, 2, 3}
var arr3 [3]int = [3]int{1, 2, 3}
// 自动推导数组长度
var arr4 = [...]int{1, 2, 3}
// 指定特定下标的元素的值,其他的为默认值
var arr5 = [3]int{1: 9}
// 2. 创建多维数组 与一维数组类似,不再赘述
var arr6 = [3][2]int{{1, 2}, {3, 4}, {5, 6}}
fmt.Println(arr1)
fmt.Println(arr2)
fmt.Println(arr3)
fmt.Println(arr4)
fmt.Println(arr5)
fmt.Println(arr6)------结果----------------------------
[0 0 0]
[1 2 3]
[1 2 3]
[1 2 3]
[0 9 0]
[[1 2] [3 4] [5 6]]
数组赋值
var arr = [3]int{1, 2, 3}
fmt.Println(arr)
arr[2] = 9
fmt.Println(arr)------结果----------------------------
[1 2 3]
[1 2 9]
遍历数组
方法一:for 循环遍历
var arr = [3]int{1, 2, 3}
for i := 0; i < len(arr); i++ {
fmt.Println(arr[i])
}------结果----------------------------
1
2
3
方法二:for range 循环遍历
使用 index 和 value 分别接收每次循环到的位置的下标和值
var arr = [3]int{1, 2, 3}
for index, value := range arr {
fmt.Printf("index:%d value:%d\n", index, value)
}------结果----------------------------
index:0 value:1
index:1 value:2
index:2 value:3
数组对比
数组比较的方法比较简单,使用 == 符号即可
var arr = [3]int{1, 2, 3}
var arr2 = [3]int{1, 2, 3}
fmt.Println(arr == arr2)
var arr3 = [...]int{1, 2, 3}
fmt.Println(arr == arr3)
var arr4 = [...]int{1, 2, 4}
fmt.Println(arr == arr4)------结果----------------------------
true
true
false
不能比较长度不同的数组类型,否则编译器会报错,如下:
var arr = [3]int{1, 2, 3}
var arr5 = [...]int{1, 2}
fmt.Println(arr == arr5)

切片(slice)
切片的性质
切片类型的定义
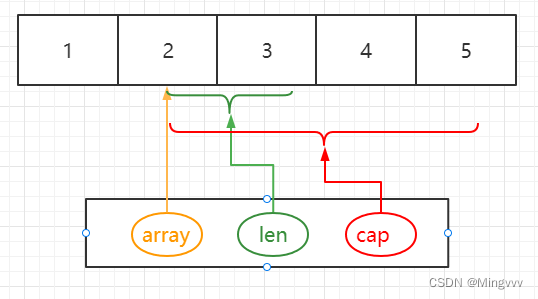
type slice struct {
array unsafe.Pointer //指向数组的指针
len int //切片的长度,可以理解为切片表示的元素的个数
cap int //容量,指针所指向的数组长度(从指针位置向后)
}切片的特性
- 切片是一个引用类型,是对数组的一个连续片段的引用
- 切片本身是一个结构体,通过值拷贝传递
- 切片的 cap 一定是大于等于 len 的
切片初始化
//直接声明并赋值
s0 := []int{1, 2, 3, 4, 5}
//通过数组或者切片获取
arr := [...]int{1, 2, 3, 4, 5}
s1 := s0[:] // 切片 s0 中的全部元素
s2 := s0[:2] // 切片 s0 第一个元素到第二个元素
s3 := arr[3:] // 数组 arr 从第四个元素开始向后的所有元素
s4 := arr[0:0] // 创建一个空切片
//通过 make(t Type, size ...IntegerType) 初始化,
//接受的第一个 int 表示切片长度,第二个表示容量大小。如果只有一个int参数则默认长度和容量是相同的
s5 := make([]int, 5) //创建一个长度为 5 切片,
s6 := make([]int, 5, 8) //创建一个长度为 5 容量为 8 的int型切片(长度为5的部分会被初始化为默认值)
fmt.Println(s0, s1, s2, s3, s4, s5 ,s6)-------结果-----------------------------------
[1 2 3 4 5] [1 2 3 4 5] [1 2] [4 5] [] [0 0 0 0 0] [0 0 0 0 0]
切片赋值
和数组相同根据 index 赋值
//直接声明并赋值
s0 := []int{1, 2, 3, 4, 5}
fmt.Println(s0)
s0[0] = 999
fmt.Println(s0)-------结果-----------------------------------
[1 2 3 4 5]
[999 2 3 4 5]
切片的容量
我们可以通过 len(slice) 获取一个切片的长度,可以通过 cap(slice) 获取一个切片的容量。
