mysql如何让左模糊查询也能走索引
绅士jiejie 人气:0让左模糊查询也能走索引
测试表USER_INFO表数据以及结构如下
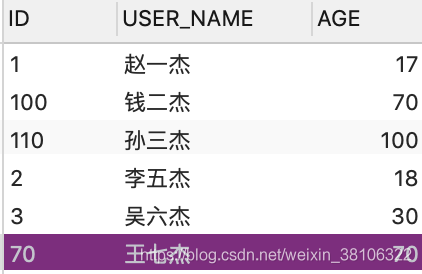
有一个USER_NAME字段的索引

有个业务需求,需要模糊搜索出用户名后几位有杰这个词的所有用户信息,这时候不可能说为了一个搜索就引入ES,但是如果sql使用左模糊查询的话,根据索引的最左匹配原则,该sql语句是不可能使用到idx_user_name索引的,如下:
EXPLAIN SELECT * from USER_INFO where USER_NAME like '%杰'
执行计划如下:

可以发现是用不到索引的。
需要做模糊匹配,又要用到索引,索引的最左匹配原则更是不能被打破,这时候可以增加一个字段,这个字段的内容等于USER_NAME字段内容的反转,同时加上这个字段的相关索引,如下:
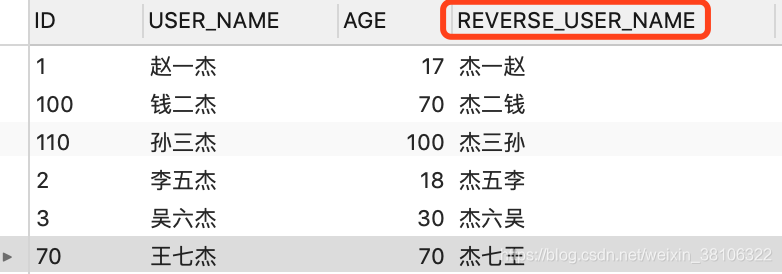

此时如果是要模糊搜索出用户名后几位有杰这个词的所有用户信息,可以对REVERSE_USER_NAME字段做右模糊查询,效果其实就是和对USER_NAME字段做左模糊查询是一样的,因为二者的内容是相反的,结果如下:
SELECT * from USER_INFO where REVERSE_USER_NAME like '杰%'
执行计划如下:

小结一下:索引的最左匹配原则不能打破,那么要让左匹配也走索引的话,换个思路,让右匹配的效果和左匹配一样就好了,同时右匹配又能走索引,间接达到了左模糊查询也能走索引的目的。
模糊查询(like、instr)
SQL中经常会遇到模糊查询,现在模糊查询正常、最常用的有两种,一种是like、另一种是instr,这两种单单是简单的搜索,instr的效率是比like要高的(这也得看%在哪儿了)。
1. like
like中分右模糊、左模糊,右模糊比如’abc%‘时,扫描索引,高效。当模糊查询含左模糊时,比如’%abc’,进行全表扫描,低效。当然更别提’%abc%'了。
2. instr
instr(字段名, string),instr的使用也很简单,就是填写一下字段名,然后与后面需要查找的内容相关。这个比like的左模糊效率要高,但是要比右模糊还是相差不多的(因为在instr不分左右模糊)。
3. A>=’’ and A<’’
今天在搜索查找之时还找到了这么一个查找方法,这个方法要比上面的instr效率还要高,不过这个方法局限性还是比较高的。例如:
select * from formtable_main_200_dt1 where hth >= '16040610' and hth < '16040611'
这个方法只适用于字符型字段,且除了我们想要的字段外,还得加上一个超过此类型的,并且他只支持右模糊。但是在这几个当中就右模糊而言,他的效率是最高的。
3的补充讲解
在数据中进行字符的比较时发现自己并不是对此了解,这里记下这里字符的比较是比较的哪里。
这里的比较是比较的ASCII,但这不是比较的总的ASCII,而是一个字符一个字符的比较,例如我这里有数据库的字段为’123456123’,而要比较的还有’123456223’,这里进行比较,当到了61的1和62的2时就可以比较出大小了。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容