容量:指针所指向的数组长度(从指针位置向后),如何理解 从指针位置向后 这个意思,通过代码观察:
s0 := []int{1, 2, 3, 4, 5}
s1 := s0[1:3] //第二个元素到第三个元素
fmt.Printf("len: %d\n", len(s1))
fmt.Printf("cap: %d\n", cap(s1))
fmt.Println(s1 )------结果---------------
len: 2
cap: 4
[2 3]
如上,s1 实际指向的数组是 s0 的数组的一个连续片段。
所有我们可以使用 cap 把切片 s1 指向的数组(指针向后,包含指针)的去拿不元素都获取到:
s0 := []int{1, 2, 3, 4, 5}
s1 := s0[1:3]
s2 := s1[:cap(s1)]
fmt.Printf("len: %d\n", len(s2))
fmt.Printf("cap: %d\n", cap(s2))
fmt.Println(s2)-------结果------------
len: 4
cap: 4
[2 3 4 5]
append以及扩容
append 可以动态地向切片中追加元素
s0 := []int{1, 2, 3, 4, 5}
s0 = append(s0, 6, 7, 8, 9, 10) //追加元素
fmt.Printf("len: %d\n", len(s0))
fmt.Printf("cap: %d\n", cap(s0))
fmt.Println(s0)
s1 := []int{11, 12, 13, 14, 15}
s0 = append(s0, s1...) //追加切片,切片需要解包
fmt.Printf("len: %d\n", len(s0))
fmt.Printf("cap: %d\n", cap(s0))
fmt.Println(s0)
len: 10
cap: 10
[1 2 3 4 5 6 7 8 9 10]
len: 15
cap: 20
[1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
我们可以发现,在第二次和第三次追加元素的时候,切片的容量发生了变化,两次都是扩充为之前容量的两倍。
但是一定都是两倍扩容吗?事实上不是的,如以下代码:
s0 := make([]int, 1000)
fmt.Printf("len: %d, cap: %d\n", len(s0), cap(s0))
s0 = append(s0, make([]int, 200)...)
fmt.Printf("len: %d, cap: %d\n", len(s0), cap(s0))
s0 = append(s0, make([]int, 400)...)
fmt.Printf("len: %d, cap: %d\n", len(s0), cap(s0))
-----结果--------------------------
len: 1000, cap: 1000
len: 1200, cap: 1536
len: 1600, cap: 2304
可以发现第一次扩容后,容量变为 1536,第二次扩容后容量又变成了 2304,并不是什么两倍的关系。
通过查看 append 源码中的容量计算部分
func growslice(et *_type, old slice, cap int) slice {
...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256
if old.cap < threshold {
newcap = doublecap //小容量直接扩容到两倍容量
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
//大容量取消了 1.25 倍扩容,选择了一个更为平滑的扩容方案
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For goarch.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == goarch.PtrSize:
lenmem = uintptr(old.len) * goarch.PtrSize
newlenmem = uintptr(cap) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if goarch.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
...
return slice{p, old.len, newcap}
}从源码中可以得知:
- 当需要的容量大于两倍旧切片的容量时,需要的容量
- 就是新容量当需要的容量小于两倍旧切片的容量时, 判断是否旧切片的长度, 如果小于 256 , 那么新的容量就是两倍旧的容量,当大于等于 256 时, 会选择一个过度算法 newcap += (newcap + 3*256) / 4 不断增加,直至大于等于需要的容量
- 特殊的一点是,后面的 capmem = roundupsize(uintptr(newcap) * et.size) 这个方法,做了内存对齐,导致最后算出的容量大于等于推算出来的容量,至于内存对齐都做了哪些操作,还有待研究。
加载全部内容